背景
最近项目使用了dubbo实现服务化架构,职能化拆分模块。比如主业务模块不会耦合基础数据的sql,这种划分造成了一个请求调用很多次后端服务,其中有些服务频次会比较多的现象。
当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位服务故障点,以对症下药。
对于快速问题定位,单机情况下是这样的:
1.从下到下关键节点的日志,入参,出差,异常等。
2.关键节点的响应时间
3.关键节点依赖关系
但到了分布式环境,可能会出现:
1. 每个系统的技术栈不同
2.有的系统有日志有的连日志都没有
3.日志实现手段不相同
所以想看整体的调用链非常困难。
开源跟踪链项目zipkin
推特的一个产品,通过API收集各系统的调用链信息然后做数据分析,展示调用链数据。 在dubbo中引入zipkin是非常方便的,主要就是写filter,在请求处理前后发送日志数据,让zipkin生成调用链数据。 大致满足分布式系统调用跟踪系统基本的特性:低侵入性,高性能,高可用容错,低丢失率
工作原理
创造一些追踪标识符(tracingId,spanId,parentId),最终将一个request的流程树构建出来
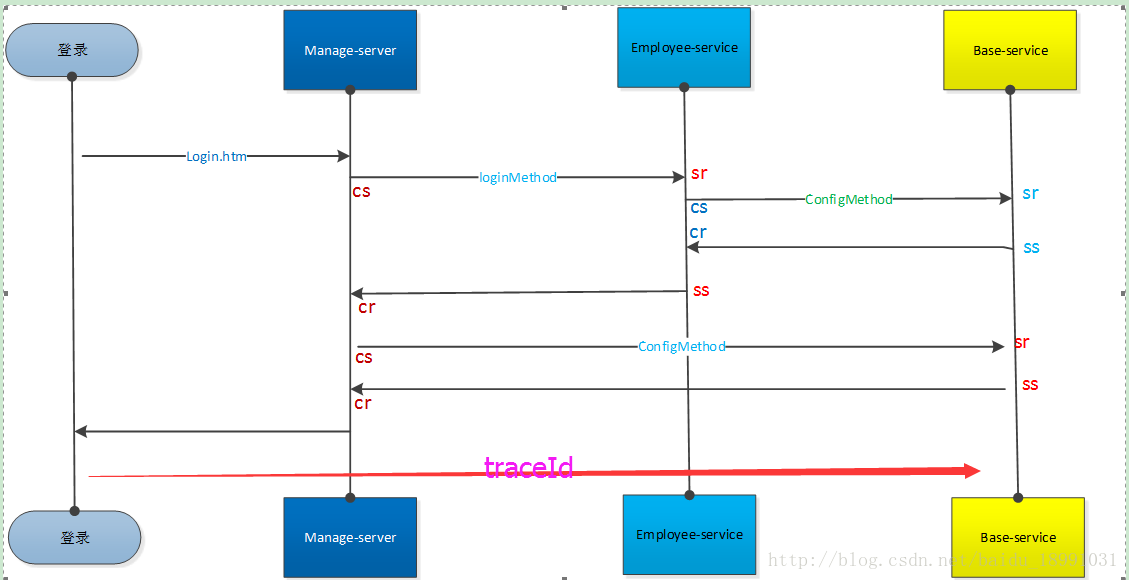
traceId:
就是一个全局的跟踪ID,是跟踪的入口点,根据需求来决定在哪生成traceId。比如一个http请求,首先入口是web应用,一般看完整的调用链这里自然是traceId生成的起点,结束点在web请求返回点。
spanId:
这是下一层的请求跟踪ID,这个也根据自己的需求,比如认为一次rpc,一次sql执行等都可以是一个span。一个traceId包含一个以上的spanId。
parentId : 上一次请求跟踪ID,用来将前后的请求串联起来。
Cs: 客户端发起请求的时间,比如dubbo调用端开始执行远程调用之前。
Cr: 客户端收到处理完请求的时间。
Ss: 服务端处理完逻辑的时间。
Sr: 服务端收到调用端请求的时间。
客户端调用时间=cr-cs
服务端处理时间=sr-ss
网络延迟= sr-cs
zipkin接收存储架构
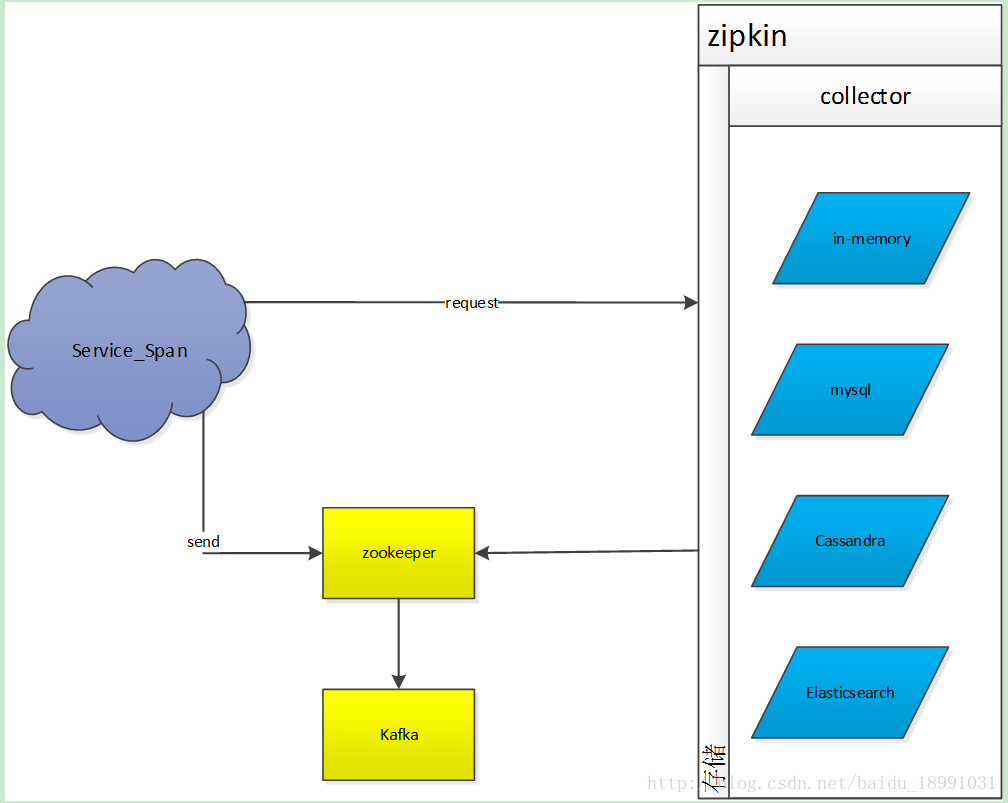
Collector:
1. http推送
2. Kafka分布式发布订阅消息系统 推送消费
Storage:
in-memory(默认)
仅用于测试,因为采集数据不会持久化
默认使用这个存储,若要使用其他存储,查看:
JDBC (mysql)
如果采集数据量很大的话,查询速度会比较慢
Cassandra
zipkin最初始内建的存储(扩展性好、schema灵活)
Elasticsearch(建议使用)
被设计用于大规模
存储形式为json