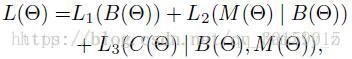论文题目:Instance-aware Semantic Segmentation via Multi-task Network Cascades
模型运行时间上,使用VGG-16一张图片需360ms。在MS COCO 2015分割比赛中获取第一名。
本文的出发点是做Instance-aware Semantic Segmentation,但是为了做好这个,作者将其分为三个子任务来做:
1) Differentiating instances. 实例区分
2) Estimating masks. 掩膜估计
3) Categorizing objects. 分类目标
整体框架
对于传统的多任务方法,在共享特征的基础上,每个任务同时进行,在后续的实验中,各个任务之间互不干扰,互相独立。
这篇论文提出的多任务方法,在共享特征的基础上,下一个任务依赖于上一个任务以及共享特征,如此形成层级的多任务结构。

详细解析
这篇论文主要做三个任务:
(1). 实例区分 (Differentiating instances)
(2). 掩膜估计 ( Estimating masks)
(3). 分类目标 (Categorizing objects)
可以使用VGG-16前13层学到的特征作为共享特征。
每个任务阶段都包括一个损失项,下一任务阶段的损失依赖于上一任务的损失。
为了实现反向传播,论文使用了关于空间坐标可微的网络层,使得梯度可计算。
通过这种分解,作者提出了如下的多任务学习框架,即:Multi-task Network Cascades (MNCs),示意流程如下:

详细流程:
1. Multi-task Network Cascades
1). Regressing Box-level Instances
第一个阶段是回归出物体的bbox,这是一个全卷积的子网络。本文follow了Faster R-CNN的提取proposal的方法Region Proposal Networks (RPNs)。在共享feature之前,作者先用了一个 3*3的Conv 用于降维,紧跟着用2个1*1的Conv层回归出其位置,并且对目标进行分类。该阶段的loss function是:
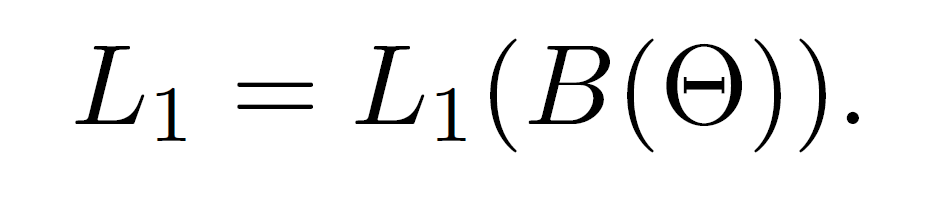
其中,B是该阶段的输出,是一系列的box,B = { Bi }, Bi = { xi; yi; wi; hi; pi },box的中心点和长宽分别是:xi yi wi hi, yi是物体的概率。
2). Regressing Mask-level Instances
该阶段的输出是对每一个box的proposal进行像素级的mask分割。
Given a box predicted by stage 1, we extract a feature of this box by Region-of-Interest (RoI) pooling . The purpose of RoI pooling is for producing a fixed-size feature from an arbitrary box, which is set as 14*14 at this stage. (给定阶段1产生的box,我们用RoI pooling的方法提取该box的特征。用RoI pooling的原因是从一个任意的box中产生一个固定长度的feature。)
在每一个box的feature之后,添加两个fc层,第一个fc将维度降到256, 第二个fc 回归出像素级的mask。
第二阶段的loss function符合下面的形式:
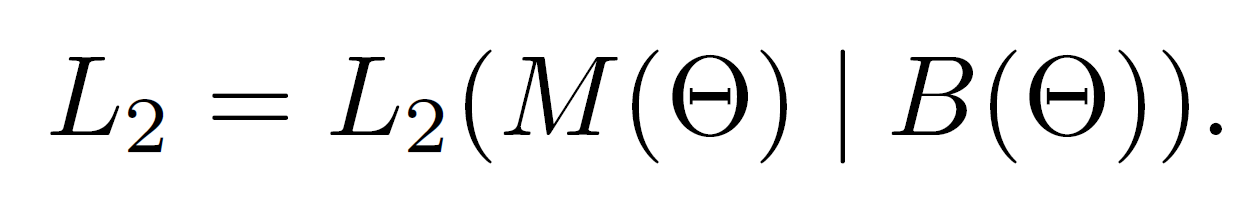
其中,M是该阶段的输出,代表一系列的mask,M = { Mi }, Mi = m^2 维的逻辑回归输出(用sigmoid回归到 [0,1])。该阶段的loss不仅依赖于M,而且依赖于B。
3). Categorizing Instances
给定第一阶段的box,也对其进行特征的提取。然后用第二阶段的mask估计进行二值化。这么做的好处是:this lead to a feature focused on the foreground of the prediction mask. 掩膜化的feature计算方式如下:
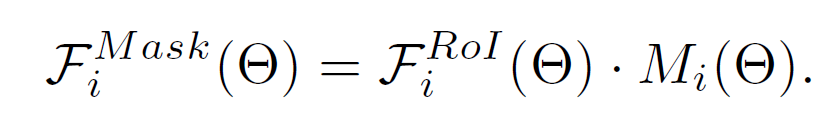
其中,元素级乘积的左边是RoI pooling之后的特征,右边是第二阶段的mask prediction. 可以看出乘积的结果Fi^Mask(*)依赖于Mi(*).将该feature输入给两路fc层。这是:mask-based pathway. 所给流程图中并未画出的一路是:box-based pathway,是将RoI pooling features直接输入到4096维的fc层。然后将mask-based pathway 和 box-based pathway 连接起来(concatenated)。紧接着是 N+1类的Softmax分类器,其中N类是物体,1类是背景。
第三个阶段的loss term是:
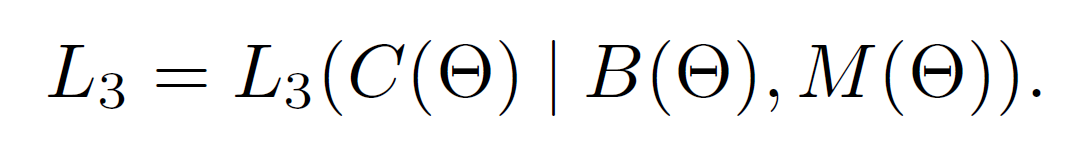
其中,C(*)是物体种类的预测结果。
2. End-to-End Training
总的级联的损失函数定义为:
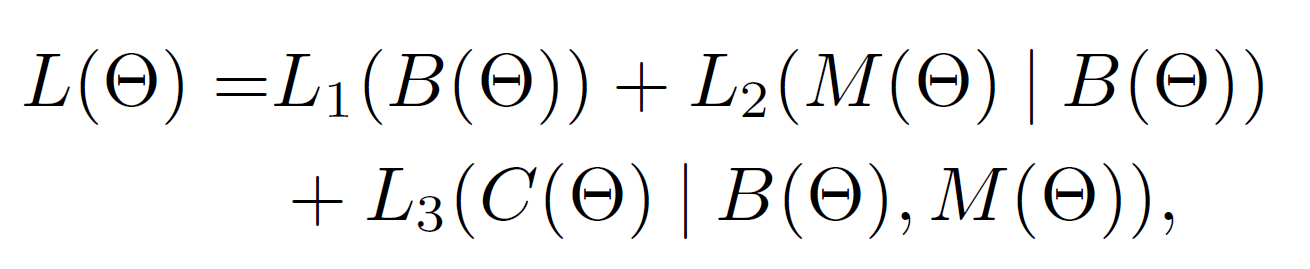
此处,该loss function并不像传统的multi-task learning,因为后一阶段的输入依赖于前一阶段的输出。例如:根据后向传播(BP)的链式法则,L2的梯度和B有关。对上述loss function采用链式法则的主要技术挑战在于:预测box Bi(*)决定RoI pooling的空间转换(spatial transformation)。对于RoI pooling层来说,其输入是预测的box B(*) 和 卷及特征映射 F(*),这两者都是*的函数。
在Fast R-CNN中,the box proposal 都是预先计算的且是固定的。RoI pooling的回传仅仅和F(*)有关,但是这个仅仅在B(*)不出现的情况下才可以。在End-to-End的训练过程中,这两项的梯度都要考虑。
本节提出了可微分的RoI warping layer来解决梯度问题,即:预测的box的位置和对B(*)的依赖。
3.Differentiable RoI Warping Layers.
作用:RoI Warping层裁剪特征图区域并通过插值将其扭曲为目标尺寸。
RoI pooling层基于框在离散网格上执行最大池化。导出一个可区分的形式在box位置,我们通过可区分的RoI Warping层执行RoI pooling,然后是标准最大池化层。
4. Cascades with More Stages
由于本文的目标不是box 而是 mask,所以作者将第三个阶段产生的 regressed boxes, 然后将这些boxes再看做是 proposals,然后在此基础上,再运行一次阶段2和3. 这实际上是一种5级的级联网络:

级联结构的损失函数为: