参考自:https://blog.csdn.net/jinping_shi/article/details/52433975
https://www.cnblogs.com/weizc/p/5778678.html
问题描述
一般而言,监督学习的目标函数是:
第一项衡量模型预测值与真实值的误差,即拟合情况。第二项是对参数
的规则化函数
来做模型的复杂度约束。
正则化
机器学习中损失函数后面经常会跟一个L1或者L2正则函数,也称L1/L2范数。
0、L0范数:
指权值向量中非0的元素个数。
1、L1范数:
指权值向量中各个元素的绝对值纸盒,表示为
注:由于L0范数很难优化求解(NP难问题)和L1范数是L0范数的最优凸近似,从而一般只考虑L1而不考虑L2范数。
2、L2范数:
指权值向量中各个元素平方和后开根,表示为
作用
L0范数和L1范数倾向于的分量尽量稀疏,即非零分量个数尽量少。
L2范数倾向于的分量取值尽量均衡,即非零分量个数尽量稠密。
1、L0/L1范数
(1)特征选择
大家对稀疏规则化趋之若鹜的一个关键原因在于它能实现特征的自动选择。稀疏规则化算子的引入就是为了完成特征自动选择的光荣使命,它会学习地去掉这些没有信息的特征,也就是把这些特征对应的权重置为0。
(2)可解释性
另一个青睐于稀疏的理由是,模型更容易解释。例如要确定患某种病的概率,然后我们收集到的数据是1000维的,也就是我们需要寻找这1000种因素到底是怎么影响患上这种病的概率的。通过学习,如果最后学习到的w*就只有很少的非零元素,例如只有5个非零的元素,那么我们就有理由相信,这些对应的特征在患病分析上面提供的信息是巨大的,决策性的。
2、L2范数
除了L1范数,还有一种更受宠幸的规则化范数是L2范数。
它有两个美称,在回归里面,有人把有它的回归叫“岭回归”(Ridge Regression),有人也叫它“权值衰减weight decay”。这用的很多吧,因为它的强大功效是改善机器学习里面一个非常重要的问题:过拟合。
直观解释
1、L1范数
假设有带L1正则化的损失函数:
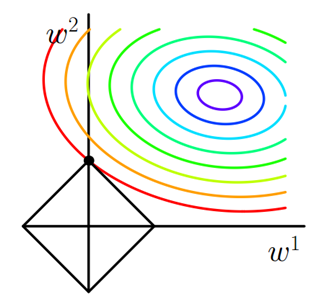
图中彩色线是的等值线,黑色方形是L函数的图形。当
与
图形首次相交的地方就是最优解。当
函数高维时,
图形是一个高维的锥形,有多个尖角,
与这些尖角接触的几率圆圆大于与
其他部位接触的几率。从而L1范数可以产生稀疏模型,进而用于特征选择。
2、L2范数
假设带L2正则化的损失函数:
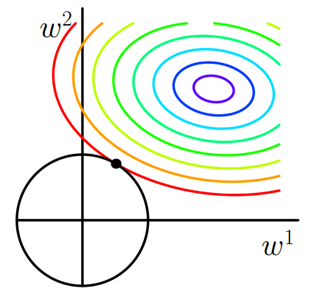
以二维空间为例,L2正则化的函数图形是个圆,因此与
相交时使得
或
等于零的机率小了许多,这就是为什么L2正则化不具有稀疏性的原因。