一 迁移学习
如果你要做一个计算机视觉的应用,相比于从头训练权重,或者说从随机初始化权重开始,如果你下载别人已经训练好网络结构的权重,你通常能够进展的相当快,用这个作为预训练,然后转换到你感兴趣的任务上。计算机视觉的研究社区非常喜欢把许多数据集上传到网上,如果你听说过,比如 ImageNet, 或者 MS COCO,或者 Pascal 类型的数据集,这些都是不同数据集的名字,它们都是由大家上传到网络的,并且有大量的计算机视觉研究者已经用这些数据集训练过他们的算法了。有时候这些训练过程需要花费好几周,并且需要很多的GPU,其它人已经做过了,并且经历了非常痛苦的寻最优过程,这就意味着你可以下载花费了别人好几周甚至几个月而做出来的开源的权重参数,把它当作一个很好的初始化用在你自己的神经网络上。用迁移学习把公共的数据集的知识迁移到你自己的问题上,让我们看一下怎么做。

举个例子,假如说你要建立一个猫咪检测器, 用来检测你自己的宠物猫。比如网络上的Tigger,是一个常见的猫的名字, Misty 也是比较常见的猫名字。假如你的两只猫叫 Tigger 和Misty,还有一种情况是,两者都不是。所以你现在有一个三分类问题,图片里是 Tigger 还是 Misty,或者都不是,我们忽略两只猫同时出现在一张图片里的情况。现在你可能没有Tigger 或者 Misty 的大量的图片,所以你的训练集会很小,你该怎么办呢?

我建议你从网上下载一些神经网络开源的实现,不仅把代码下载下来,也把权重下载下来。有许多训练好的网络,你都可以下载。举个例子, ImageNet 数据集,它有 1000 个不同的类别,因此这个网络会有一个 Softmax 单元,它可以输出 1000 个可能类别之一。
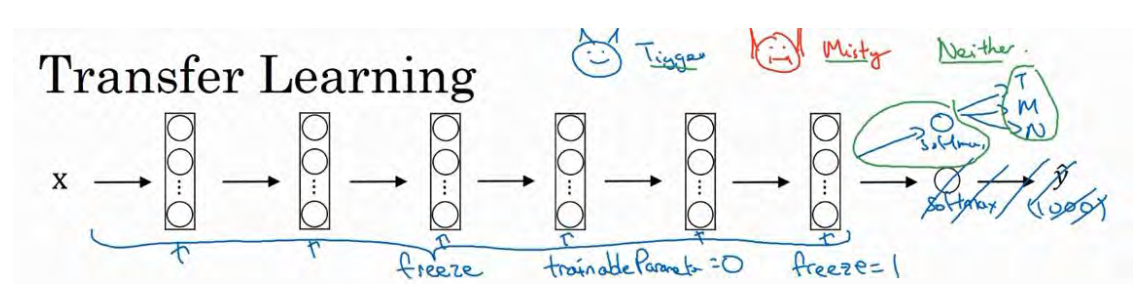
你可以去掉这个 Softmax 层,创建你自己的 Softmax 单元,用来输出 Tigger、 Misty 和neither 三个类别。就网络而言,我建议你把所有的层看作是冻结的,你冻结网络中所有层的参数,你只需要训练和你的 Softmax 层有关的参数。这个 Softmax 层有三种可能的输出,Tigger、 Misty 或者都不是。通过使用其他人预训练的权重,你很可能得到很好的性能,即使只有一个小的数据集。幸运的是,大多数深度学习框架都支持这种操作,事实上,取决于用的框架,它也许会有trainableParameter=0 这样的参数,对于这些前面的层,你可能会设置这个参数。为了不训练这些权重,有时也会有 freeze=1 这样的参数。不同的深度学习编程框架有不同的方式,允许你指定是否训练特定层的权重。在这个例子中,你只需要训练 softmax 层的权重,把前面这些层的权重都冻结。
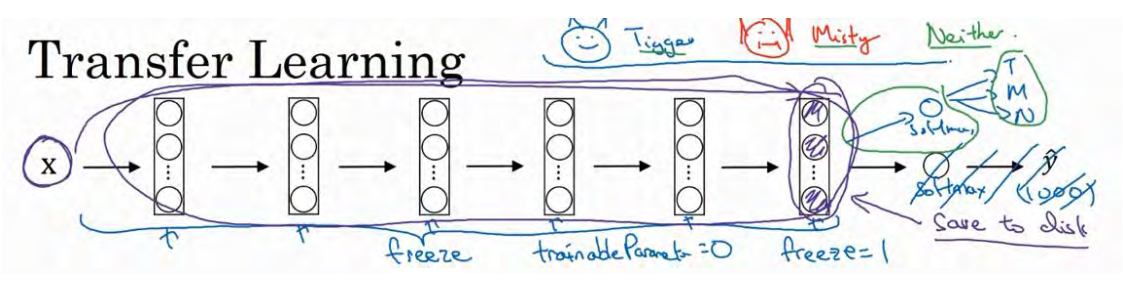
另一个技巧,也许对一些情况有用,由于前面的层都冻结了,相当于一个固定的函数,不需要改变。因为你不需要改变它,也不训练它,取输入图像x,然后把它映射到这层(softmax的前一层)的激活函数。所以这个能加速训练的技巧就是,如果我们先计算这一层(紫色箭头标记),计算特征或者激活值,然后把它们存到硬盘里。你所做的就是用这个固定的函数,在这个神经网络的前半部分(softmax 层之前的所有层视为一个固定映射),取任意输入图像x,然后计算它的某个特征向量,这样你训练的就是一个很浅的 softmax 模型,用这个特征向量来做预测。对你的计算有用的一步就是对你的训练集中所有样本的这一层的激活值进行预计算,然后存储到硬盘里,然后在此之上训练 softmax 分类器。所以,存储到硬盘或者说预计算方法的优点就是,你不需要每次遍历训练集再重新计算这个激活值了。

因此如果你的任务只有一个很小的数据集,你可以这样做。要有一个更大的训练集怎么办呢?根据经验,如果你有一个更大的标定的数据集,也许你有大量的 Tigger 和 Misty 的照片,还有两者都不是的,这种情况,你应该冻结更少的层,比如只把这些层冻结,然后训练后面的层。如果你的输出层的类别不同,那么你需要构建自己的输出单元, Tigger、 Misty 或者两者都不是三个类别。有很多方式可以实现,你可以取后面几层的权重,用作初始化,然后从这里开始梯度下降.。

或者你可以直接去掉这几层,换成你自己的隐藏单元和你自己的 softmax 输出层,这些方法值得一试。但是有一个规律,如果你有越来越多的数据,你需要冻结的层数越少,你能够训练的层数就越多。这个理念就是,如果你有一个更大的数据集,也许有足够多的数据,那么不要单单训练一个 softmax 单元,而是考虑训练中等大小的网络,包含你最终要用的网络的后面几层。

最后,如果你有大量数据,你应该做的就是用开源的网络和它的权重,把这、所有的权重当作初始化,然后训练整个网络。再次注意, 如果这是一个 1000 节点的 softmax,而你只有三个输出,你需要你自己的 softmax 输出层来输出你要的标签。
如果你有越多的标定的数据,或者越多的 Tigger、 Misty 或者两者都不是的图片,你可以训练越多的层。极端情况下,你可以用下载的权重只作为初始化,用它们来代替随机初始化,接着你可以用梯度下降训练,更新网络所有层的所有权重。
这就是卷积网络训练中的迁移学习,事实上,网上的公开数据集非常庞大,并且你下载的其他人已经训练好几周的权重,已经从数据中学习了很多了,你会发现,对于很多计算机视觉的应用,如果你下载其他人的开源的权重,并用作你问题的初始化,你会做的更好。在所有不同学科中,在所有深度学习不同的应用中,我认为计算机视觉是一个你经常用到迁移学习的领域,除非你有非常非常大的的数据集,你可以从头开始训练所有的东西。总之,迁移学习是非常值得你考虑的,除非你有一个极其大的数据集和非常大的计算量预算来从头训练你的网络。
二 数据扩充
大部分的计算机视觉任务使用很多的数据,所以数据扩充是经常使用的一种技巧来提高计算机视觉系统的表现。我认为计算机视觉是一个相当复杂的工作, 你需要输入图像的像素值,然后弄清楚图片中有什么,似乎你需要学习一个复杂方程来做这件事。在实践中,更多的数据对大多数计算机视觉任务都有所帮助,不像其他领域,有时候得到充足的数据,但是效果并不怎么样。但是,当下在计算机视觉方面,计算机视觉的主要问题是没有办法得到充足的数据。对大多数机器学习应用,这不是问题,但是对计算机视觉,数据就远远不够。所以这就意味着当你训练计算机视觉模型的时候,数据扩充会有所帮助,这是可行的,无论你是使用迁移学习,使用别人的预训练模型开始,或者从源代码开始训练模型。让我们来看一下计算机视觉中常见的数据扩充的方法。

或许最简单的数据扩充方法就是垂直镜像对称,假如,训练集中有这张图片,然后将其翻转得到右边的图像。对大多数计算机视觉任务,左边的图片是猫,然后镜像对称仍然是猫,如果镜像操作保留了图像中想识别的物体的前提下,这是个很实用的数据扩充技巧。
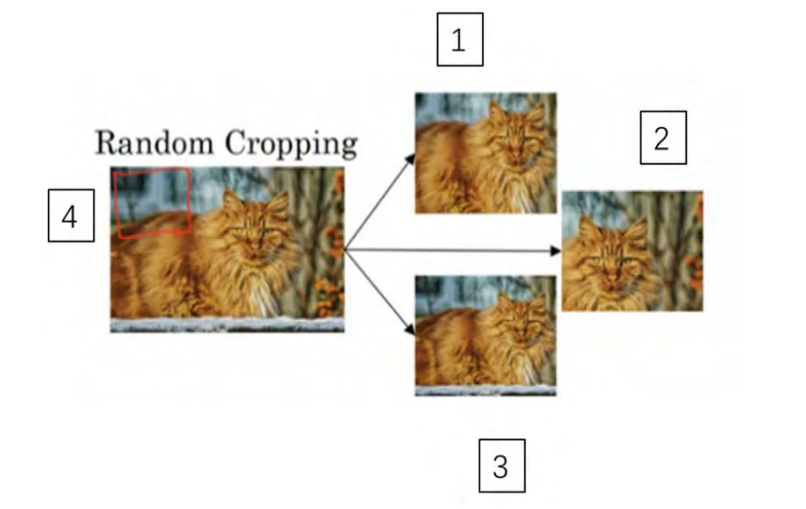
另一个经常使用的技巧是随机裁剪,给定一个数据集,然后开始随机裁剪,可能修剪这个(编号 1),选择裁剪这个(编号 2),这个(编号 3),可以得到不同的图片放在数据集中,你的训练集中有不同的裁剪。随机裁剪并不是一个完美的数据扩充的方法,如果你随机裁剪的那一部分(红色方框标记部分,编号 4),哪一个看起来更像猫。但在实践中,这个方法还是很实用的,随机裁剪构成了很大一部分的真实图片,由于随机裁切可能裁切到的一部分不含有物体,我们可以一次裁切得到一个较大的图像,然后缩放到我们想要的尺寸,这样包含物体的概率会更大。
镜像对称和随机裁剪是经常被使用的。当然,理论上,你也可以使用旋转,剪切(shearing:此处并非裁剪的含义,图像仅水平或垂直坐标发生变化)图像,可以对图像进行这样的扭曲变形,引入很多形式的局部弯曲等等。当然使用这些方法并没有坏处,尽管在实践中,因为太复杂了所以使用的很少。
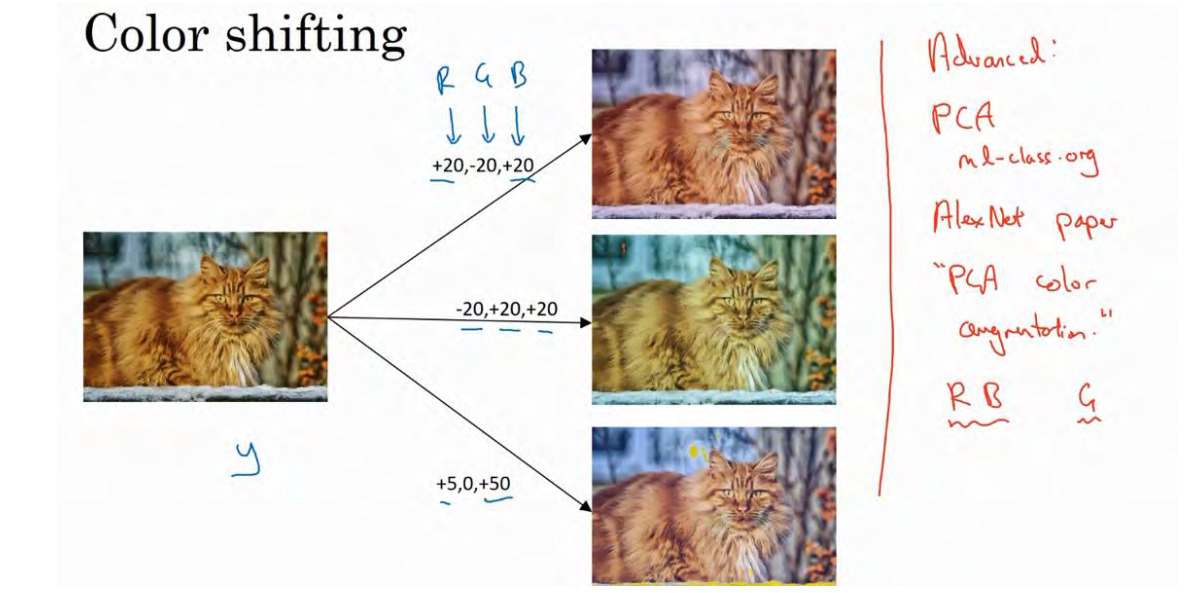
第二种经常使用的方法是彩色转换,有这样一张图片,然后给 R、 G 和 B 三个通道上加上不同的失真值.
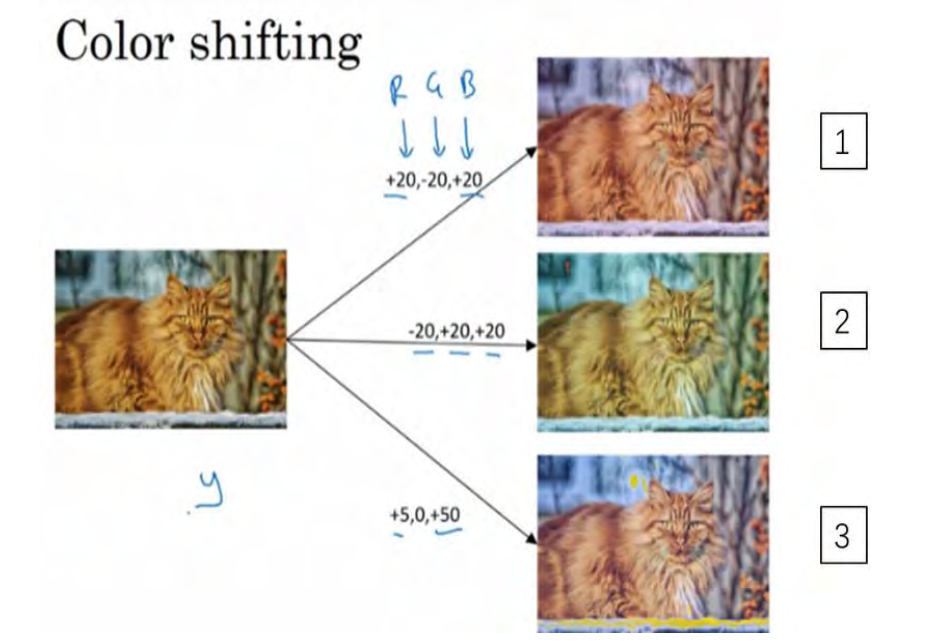
在这个例子中(编号 1),要给红色、蓝色通道加值,给绿色通道减值。红色和蓝色会产生紫色,使整张图片看起来偏紫,这样训练集中就有失真的图片。为了演示效果,我对图片的颜色进行改变比较夸张。在实践中,对 R、 G 和 B 的变化是基于某些分布的,这样的改变也可能很小。
这么做的目的就是使用不同的 R、 G 和 B 的值,使用这些值来改变颜色。在第二个例子中(编号 2),我们少用了一点红色,更多的绿色和蓝色色调,这就使得图片偏黄一点。在这(编号 3)使用了更多的蓝色,仅仅多了点红色。在实践中, R、 G 和 B 的值是根据某种概率分布来决定的。这么做的理由是,可能阳光会有一点偏黄,或者是灯光照明有一点偏黄,这些可以轻易的改变图像的颜色,但是对猫的识别,或者是内容的识别,以及标签y,还是保持不变的。所以介绍这些,颜色失真或者是颜色变换方法,这样会使得你的学习算法对照片的颜色更改更具鲁棒性。
这是对更高级的学习者的一些注意提醒,你可以不理解我用红色标出来的内容。对 R、G 和 B 有不同的采样方式,其中一种影响颜色失真的算法是 PCA,即主成分分析。但具体颜色改变的细节在 AlexNet 的论文中有时候被称作 PCA 颜色增强, PCA 颜色增强的大概含义是,比如说,如果你的图片呈现紫色,即主要含有红色和蓝色,绿色很少,然后 PCA 颜色增强算法就会对红色和蓝色增减很多,绿色变化相对少一点,所以使总体的颜色保持一致。如果这些你都不懂,不需要担心,可以在网上搜索你想要了解的东西,如果你愿意的话可以阅读 AlexNet 论文中的细节,你也能找到 PCA 颜色增强的开源实现方法,然后直接使用它。
你可能有存储好的数据,你的训练数据存在硬盘上,然后使用符号,这个圆桶来表示你的硬盘。如果你有一个小的训练数据,你可以做任何事情,这些数据集就够了。

但是你有特别大的训练数据,接下来这些就是人们经常使用的方法。你可能会使用 CPU线程,然后它不停的从硬盘中读取数据,所以你有一个从硬盘过来的图片数据流。你可以用CPU 线程来实现这些失真变形,可以是随机裁剪、颜色变化,或者是镜像。但是对每张图片得到对应的某一种变形失真形式,看这张图片(编号 1),对其进行镜像变换,以及使用颜色失真,这张图最后会颜色变化(编号 2),从而得到不同颜色的猫。
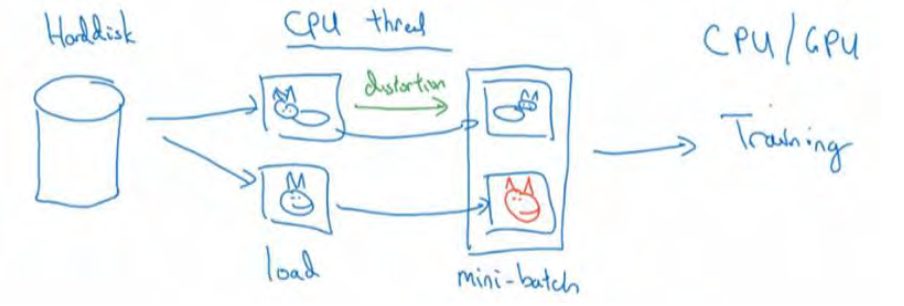
与此同时, CPU 线程持续加载数据,然后实现任意失真变形,从而构成批数据或者最小批数据,这些数据持续的传输给其他线程或者其他的进程,然后开始训练,可以在 CPU 或者 GPU 上实现训一个大型网络的训练。
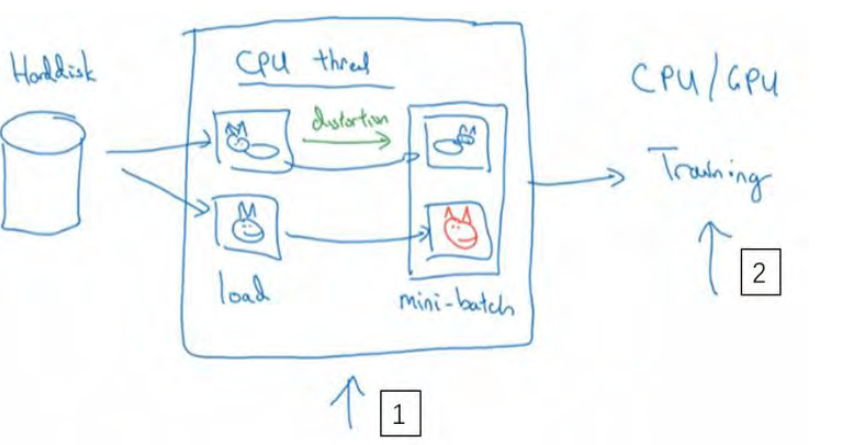
常用的实现数据扩充的方法是使用一个线程或者是多线程,这些可以用来加载数据,实现变形失真,然后传给其他的线程或者其他进程,来训练这个(编号 2)和这个(编号 1),可以并行实现。这就是数据扩充,与训练深度神经网络的其他部分类似,在数据扩充过程中也有一些超参数,比如说颜色变化了多少,以及随机裁剪的时候使用的参数。与计算机视觉其他部分类似,一个好的开始可能是使用别人的开源实现,了解他们如何实现数据扩充。当然如果你想获得更多的不变特性,而其他人的开源实现并没有实现这个,你也可以去调整这些参数。因此,我希望你们可以使用数据扩充使你的计算机视觉应用效果更好。
三 数据扩充(代码)
在之前进行网络训练时,一般都是取样本图片,进行归一化处理后然后输入网络。我们可以在输入网络之前对图像预处理(数据增加),即起到随机生成新的样本的效果。下面就演示在tensorflow中调用一些图像处理函数对出现进行预处理后的效果。
在使用这些函数时,有一点需要注意,就是有些图像处理函数要求输入的图片必须是float类型(不然图像处理后效果会有问题),因此最好的方法,就是除非特别要求数据必须是uint8类型,我们就把样本图片先转换成float类型,然后再进行图像处理。
注意:我们图片数据如果是uint8类型,不要直接转换成flot32类型显示,不然显示效果不一样。但是可以先转换到float32类型,然后归一化到[0,1]范围显示(效果和原图一样)。关于图像的不同类型数据显示,可以查看第一节,初识OpenCV3-图像的读、写、显、格式转化等中的cv2.imshow()函数,进行具体了解。
# -*- coding: utf-8 -*-
"""
Created on Thu Jun 7 15:36:10 2018
@author: zy
"""
'''
图像预处理和数据扩充
最常用的方法有尺度缩放、随机切片、随机翻转、颜色变换等。
参考文章:TensorFlow 图像数据预处理及可视化:https://blog.csdn.net/dxmkkk/article/details/54925728
'''
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from preprocessing import inception_preprocessing
from scipy import misc
import PIL.Image as Image
import cv2
def save_image(img_array,image_name):
'''
把图片数据保存下来
https://www.jb51.net/article/102981.htm
http://www.cnblogs.com/dylancao/p/9134790.html
args:
image_array:ndarray,图像数据
image_name:保存全路径
'''
#把一个数组转换成PIL图片
img_array = misc.toimage(img_array)
#保存图片
misc.imsave(image_name, img_array)
def read_image(file):
'''
读取图片, 这里使用PIL读取图片
https://blog.csdn.net/icamera0/article/details/50843172
args:
file:图片全路径
return:
返回一个ndarray类型 数据为uint8类型 形状为height x width x n_channel
'''
data = Image.open(file)
#可能是P模式 shape = width x height
#print(data.mode)
#shape = height x width x n_channel
data = data.convert('RGB')
return np.asarray(data,np.uint8)
def show_image(image,title):
'''
显示图片
args:
image:图片
title:标题
'''
#plt.figure(figsize=(4.8,3.2))
plt.figure()
plt.imshow(image,cmap='gray')
plt.title(title)
plt.show()
print('最小像素:',np.min(image),',最大像素:',np.max(image))
def norm(image):
'''
对图片进行归一化处理
args:
image:类型要求数据是uint8类型
'''
image = tf.cast(image,tf.float32)
image = tf.subtract(image, 128.0)
image = tf.div(image, 128.0)
return image
def process_image():
'''
TensorFlow 读取图片数据代码:
'''
# 我们要读取的图片
filename = ['cat1.jpg']
# string_input_producer会产生一个文件名队列
filename_queue = tf.train.string_input_producer(filename, shuffle=True)
# reader从文件名队列中读数据,一次读取一个文件。对应的方法是reader.read
reader = tf.WholeFileReader()
key, value = reader.read(filename_queue)
#Decode a JPEG-encoded image to a uint8 tensor 数据类型从字符串->uint8张量
image = tf.image.decode_jpeg(value)
'''
1.图片缩放 tf.image.resize_images
其中image:必须是float32类型 采用双线性插值等技术,需要改变原来生成三维矩阵后里面元素的格式,
即把整形转换成float32类型。
因此需要在 image = tf.image.decode_jpeg(value),后面添加这么一句:
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
method 有四种选择:
ResizeMethod.BILINEAR :双线性插值
ResizeMethod.NEAREST_NEIGHBOR : 最近邻插值
ResizeMethod.BICUBIC : 双三次插值
ResizeMethod.AREA :面积插值
'''
#resize之前调用这个函数 像素值转为[0,1]之间
image32 = tf.image.convert_image_dtype(image, dtype=tf.float32)
resized_image = tf.image.resize_images(image32, [256, 256], method=tf.image.ResizeMethod.AREA)
'''
2.裁切
'''
cropped_image = tf.image.crop_to_bounding_box(image32, 20, 20, 256, 256)
#从中间裁切指定大小,不足则填充
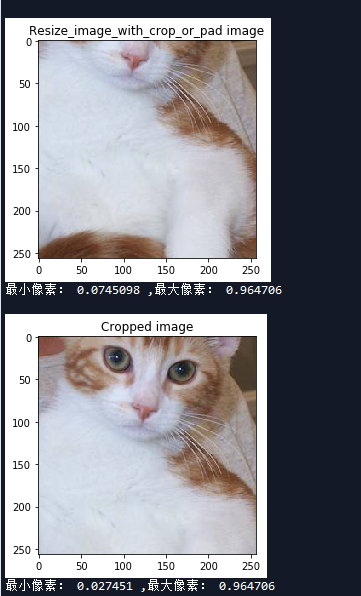
resize_image_with_crop_or_pad = tf.image.resize_image_with_crop_or_pad(image32, 256, 256)
'''
3.水平翻转
'''
cropped_image_left_to_right = tf.image.flip_left_right(image32)
'''
4.上下翻转
'''
flipped_image_up_to_down = tf.image.flip_up_down(image32)
'''
5.图像翻转
其中 k 值表示旋转 90 度的次数,读者可以尝试对原图旋转 180 度、270 度。
'''
rotated_image = tf.image.rot90(image32, k=1)
'''
6.图像灰度变换
'''
#tf.squeeze移除最后一维
grayed_image = tf.squeeze(tf.image.rgb_to_grayscale(image32))
'''
7.归一化处理
'''
norm_image = norm(image)
'''
8.slim库图像预处理
这里要求图像数据必须是float32类型
'''
pre_train_image = inception_preprocessing.preprocess_image(image32, 256, 256,is_training=True)
pre_test_image = inception_preprocessing.preprocess_image(image32, 256, 256,is_training=False)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
#必须初始化这个不然会报错
sess.run(tf.local_variables_initializer())
#创建一个协调器,管理线程
coord = tf.train.Coordinator()
#启动QueueRunner, 此时文件名才开始进队。
threads=tf.train.start_queue_runners(sess=sess,coord=coord)
show_image(image.eval(),'Original image')
show_image(resized_image.eval(),'Resized image')
show_image(resize_image_with_crop_or_pad.eval(),'Resize_image_with_crop_or_pad image')
show_image(cropped_image.eval(),'Cropped image')
show_image(cropped_image_left_to_right.eval(),'Flipped image')
show_image(flipped_image_up_to_down.eval(),'Flipped image')
show_image(rotated_image.eval(),'Rotated image')
show_image(grayed_image.eval(),'Grayed image')
show_image(norm_image.eval(),'Norm image')
#先进行预处理,然后调用plt显示,再保存,读取调用plt显示 可以看到两次结果不一样?
#我猜测是float数据类型在保存的时候转换为uint8类型,导致两次效果不一样
vgg_train = pre_train_image.eval()
show_image(vgg_train,'pre_train image')
save_image(vgg_train,'train.jpg')
later = read_image('train.jpg')
show_image(later,'Later pre_train saved ')
#转换为BGR格式,使用cv2显示
vgg_train= vgg_train[:,:,::-1]
cv2.imshow('before',vgg_train)
later= later[:,:,::-1]
cv2.imshow('later',later)
cv2.waitKey(0)
show_image(pre_test_image.eval(),'pre_test image')
#终止线程
coord.request_stop()
coord.join(threads)
if __name__ == '__main__':
tf.reset_default_graph()
process_image()





如果想了解更多数据增增强相关的函数,可以参考文章:TensorFlow学习笔记-图像预处理