索引(index)是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。——百度百科
正常的一张表,是无序,如果要进行查询(select)操作,理论上会将表中所有记录进行遍历。并且每次查询都需要从第一条到最后一条挨个查找,以防查漏。这样显然是低效的。
为了解决这个问题,引入了索引的概念。索引是将记录按照某个关键字段(key)进行排序,因此,索引的存在是为了便于检索,使得检索查询更加的快速、高效。
0 索引的基本指令
| 操作 | 命令 |
|---|---|
| 创建索引 | CREATE[UNIQUE] INDEX 索引名 ON 表名(列名 [,列名]); |
| 查看索引 | SHOW INDEX FROM 表名; |
| 删除索引 | DROP INDEX 索引名 ON 表名; |
| 查看索引使用情况 | EXPLAIN SELECT ...; |
1 索引的结构
最常用的一种保存索引的结构是B树(Balanced Tree,平衡树),是一种像枝叶扩散的树状结构。
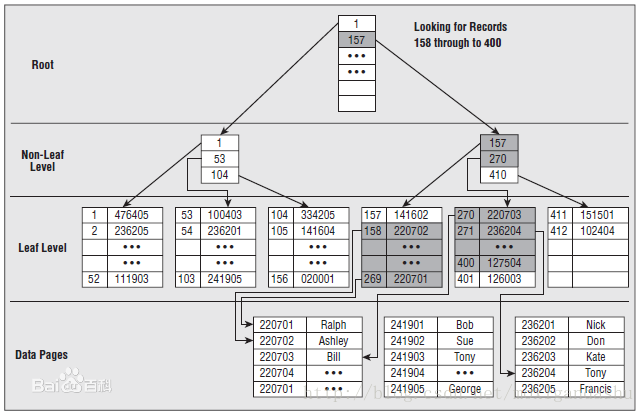
通过这样的树状结构,原本需要遍历所有的记录,进行n次查询,现在最多只要
2 索引操作指令
2.1 创建索引CREATE INDEX
创建索引的代码为:
CREATE INDEX 索引名 ON 表名(列名);2.2 查看索引show
查看索引代码:
SHOW INDEX FROM 表名;2.3 删除索引DROP INDEX
删除索引的代码:
DROP INDEX 索引名 ON 表名;eg:为表employee的lname_pinyin创建一个索引:
>CREATE INDEX idx_lpy ON employee(lname_pinyin);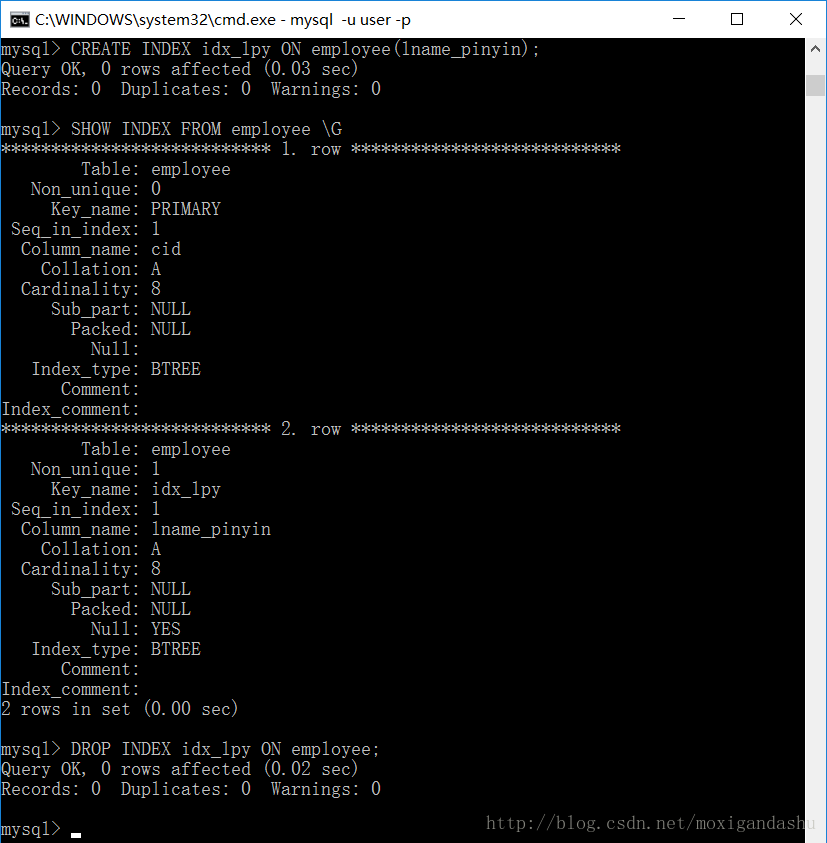
2.4 创建多列复合索引
eg:为表employee的lname_pinyin,fname_pinyin创建一个复合索引:
>CREATE INDEX idx_lpy ON employee(lname_pinyin,fname_pinyin);2.5 创建唯一性索引
如果对index制定了UNIQUE关键字,则表示创建了不可重复的索引。
如为表employee的fname创建一个唯一性索引:
>CREATE UNIQUE INDEX idx_lpy ON employee(fname);当创建了唯一性索引,插入和该列相同的记录,系统会报错。
如果已有数据重复,创建唯一性索引也会报错
但是,如果创建了一个复合的唯一性索引,则只要两列不完全相同,数据可以成功插入
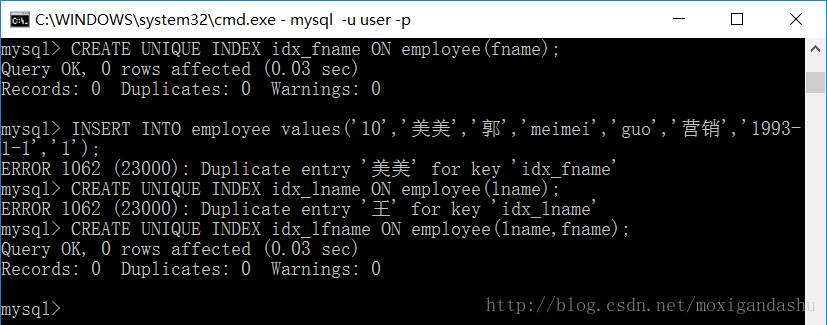
如图,创建了以fname为关键字的索引,“郭美美”就无法插入,系统会提示报错。
创建以lname为关键字的索引,由于lname有重复数据,所以也无法创建该索引。
而如果创建一个复合索引,以fname和lname,则创建成功。
2.6 分析索引优势
通过EXPLAIN可以确认索引的使用情况;
>EXPLAIN SELECT ...;eg:查看检索查询lname_pinyin的情况;
然后删除索引,再次查看检索查询name_pinyin 的情况:
>EXPALIN SELECT * FROM employee WHERE lname_pinyin='wang'\G
...
>DROP INDEX idx_pinyin ON employee;
...
>EXPALIN SELECT * FROM employee WHERE lname_pinyin='wang'\G
>...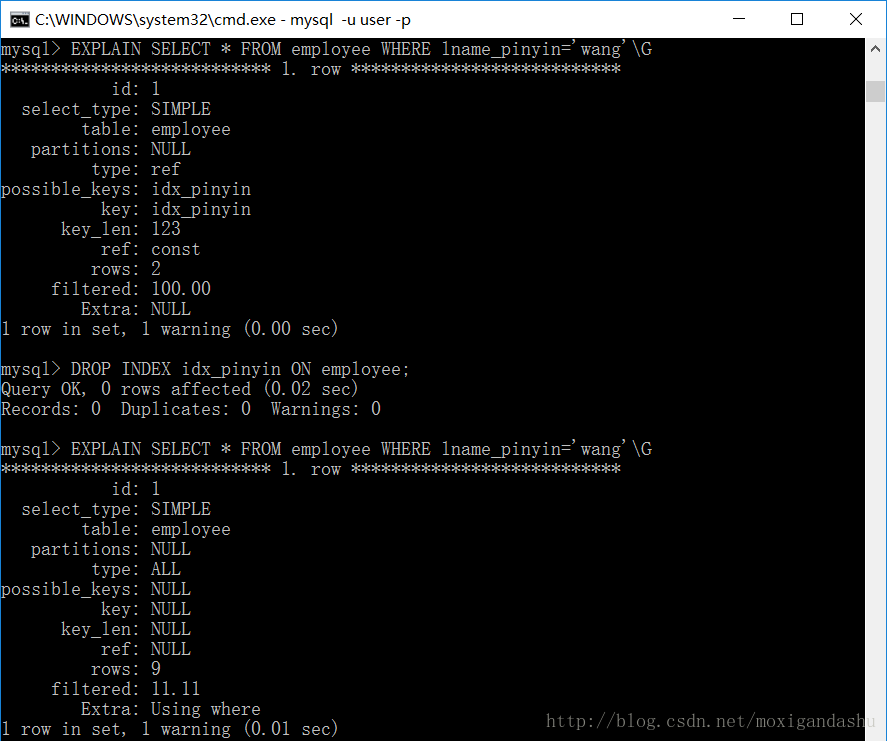
我们可以看到,当建立索引时,遍历次数为2;而当删除索引后,遍历次数为9,和表中记录数相同。
因此,回到之前所讲:
索引可以大大提高检索的效率。