归一化normalization:
标准化standardization: 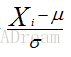
两者本质都是一种线性变换
区别是归一化仅有极值决定,将数据压缩到【0,1】范围内,而标准化则是动态的,弹性的,和样本的整体分布有关
这两种归一化的应用场景分别是怎么样的呢?什么时候第一种方法比较好、什么时候第二种方法比较好呢?
对输出结果范围有要求,用归一化。
数据结果稳定,不存在极端的最大值最小值用归一化
存在较多异常值和较多噪音用标准化。
在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,标准化表现更好。
在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用归一化,比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。
使用第一种方法(线性变换后),其协方差产生了倍数值的缩放,因此这种方式无法消除量纲对方差、协方差的影响,对PCA分析影响巨大;同时,由于量纲的存在,使用不同的量纲、距离的计算结果会不同。
而在标准化方法中,新的数据由于对方差进行了归一化,这时候每个维度的量纲其实已经等价了,每个维度都服从均值为0、方差1的正态分布,在计算距离的时候,每个维度都是去量纲化的,避免了不同量纲的选取对距离计算产生的巨大影响。
总结来说,在算法、后续计算中涉及距离度量(聚类分析)或者协方差分析(PCA、LDA等)的,同时数据分布可以近似为状态分布,应当使用0均值的标准化方法。其他应用中更具需要选用合适的归一化方法。
哪些算法需要归一化:
概率模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率。像svm因为涉及到距离的计算,要消除量纲的影响、线性回归则是因为采用梯度下降法,为了加快收敛速度就需要归一化,而决策树模型属于概率模型,不关心变量的值,只关心之间的关系,则不需要进行归一化。
归一化的好处:
归一化消除了量纲,避免了量纲对距离计算的影响,同时也可以加快梯度下降求最优解的速度,并且有可能提高精度,因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛,归一化也是提升算法应用能力的必备能力之一。
树模型不需要归一化:
数值缩放并不影响分裂点的位置,对特征值进行排序的顺序不变的,那么所属的分支以及分裂点就不会变。并且树模型是不能进行梯度下降 的,因为树模型是阶跃的,不可导,所以树模型通过寻找最优分裂点来完成寻找最优点的过程。
LR需要归一化吗:
LR损失函数通过调整权重可以使得损失函数不变,因此应该不需要进行归一化,但实际中因为采用了梯度下降法,为了加快模型的收敛速度,提高精度而进行数据的归一化