有些网站需要先登录才能浏览一些信息,那我们面对这种情况要怎么爬取呢?
也就是说如何使用爬虫模拟登录
cookies 概念
网页都是使用 http 协议进行访问的,但 http 协议是无记忆的
就是是它不会记得你是谁,所以需要有记忆信息的网站,比如需要登录的淘宝,就自动为每个用户创建了一个记忆功能的东西,这样的下次你再访问它,它就可以凭借这个东西认出你是谁
这个记忆功能的东西,在服务器端是 session,在客户端就是 cookies
登录的信息就保存在里面
案例我们以 CSDN 的登录
找到请登录请求
这是第一大步
方法:1.打开登录页面-->输入登陆信息-->开发者工具-->Network-->勾选Preserve log
2.点击登录-->找到带有 Form Data 的请求,一般就在前几个里,该请求就是登录请求


先说一种比较傻的方法,Cookie里面有登录信息,所以直接 粘贴Cookie 信息
粘贴Cookie访问
找到登录请求后我们发现该请求的 Request Headers 里面就有 Cookie
前面说过登录信息跟 Cookie 相关吗,那我们把它粘贴下来,用代码访问一下该请求的 url ,注意访问方法为 post
# 导入requests请求库 import requests # 登录请求的url post_url = 'https://passport.csdn.net/account/verify' # 用Cookie信息构造请求头 headers = { # 粘贴的Cookie 'Cookie' : 'uuid_tt_dd=10_20074595140-1530622109451-397473; smidV2=201807182214086f0bcefc66a41b970dad17e19dd5fd180000d5f5b935c00e0; UN=Jeeson_Z; UM_distinctid=164b5935a7e0-063c2c864928e8-47e1039-e1000-164b5935a80512; dc_session_id=10_1533976146578.369933; JSESSIONID=30624DBEE43E0586B7DA76DBF7295305.tomcat2; Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1533980134,1533980146,1533980216,1533980232; BT=1533980269436; LSSC=LSSC-1514209-KasPPcU2AFLkjzHmWV6YaFeqBg5CL3-passport.csdn.net; dc_tos=pdair9; Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1533980278' } # 用post()方法访问,headers参数表示请求头 rsp = requests.post(post_url, headers=headers) # text属性获取返回源码的文本内容 html = rsp.text # 把这个内容保存到名为'csdn.html'文件,html格式能直接用浏览器打开 with open("csdn.html", "w", encoding='utf-8') as f: f.write(html)用浏览器打开代码生成的html文件,结果如下,登录成功



虽然上面的代码能成功登录访问,但最大的问题是一旦Cookie失效就不能访问了
我们来说一下模拟登录的一般方法:填表单
填表单
回到我们找到的请求头,所谓的表单就是 Form Data ,它里面存放的就是登录所需要的全部信息,所以理论上讲,只要填完这张表单的内容,我们就可以登录了
比如 CSDN 的就有gps、用户名、密码还有很多看起来很长很乱的东西
我们分析一下,用户名和密码不用说了、直接显示了,就是用户的名儿和密码,这是不会变的(我给马掉了)
其他的就是用于加密的动态信息码了,那这些加密的信息如何获取呢?
提取加密信息
既然在登录页面点击登录后就生成这个表单,没有经过其他操作,那就说明这些信息都存放在登录页面的源码里
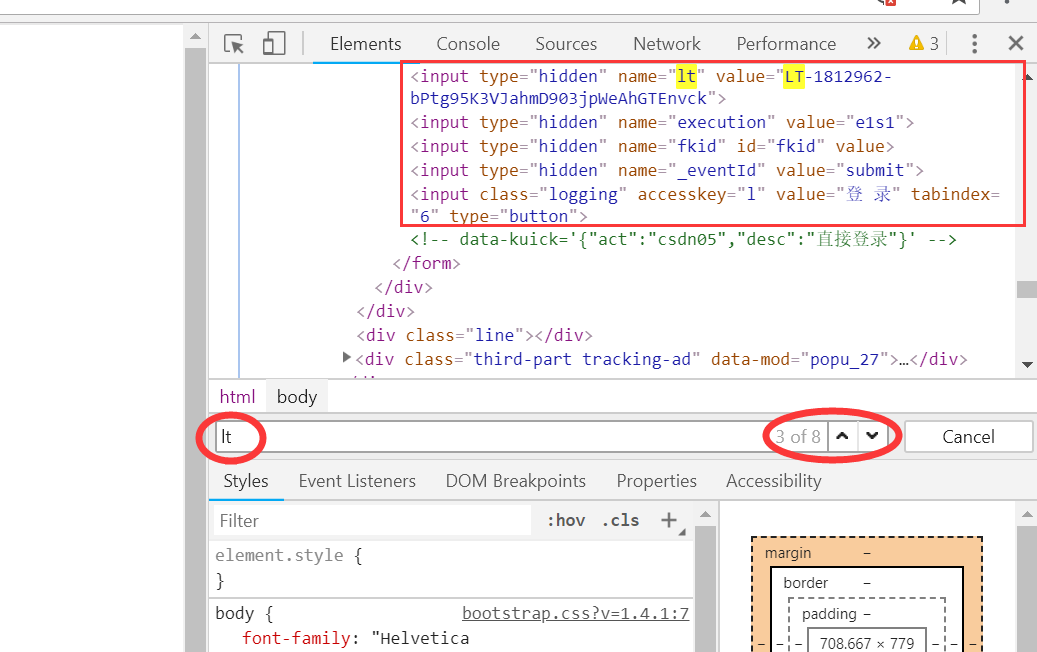
打开登录页面-->开发者工具-->Elements-->按下 ‘Ctrl+F’ 关键字查找,然后输入gps
就可以找到gps的值了,只不过这里值恰好为空
同理,也可以找到其他信息的值
然后我们写个解析代码,把这些值都提取出来
# 导入requests请求库 import requests # 导入BeautifulSoup解析模块 from bs4 import BeautifulSoup # 登录页面的url login_url = 'https://passport.csdn.net/account/login' # get()方法请求 login_rsp = requests.get(login_url) # text属性获取源码文本 html = login_rsp.text # BeautifulSoup()将源码转换成能被BeautifulSoup解析的lxml文件 soup = BeautifulSoup(html, 'lxml') # 找到隐藏标签的位置 hidden = soup.find_all(name='input', attrs={'type': 'hidden'}) # 提取gps gps = hidden[0].attrs['value'] # 提取lt lt = hidden[1].attrs['value'] # 提取execution execution = hidden[2].attrs['value'] # 提取fkid fkid = hidden[3].attrs['value'] # 提取_eventId eventid = hidden[4].attrs['value'] # 换行打印出来 print(gps + '\n' + lt + '\n' + execution + '\n' + fkid + '\n' + eventid)结果如下:
gps是定位,可以为空,但fkid也为空,这就是CSDN的加密机制生成的,目的就是怕我们模拟登录,这个需要知道它的加密机制,才能破解
但我还是把完整的流程走一边,假装我们已经获取了完整的表单信息
接下来就是用这个信息构造表单
form = { 'gps': gps, 'username': '********', 'password': '********', 'rememberMe': 'true', 'lt': lt, 'execution': execution, 'fkid': fkid, '_eventId': eventid }(账户和密码填自己的,我这里用“*”代替)
还有一些网站会检查请求头的 Host、Referer、User_Agent,之所以我们也要粘贴这些信息构造请求头
headers = { 'Host': 'passport.csdn.net', 'Referer': 'https://passport.csdn.net/account/login', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36', }然后用requests的Session对象进行访问
# 用Session对象提交访问 session = requests.Session() # post()方法访问提交表单 rsp = session.post(post_url, data=form, headers=headers) # 获取源码文本 html = rsp.text # 把源码存为能用浏览器打开的html文件 with open("csdn.html", "w", encoding='utf-8') as f: f.write(html)按正常的步骤,打开这个代码生成的html文件就能看到登录成功后的页面了,但 我们没能得知fkid的加密机制,所以这个表单不全,因此这个代码也没能运行成功,这是反爬的重要措施之一,不过可以总结出模拟登陆的步骤了