如果一个url比较完整,包括querystring部分(就是get请求查询字符串部分),hash部分
http://127.0.0.1:3000/b。html?id=1523#123 #123叫做hash部分
也就是说querystring输入req.url,但是hash不属于。
但是我们此时要得到文件名的部分,我不想要querystring,此时可以用正则提炼,但是太麻烦
此时node中提供了内置模块:url 。path 模块
node.js
http://nodejs.cn/api/url.html#url_url_parse_urlstring_parsequerystring_slashesdenotehost
url.parse() 方法会解析一个 URL 字符串并返回一个 URL 对象。
现在没有正确的是被protocol协议,host主机名等,因为我们是window主机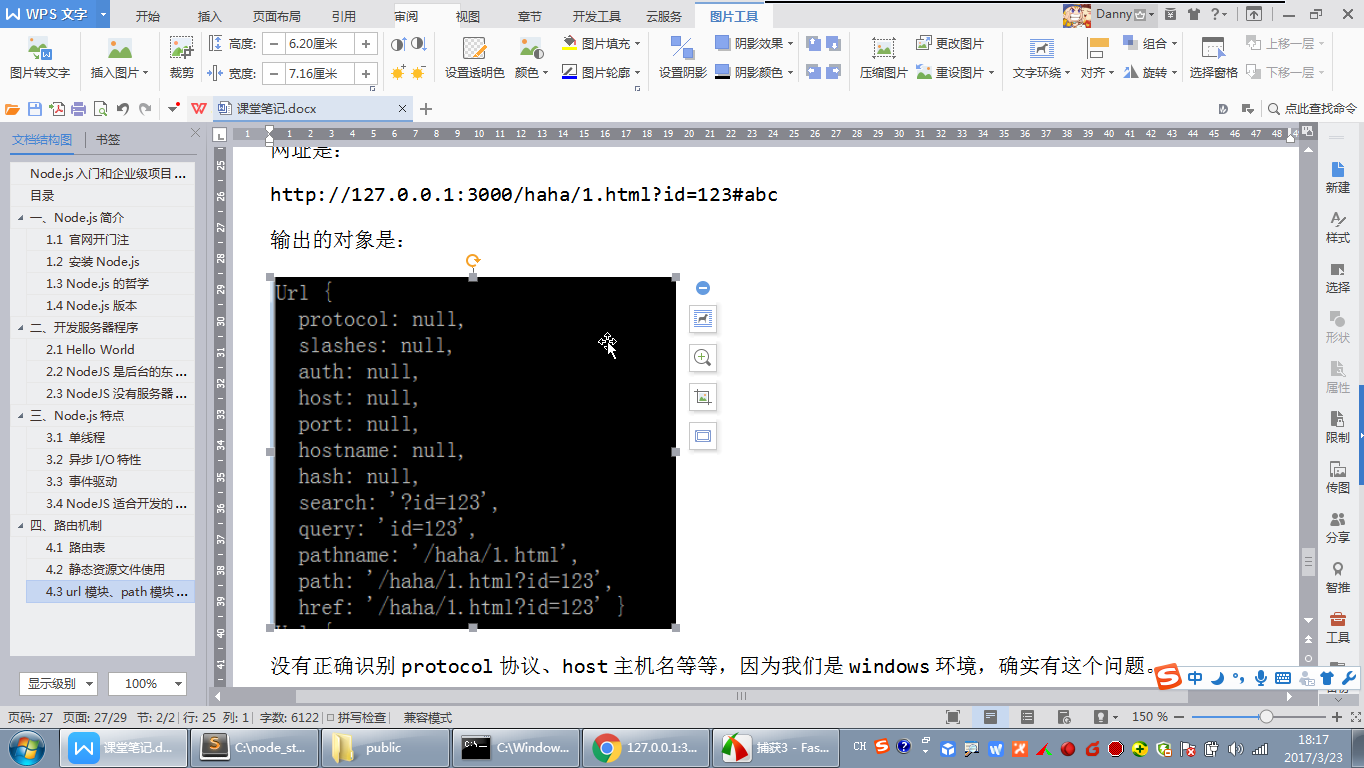
当我们设置 url。pase(req。url,true)当我们在这里加上true 的时候,我们发现query由于原来的字符串变成了一个对象,非常的好用
nodejs的内置对象非常好用,上卖弄都没有区别就是query有区别
query非常智能,如果url。parse(req,url,true),非常的好用,方便我们存入到数据库,
path模块,pathname常用的一个功能就是能够是被拓展名,这样就会输出路径 拓展名,path我们也只学一个方法
如果之前的哪个地方不加true ,那么现在就是获得的查询字符串,
var qusting=reqyure(“querystring”) 只是一个内置对象,可以将字符串转为对象
现在确实已经是对象了
还有两个模块:querystring path 他们都是服务于url的,一图胜过千言万语
hash永远拿不到,因为hash不属于url,没用,hash是高前端的用的,比如ajax有一些毛病,不是没有回退功能吗。这个就是做
这么用的,
url。pase() 这样req.url就是一个对象了, query 是我们的请求值,我们可以设true 拿到query ,将它变成对象
path。extname处理pathname ,拿到后缀, querystring是将其query变成对象