1、预测年收入是否大于50K美元
读取adult.txt文件,最后一列是年收入,并使用KNN算法训练模型,然后使用模型预测一个人的年收入是否大于50
导包
import pandas as pd
from pandas import Series,DataFrame
# fit----->train训练
# predict ---->test测试预测
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier导入数据集
df = pd.read_csv('../data/adults.txt')
df.shape
Out: (32561, 15)
df.head()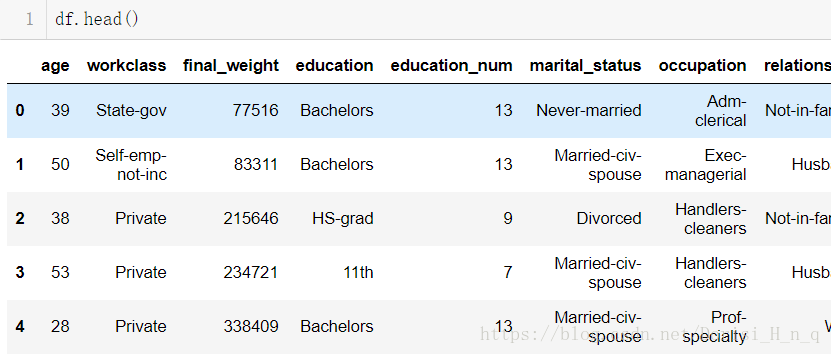
没有转换成计算机语言直接训练会报错
# ValueError: could not convert string to float: 'United-States'
knn.fit(df.iloc[:,:-1],df['salary'])
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-92-86545a75d1cd> in <module>()
----> 1 knn.fit(df.iloc[:,:-1],df['salary'])
……ValueError: could not convert string to float: 'United-States'去除没有相关性的特征
获取年龄、教育程度、职位、每周工作时间作为机器学习数据
获取薪水作为对应结果
df['education'].unique()
Out:
array(['Bachelors', 'HS-grad', '11th', 'Masters', '9th', 'Some-college',
'Assoc-acdm', 'Assoc-voc', '7th-8th', 'Doctorate', 'Prof-school',
'5th-6th', '10th', '1st-4th', 'Preschool', '12th'], dtype=object)
X = df.iloc[:,:-1]
X.head()
X.drop('final_weight',axis = 1,inplace=True)
X.drop('education',axis = 1,inplace=True)
X.drop('relationship',axis = 1,inplace=True)
X.drop('capital_loss',axis = 1,inplace=True)
X.drop('capital_gain',axis = 1,inplace=True)
y = df['salary']
X.head()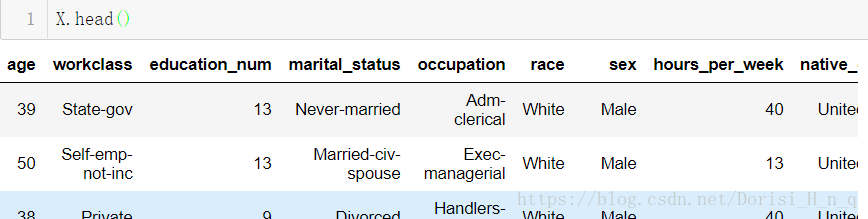
使用数字替换映射文本
扫描二维码关注公众号,回复:
3221354 查看本文章

workclass = X['workclass'].unique()
workclass
array(['State-gov', 'Self-emp-not-inc', 'Private', 'Federal-gov',
'Local-gov', '?', 'Self-emp-inc', 'Without-pay', 'Never-worked'],
dtype=object)
np.argwhere(workclass == 'Private')[0,0]
Out: 2
np.argwhere(workclass == 'Local-gov')[0,0]
Out: 4def convert(item):
#
index = np.argwhere(workclass == item)[0,0]
# 索引,0 ~ 8 使用索引替代str
return indexX['workclass'] = X['workclass'].map(convert)
X.head()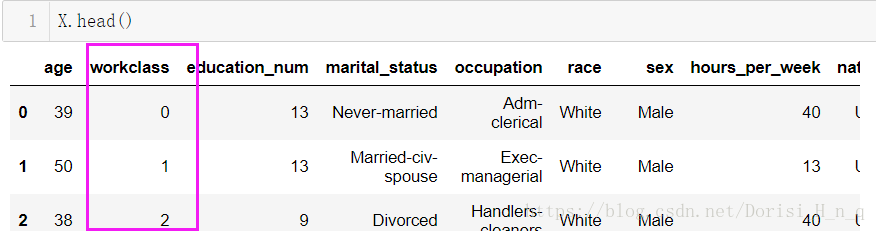
数据转换,将String类型数据转换为int:统一替换
【知识点】map方法,进行数据转换
X.columns
Out:
Index(['age', 'workclass', 'education_num', 'marital_status', 'occupation',
'race', 'sex', 'hours_per_week', 'native_country'],
dtype='object')
cols = [ 'marital_status', 'occupation',
'race', 'sex','native_country']
for col in cols:
u = X[col].unique()
def convert(item):
return np.argwhere(u == item)[0,0]
X[col] = X[col].map(convert)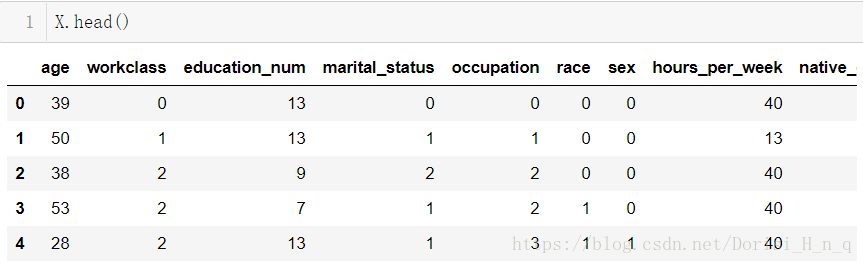
查看数据类型
X.dtypes
Out:
age int64
workclass int64
education_num int64
marital_status int64
occupation int64
race int64
sex int64
hours_per_week int64
native_country int64
dtype: object
X.shape
Out: (32561, 9)划分训练测试数据
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 1000)生成算法
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train,y_train)
knn.score(X_test,y_test)
Out:
0.787knn = KNeighborsClassifier(n_neighbors=10)
knn.fit(X_train,y_train)
knn.score(X_test,y_test)
Out:
0.79预测数据
y_ = knn.predict("你的测试数据集")保存训练模型
在模型持久化过程中,我们使用scikit-learn提供的joblib.dump()方法,但是在使用过程中会出现很多问题。如我们使用如下语句:此语句将产生大量的模型文件
from sklearn.externals import joblib
joblib.dump(knn_model,'filename.pkl')
knn_model=joblib.load('filename.pkl')当设置参数时,模型持久化便会压缩成一个文件,以下是我们进行模型持久化的正确操作语句:
from sklearn.externals import joblib
#save model
joblib.dump(clf,'../../data/model/randomforest.pkl',compress=3)
#load model to clf
clf = joblib.load('../../data/model/randomforest.pkl')