前言:
http产生背景:
http诞生之初主要用于web端内容获取。早期的http设计思想很简单,从http/0.9-1.x均在描述一个http请求的实现过程。早期的web页面内容较少,与用户的交互并不多,所以http可以较好的完成需求。但是随着技术的发展也业务量的提升,如今的网页内容更加丰富,排版更加精致,并且充斥着大量的用户交互。http协议带来了较大的性能瓶颈。其中广受人诟病的两点是:
1、http连接无法复用:http请求是无连接的。也就是说,连接状态是由传输层控制的,http本身的request和response是一对一的。http1.0 到http1.1的改进在于一个tcp连接是否可以对应多个http请求。
- http/1.0: 一个tcp连接对应一个http请求。每一次发http请求,都要经历三次握手的过程,很耗时。
- http/1.1: 一个tcp连接可以处理多个http请求。打开一个tcp连接之后,当一次http请求完成,不会关闭这个tcp链接。除非显示的标注connection:closed。这也是keep-alive技术,虽然tcp链接可复用了。但是http的请求的处理依旧是串行的。即处理完请求A之后才能处理请求B。这种串行就造成了性能瓶颈。
2、head of line blocking:问题的原因依旧是http的“无连接”。虽然在1.1版本的时候多个http请求可以复用一个tcp链接,但是http请求之间是串行的。那么如果前面的http请求被阻塞掉,或者很耗时,或者任意原因造成前面的请求没有处理完,那么http 请求队列之后的http请求均被阻塞了。
因此,在http/1.x的时代,要实现并发必须在tcp的级别上实现。但是客户端是依据域名来向服务器建立连接,一般PC端浏览器会针对单个域名的server同时建立6~8个连接,手机端的连接数则一般控制在4~6个。显然连接数并不是越多越好,资源开销和整体延迟都会随之增大。
SPDY:http/2 的前身
为了解决http/1.x这些问题,google公司开发了一个实验性的协议SPDY,并设计了http/2种的核心技术
http/2:
根据前面的分析可知,http/2 的提出就是为了解决http1.x中的性能瓶颈,并且保证安全性而提出的。
http/2的设计目标:
- 页面加载时间(PLT)省电50%
- 无需网站作者修改任何内容
- 将部署复杂性降到最低,无需变更网络基础设施

二进制分帧层是属于应用层HTTP2层的一个“中间层”。由于http2是二进制协议。而原来的http1.x头信息是肯定是文本的,数据体部分可以是文本,也可以是二进制。所以二进制分帧层做的一个重要操作,就是将原来的文本,转为二进制的帧。
帧的结构:
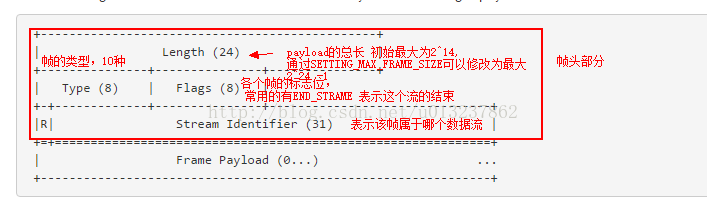
根据type类型的不同,frame payload有不同的结构。
正常的通信主要有两类重要的帧: HEADERS frame 和 DATA frame
HEADERS(type = 0000001B) frame: 用于打开一个数据流,并在附加额外的,或者变化了的头部信息

DATA (type = 00000000B):请求或者响应的正文部分。传递该流相关的二进制,可变长的字节序列。一个或者多个DATA frame会被用到。
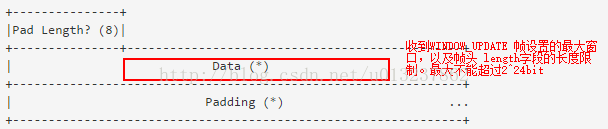
疑问:在最大窗口允许的情况下,如果一段一口气发送了多个data frame,由于并没有ack的标志,那么怎么保证data 帧之间的有序和无差错?
解决:对于多个data包存在的情况下,由于http在工作模式上来说是请求-响应的,所以被请求端主动发大消息体给请求端概率不大,所以不能把确认位ACK设置在DATA frame里面。所以在发送多个DATA 包的情况下,必须等待接受一个UPDATE_WINDOW帧,这个帧有一个delter位,表示已经接受到的字节数。也就是ACK的工作原理。当接受到的时候,才能发送下一个DATA frame。
实验结果截图如,具体过程见文章,HTTP2 通信过程

为什么要设计二进制分帧层?:
1、实现请求的并发处理,那么必须有一个标志位,标志不同的请求。http1.x并没有提供任何的字段给请求或响应做区分
2、由于http2与http1.x的差异极大,但是要实现向前兼容,所以必须增加一个功能层,来做修改格式的工作。
http1.x的通信过程:
http2的通信过程:
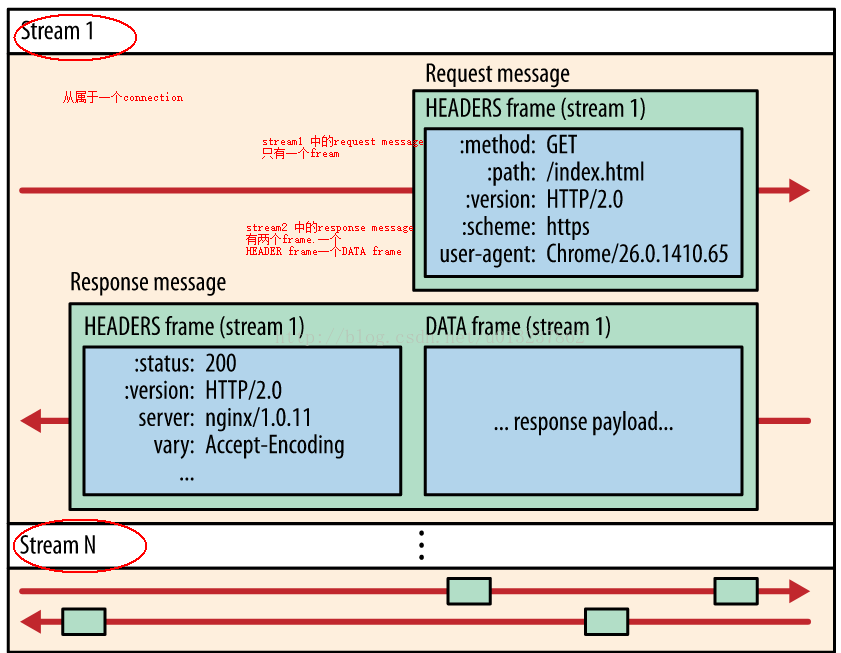
客户端:发出request1 ——》分帧层:send HEADERS frame (stream1) ——》服务端:建立connection中的一条数据流stream1
send DATA frame(stream1) ——》服务端:接受request 正文
客户端:发出request2 ——》分帧层:send HEADERS frame(stream2) ——》服务端:建立数据流stream2
send DATA frame(stream2) ——》 服务端:接受request2正文
客户端:接受response1《——分帧层:receive DATA frame(stream1) 《—— 服务端:发送request1 的response(stream1)
客户端可以一次性发送一打请求,这些请求将生成多个数据流。在一个数据流中,包含着request和响应的response的多组消息。其中一条消息由承载着不同内容的frame构成。
也就是说:一个请求和其响应将拆分为:双向数据传递的数据流(stream)
数据流:包含该一组事务的一条或者多条消息(message)
消息:request或者response,包含一个或多个帧(frame)
帧: 帧是最小的通信单位,承载着特定类型的数据,例如 HTTP 标头、消息负载,等等。 来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符 重新组装。
效果:实现了多路复用
问题来了:
Question1:资源与资源之间存在着依赖关系,或者资源之间的优先级有差异。存在可能是并发的请求多个资源,但是被依赖的资源先返回。或者等待一个重要的资源,但是服务器还在发送一些不是那么重要的,比如说图片之类的资源。

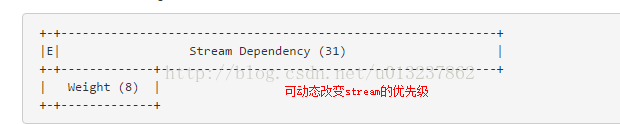
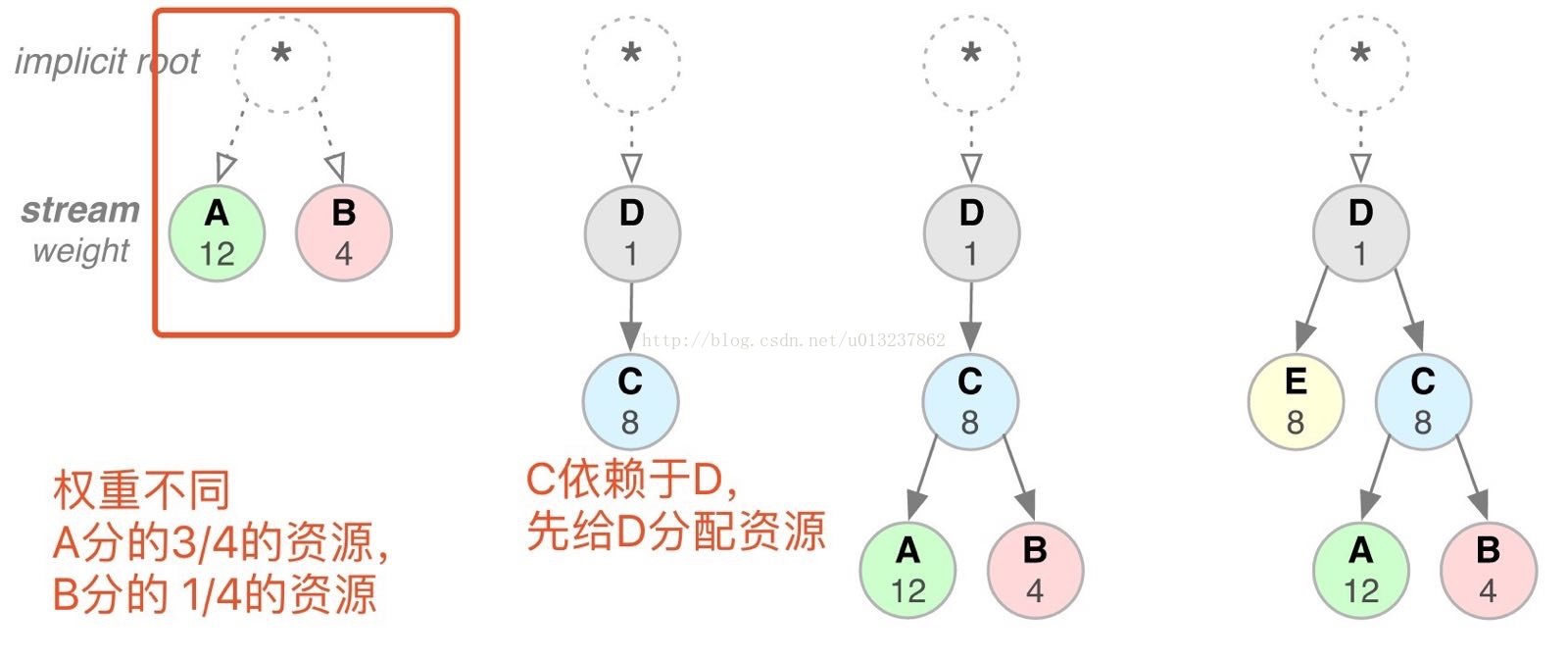
Question2: 现在http2的请求是并发的。server可能同时收到很多stream的大量frame。并且http允许服务器主动推送消息给client。接收端很可能接受到超过自身处理能力的信息。
解决: 流控制
该问题很像tcp上的流量控制。所以在http2的流控制,也解决了tcp上流量控制和拥塞控制的策略。即滑动窗口和慢启动。
滑动窗口: receiver 可以发送WINDOW_UPDATE frame,表明自己可以接受的最大字节数。在发送满WINDOW_UPDATE中规定的字节之后,不许等待响应,才能继续发送(但是窗口满的时候,允许发送length = 0 的带有END_STREAM flag的frame。标识关闭该stream)

Window Size Increment: 窗口最大为2^32 -1(2,147,483,647)byte.
如果Stream id = 0: 表示全部的流都收到该滑动窗口大小限制
如果stream id != 0:表示被指定的流滑动窗口大小为WSI大小的限制。
当窗口满了的时候,接受到WINDOW_UPDATE frame ,才会继续发送数据。
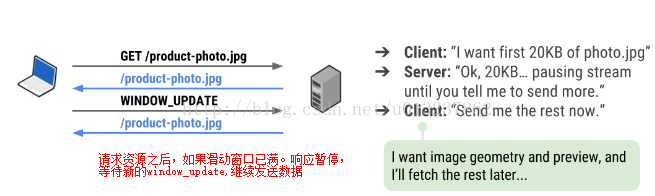
详细过程举例:
客户端的Window_SIZE: 20KB, 于是服务端最多还能向客户端发送 20KB的data frame。
服务端的window_SIze: 40KB. 于是客户端最多还能像客户端发送40KB的data frame。
a、http2 connection刚被简历的时候,初始的流量窗口大小是 2^16-1 = 65535. c端和s端都表示可以接受这么多的数据。
b、一方在收发headers frame之前如果收到了 SETTING frame,并且规定了SETTINGS_INITIAL_WINDOW_SIZE,则必须尊重对方的要求,按照对方的窗口来发送数据。
c、万一一方收到SETTINGS_INITAL_WINDOW_SIZE,使得可以发送的frame变为负数,那么盖房一定不能发送新的frame,直到接收到WINDOW_UPDATE frame,使得流量窗口变为正数。
d、由于每一次发送DATA 操作都要收到WINDOW_UPDATE帧的控制。所以不需要用窗口增长的算法来增大滑动窗口。直接由WINDOW_UPDATE来灵活控制。
其他优化
1、首部压缩技术(Header compression and Decompression)
由于http是无状态的。因此请求与请求之间相对而言是独立的。这就造成了每一次请求,header部分都必需是完全的。但是很多情况下,每一个请求header只有少数部分有变化。这就造成了header的大量冗余。http2为了解决无状态的问题,使用了头部压缩技术。
为了减少此开销和提升性能,HTTP/2 使用 HPACK 压缩格式压缩请求和响应标头元数据,这种格式采用两种简单但是强大的技术:
1、这种格式支持通过静态 Huffman 代码对传输的标头字段进行编码,从而减小了各个传输的大小。
2、这种格式要求客户端和服务器同时维护和更新一个包含之前见过的标头字段的索引列表(换句话说,它可以建立一个共享的压缩上下文),此列表随后会用作参考,对之前传输的值进行有效编码。
利用 Huffman 编码,可以在传输时对各个值进行压缩,而利用之前传输值的索引列表,我们可以通过传输索引值的方式对重复值进行编码,索引值可用于有效查询和重构完整的标头键值对。
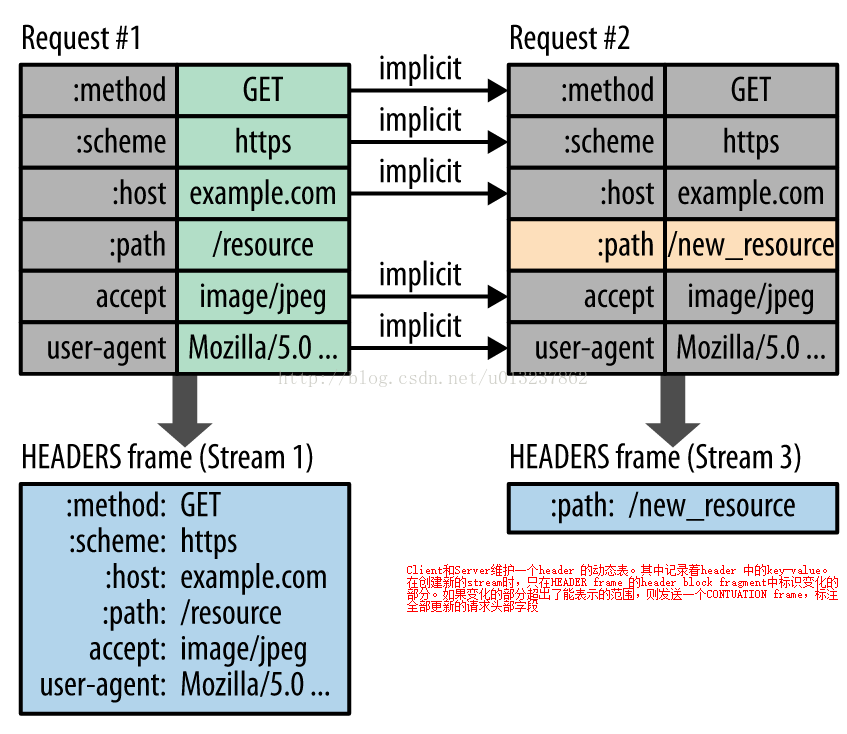
在帧结构中:HEADER frame中:
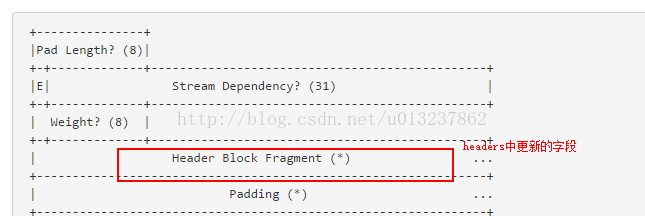
如果变化太多的话,则发送一个CONTINUATION frame(type = 00001001B)
服务器主动推流(Server Push):
客服端在请求一个网页之后,html中包含了大量内联的请求资源。按照原来http协议的设计,需要在html解析之后,再依次发出请求。但是实际上,服务器在响应这个html请求之后,就知道客户端接下来会请求html中包含的资源。http2的服务器主动推流,就是设计出来,让服务器可以主动的把消息发送给客户端。而节省了解析的时延。

由服务器主动推送的frame有自己的type(PUSH_PROMISE frame)。客服端可以发送SETTING frame 的SETTING_ENABLE_PUSH来决定是否接受服务器的主动推送。

之后服务器主动push的data将在PUSH_PROMISE创建的stream中传递。