Redis Partitioning即Redis分区,简单的说就是将数据分布到不同的redis实例中,因此对于每个redis实例所存储的内容仅仅是所有内容的一个子集。分区不仅仅是Redis中的概念,几乎是所有数据存储系统都会涉及到的概念。
我们为什么要分区?
通常来说,分区的好处大致有如下两个方面:
1. 性能的提升,单机 Redis 的网络IO能力和计算资源是有限的,将请求分散到多台机器,充分利用多台服务器的计算能力和网络带宽,有助于提高 Redis 总体的服务能力。
2. 存储的横向发展,即使 Redis 的服务能力能够满足应用需求,但是随着存储数据的增加,单台机器受限于机器本身的存储容量,将数据分散到多台机器上存储使得 Redis 服务可以横向发展。
总体来说,分区使得我们本来受限于单台计算机硬件资源的问题不再是问题,我们都可以通过增加机器来解决问题。
Redis 分区基础
实际应用中有很多分区的具体策略,假设我们已经有了一组四个 Redis 实例分别为 R0、R1、R2、R3 ,另外我们有一批代表用户的键,如:user:1,user:2,user:3,,,等,其中“user:”后面的数字代表的是用户的 ID,我们要做的事情是把这些键分散存储在这四个不同的 Redis 实例上。怎么做呢?最简单的一种方式是范围分区。
范围分区
所谓范围分区,就是将一个范围内的 key 都映射到同一个 Redis 实例中,如 ID 从 1 - 100 的用户数据映射到 R0 等,这种方法简单,但是在实际中还是很有效的,不过还是有问题:

- 我们需要一张表,这张表用来存储用户 ID 范围到 Redis 实例的映射关系,如用户 ID 0 - 100 的映射到 R0 实例,,,
- 我们不仅需要对这张表进行维护,而且对每种对象类型我们都需要一个这样的表,如我们当前存储的是用户信息,如果存储的是订单信息,我们就需要再建一张映射关系表。
- 如果我们想要存储的数据的 key 并不能按照范围划分怎么办,如我们的 key 是随机生成的 id,这个时候就不好用范围划分了。
哈希分区
哈希分区跟范围分区相比一个明显的优点是哈希分区适合任何形式的 key,而不像范围分区一样需要 key 的形式为
object_name:<id>,而且分区方法很简单: id = hash(key)%N;
其中 id 代表 Redis 实例的编号,公式描述的是首先根据 key 和一个 hash 函数计算出一个数值型的值,接着上面的例子,我们的第一个要处理的 key 是user:1,hash(user:1)后得到的结果对一个数取余,这样根据得到的取余结果,我们就知道这个key 要映射到哪个 Redis 实例上了。
不同的分区实现
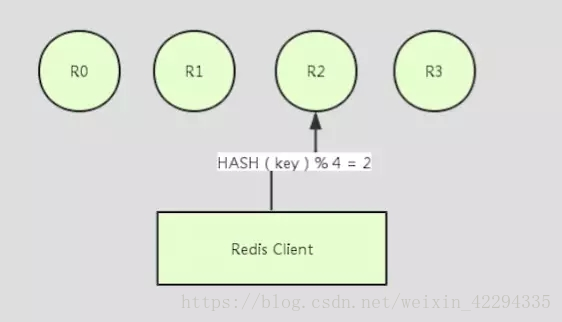
客户端实现
客户端实现即 key 在 Redis 客户端就决定了要被存储在哪台 Redis 实例中:
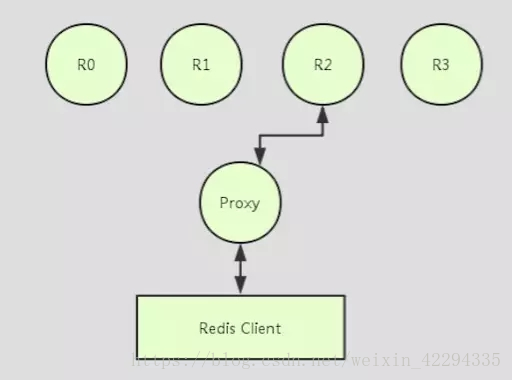
代理实现
代理实现即客户端将请求发往代理服务器,代理服务器实现了 Redis 协议,因此代理可以代理客户端和 Redis 服务器通信。代理服务器通过配置的分区 schema 来将客户端的请求转发到正确的 Redis 实例中,同时将反馈消息返回给客户端:
查询路由
查询路由是 Redis Cluster 实现的一种 Redis 分区方式:

查询路由的过程中,我们可以将查询请求随机的发送到任意一个 Redis 实例,这个 Redis 实例负责将请求转发至正确的 Redis 实例中。Redis 集群实现了一个通过和客户端协作的 hybrid 来做查询路由。
Redis分区的缺点
- 多键操作是不被支持的,如我们将要批量操作的键被映射到了不同的 Redis 实例中。
- 多键的 Redis 事务是不被支持的。
- 分区的最小粒度是键,因此我们不能将关联到一个键的很大的数据集映射到不同的实例。
- 当应用分区的时候,数据处理是非常复杂的,如我们需要处理多个 rdb/aof 文件,将分布在不同实例的文件聚集到一起备份。
- 添加和删除机器是很复杂的,如 Redis 集群支持几乎运行时透明的因为增加或减少机器而需要做的 rebalancing,然而像客户端和代理分区这种方式是不支持这种功能的。
这时就应该使用 Pre-sharding。
Pre-sharding
通过上面的介绍,我们知道 Redis 分区应用起来是有问题的,除非我们只是使用 Redis 当作缓存,否则对于增加机器或删除机器是非常麻烦的。
然而,通常我们 Redis 容量变动在实际应用中是非常常见的,如我们需要 10 台 Redis 机器,明天可能就需要 50 台机器。
鉴于 Redis 是很轻量级的服务(每个实例仅占 1 M ),对于上面的问题一种简单的解决办法就是:
我们可以开启多个 Redis 实例,尽管是一台物理机器,我们在刚开始的时候也可以开启多个实例,我们可以从中选择一些实例,如 32 或者 64 个实例来作为我们的工作集群。当一台物理机器存储不够的时候,我们可以将一般的实例移动到我们的第二台物理机上,以此类推,我们可以保证集群中Redis的实例数不变,又可以达到扩充机器的目的。
怎么移动 Redis 实例呢?当需要将 Redis 实例移动到独立的机器上的时候,我们可以通过下面的步骤实现:
1. 在新的物理机上启动一个新的 Redis 实例。
2. 将新的物理机作为要移动的那台的 slave 机器。
3. 停止客户端。
4. 更新将要被移动的那台 Redis 实例的 IP 地址。
5. 对于 slave 机器发送 SLAVEOF ON ONE 命令。
6. 使用新的 IP 启动 Redis 客户端。
7. 关闭不再使用的那个 Redis 实例。