使用sklearn训练模型,只能输入数值型变量。因此需要对数据集中的非数值型离散变量进行处理,非数值型离散变量分为两类:有序型与无序型

一、有序型离散变量处理
什么叫有序型离散变量呢,比如说衣服尺码,M、L、XL;学历:小学、初中、高中、本科;这些都属于有序型变量。
在上图数据表格中,size及classlabel则为有序型变量,自定义有序型字典表,进行相关映射即可:
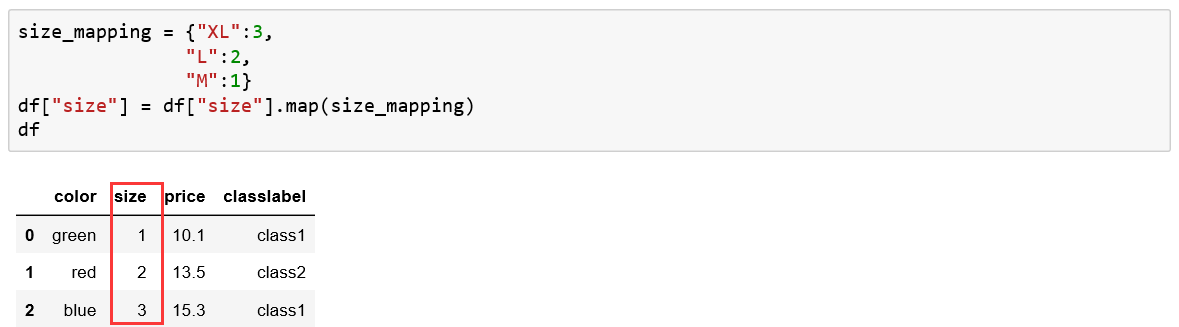
二、无序型离散变量处理
衣服的颜色,风向、人员类别这些都属于无序型变量,如果转换成有序型数值代入模型会对建模结果造成影响,因此对于无序型变量需要做独热编码或者哑变量处理
(1)独热编码
独热编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。 独热编码是分类变量作为二进制向量的表示,这首先要求将分类值映射到整数值,然后再将每个整数值表示为二进制向量。
具体操作如下:首先将无序型变量color利用LabelEncoder()方法映射为数值
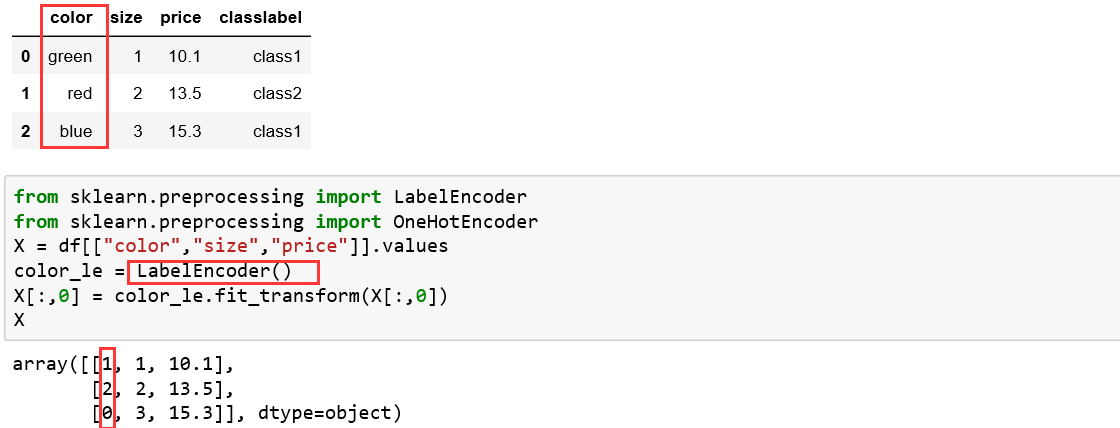
再将整数型数值进行独热编码

(2)哑变量处理
在模型中引入多个虚拟变量时,虚拟变量的个数应按下列原则确定: 如果有m种互斥的属性类型,在模型中引入(m-1)个虚拟变量。 例如,性别有2个互斥的属性,引用2-1=1个虚拟变量;再如,文化程度分小学、初中、高中、大学、研究生5类,引用4个虚拟变量。
pandas中的get_dummies方法来创建哑特征,get_dummies默认会对DataFrame中所有字符串类型的列进行独热编码:

在实际特征工程处理过程中,使用LabelEncoder()+OneHotEncoder()方式,sklearn能够将训练集属性记录,并可以采用transform()方法直接作用于待加入模型的测试集。