有两个表
promotion_full_reduction
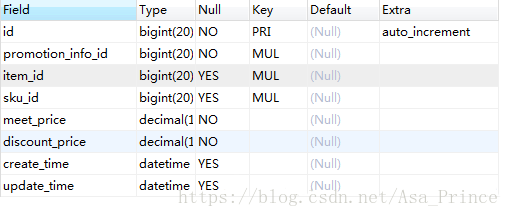
base_user_favorite_item
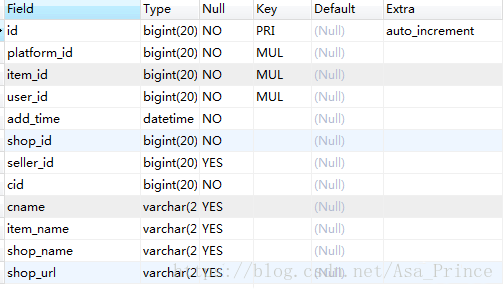
现在要查询用户收藏的商品中参加促销了的商品个数,有两种写法,一种是使用in子查询:
SELECT
COUNT(1)
FROM
promotion_full_reduction fr
WHERE
fr.item_id IN (
SELECT
ufi.item_id
FROM
base_user_favorite_item ufi
WHERE
ufi.platform_id = 222
AND ufi.user_id = 111
)使用 explain 查看mysql执行计划:

此sql以promotion_full_reduction 为驱动表,虽然执行计划显示走了索引,但是由于外层查询没有where条件(因为子查询还未执行),结果就是将promotion_full_reduction 全表数据都扫描了出来load到了内存,然后进行nested loop,循环执行子查询,根据子查询结果对外层查询结果进行过滤,总共要循环99次(子查询到底是读99次磁盘还是只读一次这个我不确定,希望了解的人解释一下)。
再看使用两表关联进行查询:
SELECT
count(1)
FROM
promotion_full_reduction pr
JOIN base_user_favorite_item bi ON pr.item_id = bi.item_id
WHERE
bi.user_id = 111
AND bi.platform_id = 2222使用 explain 查看mysql执行计划:

执行计划显示mysql选择了 base_user_favorite_item 作为驱动表,由于带有where条件,驱动表查询出来的结果只有两条,显然磁盘io次数少了,nested loop循环次数也降了下来。
结论:不要轻易使用in子查询,由于in子查询总是以外层查询的table作为驱动表,所以如果想用in子查询的话,一定要将外层查询的结果集降下来,降低io次数,降低nested loop循环次数,即:永远用小结果集驱动大的结果集。