近期楼主带领一个团队,做公司产品V3到V4版本的重构工作。到17年3月份重构算是完成,紧接着老板就要求做性能测试(性能测试通过后才能在新版本中做新功能的迭代开发工作),做性能测试的基准点是重构前的V3版本是支持800并发的业务测试的(相同物理机器)。
楼主在刚参加工作的时候,有幸参加过性能测试工作中的测试工作,但是重来没有做过性能测试服务器端的性能问题分析、调优、提升的工作。刚开始开展工作的时候有点懵逼,不知道如何去做,更不知道做成什么样才算是性能测试OK。
万事开头难,在啥也不知道的时候,把性能测试脚本再V3版本上做一次性能测试,800并发2小时,CPU平均50%左右,V3版本妥妥的通过。 用相同的测试脚本,将服务器端的版本切换成V4版本,开始压力测试,并发到200的时候,CPU已经100%,性能测试工作无法进行下去。楼主就从此处开始详解性能测试过程中遇到的各种坑,以及如何解决这些坑的。
一:解决最明显的问题--部分业务太耗资源(花费2天时间)
描述:
楼主的V3到V4重构过程中并没有加入太多的新功能,照理说不太肯出现一下子如此大的性能差异。基于此点,楼主就依次注释掉最有可能影响性能的新功能,并重新打包走性能测试工作。
解决:
如此采用2分发的做法,根据业务与重构过程,新增加代码内容, 慢慢移除业务代码,最终找到Word2Vec(计算词向量模型)占CPU太高,去除本部分代码后,CPU占用在70%--90%左右,压力测试30分钟能够继续下去,但是接口相应时间与CPU占用资源比以前高。
二:性能测试的参数如何设置--设置多少内存?设置并发(花费5天时间)
基于系统架构思考压力测试方式与结论:
这是一个非常难获得结论,需要不断的尝试,楼主刚开始的时候是完全无从下手。先介绍一下楼主系统的结构。
楼主重构的系统不是一般的MS(资源管理的增删改查3层架构)系统,此系统采用领域对象模型中的充血模式很严重的架构设计。此系统需要管理在线访客的各种状态、生存周期、消亡等状态。在本系统的性能测试中,不同的并发数量、不同的测试策略 就会产生不同的访客数量,也就是涉及到如下两个非常重要的指标:在线访客数量(涉及到内存占用量),在线访客时长(涉及到不同GC工作机制)。
经过楼主3、4日的加班奋战,终于总结出适合本系统的压力测试并发测试和服务器性能指标。

压力测试客户端策略为:客户端每一个并发开始时会创建一个新访客与服务器做3次问答交互,3次问答交互后产生新的访客与服务器再做3次交互,如此往复循环(每一个并发每次交互间的间隔时间ThinkTime为2秒)。在此并发模式下,500并发时,服务器在线访客在4.3W左右,访客在线时长为15分钟,服务器内存占用峰值在5G左右;800并发时,服务器在线访客在6.5W左右,服务器内存占用峰值在6G左右。这里面的内存分配与回收策略非常难理解,楼主在充分考虑在线访客数量与在线访客时长才获得如上的资源分配策略。
PS结合GC策略做说明:一般MS系统,90%以上的GC操作都是Minor GC(新生代)操作,而Major GC(老年代) 和 Full GC触发的情况比较少(JAVA内存分配策略与GC工作方式参看楼主另外一个博文《Java虚拟机内存分配机制与启动参数说明》)。楼主本次性能测试系统拥有如上分析的特征,所以本系统的Minor GC会一直正常有,且本系统的Major GC(老年代)也会有规律的间断性的出现(因为众多的在线访客无法在新生代与中生代中被回收掉,当众多在线访客15分钟下线后,他们大部分都在老年代中,所以他们会在Major GC 和 Full GC中会被回收掉)。
PS多大内存为合适且正确:楼主记录下了服务器刚启动时,在线1个访客做交互,强制GC后的内存在1.3G左右,此时DMP出内存情况;在500并发过程中,强制GC后内存占用最高的时候DMP出内存5G左右;在访客全部下线后强制GC后内存占用1.3G左右。 此种结论说明,访客全部下线后占用内存能够全部释放,是正确的结论。 楼主再分析500并发过程中的内存占用情况,多余出来的内存的确是在线访客所占用的内存。
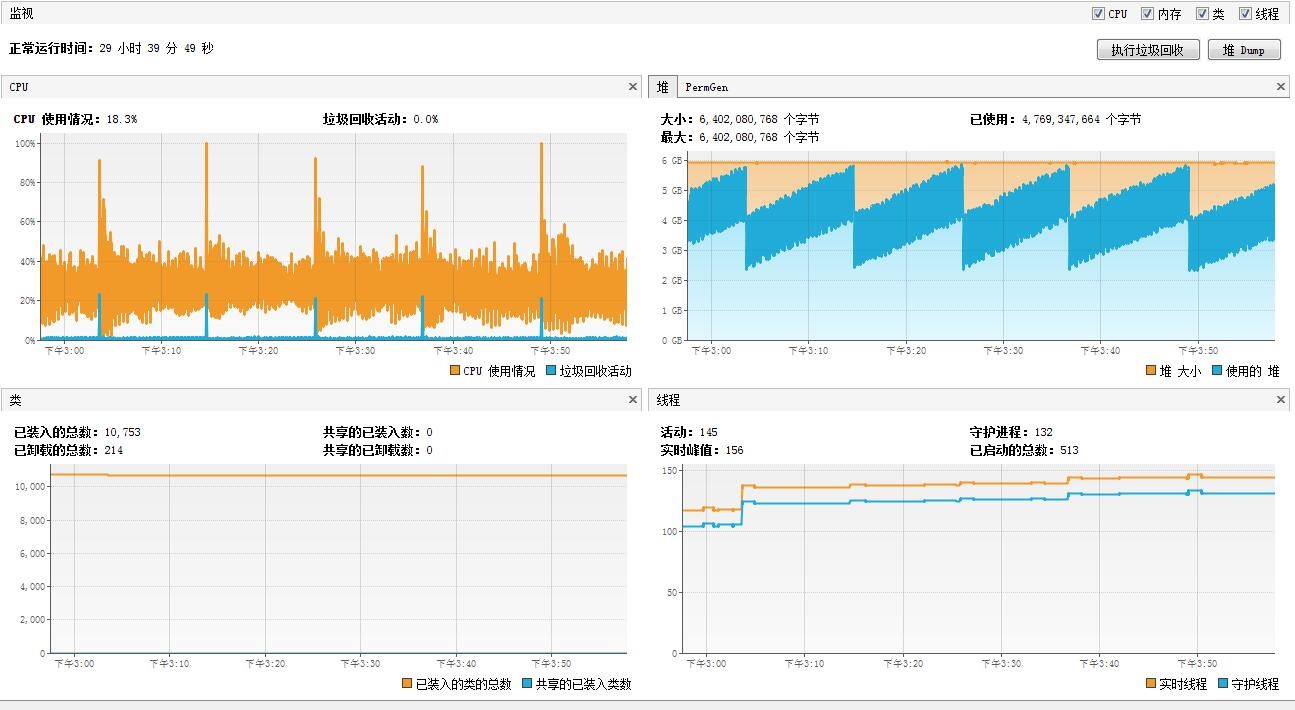
最终性能测试完整的效果图为(半个小时)(效果图简直太漂亮):
三:解决性能测试过程中的暗坑--非线程安全HashSet\HashMap坑
问题描述:
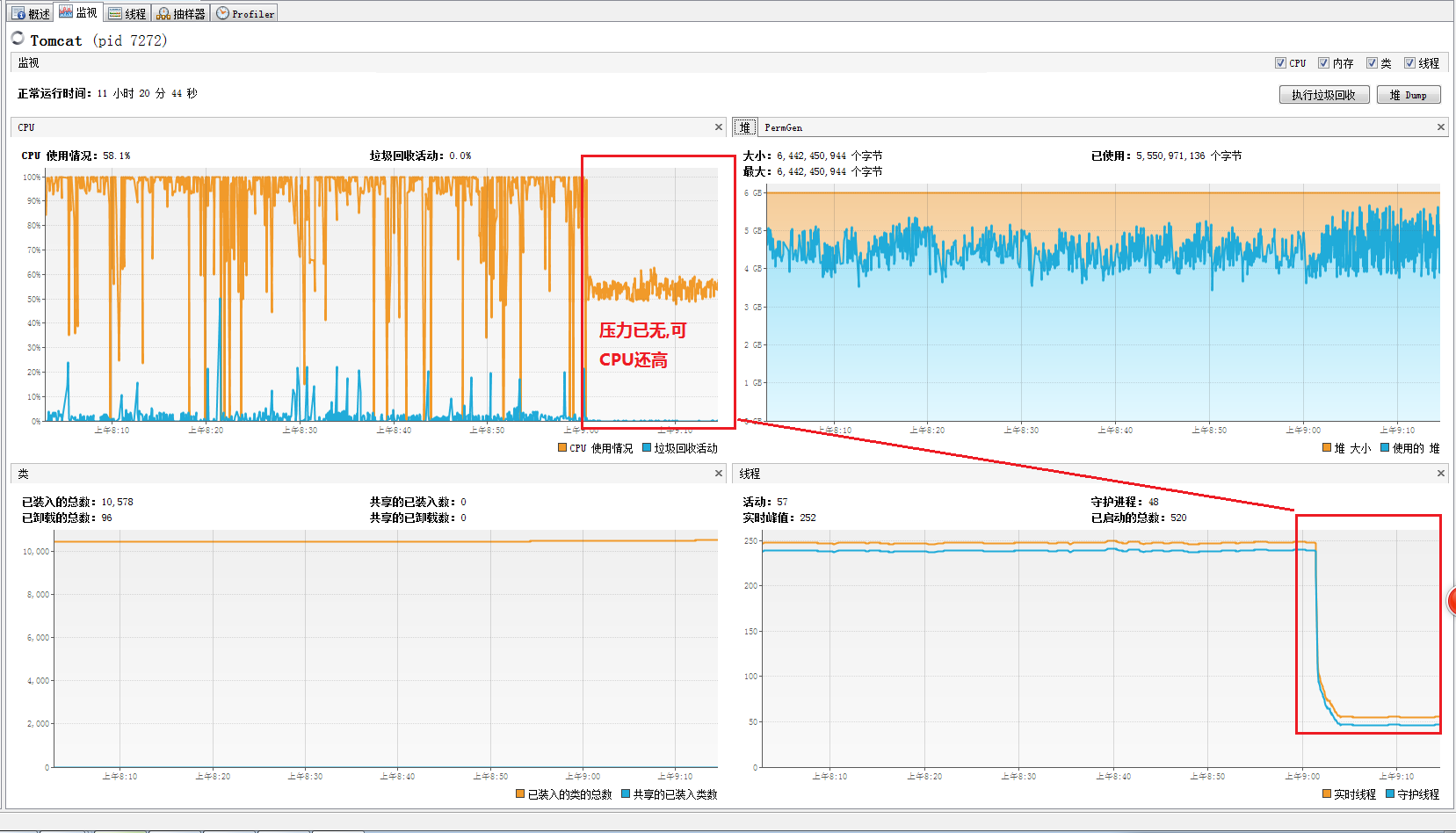
压测30分完成之后,所有业务请求都没有了,CPU依旧很高,应用过了很长一段时间(1个小时,1夜之后)CPU依旧很高(见下图)
分析过程:
这种情况只要再次做压力测试就能够复现,能够复现并且比较固定还算比较好解决.解决思路和方法如下(刚开始楼主也不知道如何解决这种问题,但是楼主以前看到过线程堆栈的相关知识,就想着用此方法来分析解决问题,最终方法此方法非常的好):
通过jstack命令导出Java进程的线程堆栈信息到文本文件中,通过工具(Win平台与Linux平台不一致,网上方法很多)查看到占用CPU最多的Java线程号,将十进制的线程号转成十六进制的线程号在导出的线程堆栈中找到本线程堆栈信息如下
"http-apr-8080-exec-79" daemon prio=6 tid=0x000000000f134000 nid=0x16b0 runnable [0x0000000022d3e000]
java.lang.Thread.State: RUNNABLE
at java.util.HashMap.put(HashMap.java:494)
at java.util.HashSet.add(HashSet.java:217)
at org.business.router.service.dispatch.MessageHandleFactory.addUserInfo(MessageHandleFactory.java:98)
at ....
通过本线程堆栈信息就能找到业务代码,就能找到问题代码(本问题的业务代码是at org.business.router.service... MessageHandleFactory.java:98).
解决方法:
通过如上线程堆栈信息也到业务代码,发现业务代码中用到了HashSet\HashMap作为类的共有成员变量,而HashSet\HashMap是非线程安全的, put操作,造成死锁, 用ConcurrentHashMap替代.
后续的要求:所有单例的私有成员集合变量,禁止使用非线程安全的集合,不然轻者数据不准确,重则造成集合.PUT()操作死循环,导致有应用线程一直死循环,永远在做集合.PUT()里面的代码.
原因详解:
HashSet底层是通过HashMap来实现的,而HashMap是通过链表解决Hash冲突的,因为链表结构,就很容易赵成闭合的链路,这样在循环的时候就会产生死循环.
底层会产生死循环的地方是HashMap的容量超过负载因子(0.75)的时候,会产生resize()扩容操作,resize()操作里面transfer()操作(转换相同HashCode的Entry[])产生的链表回路,导致死循环.
四:性能测试发现的巨坑--一个静态方法导致压测时间越长,CPU占用越高\内存使用越多
问题描述:
发现有一个接口,压测时间越长(2小时之后),CPU占用越高,内存使用越多,能回收的内存越来越少.
分析过程与解决方法:
这种问题很难解决,压测结束后CPU不高,就等于不能固定分析到占用CPU较高的线程,没有固定的CPU就很难发现CPU较高的工作线程堆栈.
没办法,只能尝试着去分析问题.在CPU几个小时之后,CPU与接口响应时间已经较高了,此时我随机10次打印线程堆栈到文本文件中,然后文件中状态为"RUNNABLE"的线程堆栈信息,这时能发现一些规律,
每次打印的线程堆栈中,都会有4-6个相同的业务堆栈信息如下,就是判断一个Map中是否包含一个Key,每次线程堆栈中都会有这样的业务堆栈就感觉很怪异了,需要仔细认真研读此方法的代码,
最终发现此方法会调用一个工具类静态方法,此工具类静态方法中有bug,每调用一次此方法,他就会往一个static ArrayList中增加20多条数据,而业务调用完此方法之后要遍历此ArrayList的数据,
结果导致随着压力测试时间的增加,此静态方法中的ArrayList数据量越大,越占用内存,遍历的时间也越长. 此种问题非常难排查,并且对系统的稳定性来说,是毁灭性的打击(压测2小时此ArrayList中数量在300W左右,占用内存在30M左右).
"http-apr-8080-exec-97" daemon prio=6 tid=0x000000000f134000 nid=0x16b0 runnable [0x0000000022d3e000]
java.lang.Thread.State: RUNNABLE
at java.util.HashMap.getEntry(HashMap.java:465)
at java.util.HashMap.contailsKey(HashMap.java:449)
at org.business.router.service.dispatch.OnLineUserModel.checkOnlineUser.(OnLineUserModel.java:98)
五:其他业务场景的优化
业务场景:
访客进来,数据库查此访客是否存在,不存在再在数据库新建一个.2个数据库交互
解决方法:
项目启动将已经之前入库的User进行缓存起来,后续访客进来之后,先去缓存中查找,存在直接使用,不存在创建入数据库入缓存,可以减少数据库交互次数
解决方法:
访客进来,会问5个问题,产生5个日志,问完之后离开,原本逻辑有一个问题日志就保存一次数据库,导致数据库操作台频繁
原因详解:
解决方法:将所有User产生日志放入到一个BlockQueue队列当中,单独启动一个线程做保存数据库操作,当满足如下条件做日志批量如数据库操作(一个Insert操作)
1)BlockQueue队列数据大于1000条开始保存批量保存1000条数据
2)BlockQueue队列不到1000条时,每1分钟保存一次
六:一个隐藏的小坑,导致完全不可以理解的loggre.error()日志;
一段代码如下所示
public void destoryMyself(){
if( null == this.user){
return;
}
user.destoryFriendModel();
user.destoryTeacherModel(); //这里会报null point exception
}此段代码在刚开始部分已经做了判空操作,从业务场景来说,此方法是由定时现场来跑的,都是单线程操作的,不可能出现那样的报错.
经过报错现象的仔细分析,唯一的可能性就是此方法被多个现场交叉执行了,通过详细查看配置文件,发现生成此工作项的定时线程主类被初始化了2此,最终导致两个定时线程跑此项任务,相互干扰了(一个线程在执行到判断user是否为空的时候CPU时间到了,交给另外一个线程执行,下一个线程刚好执行到本对象的后面的代码就发现了此情况)(一天有8个左右这种报错,一天在线访客5K左右).
总结
本次的性能测试方案,与服务器端性能测试解决分析,完全是楼主一个人进行,本次为期2、3周左右的加班加点的性能测试工作,将楼主以前学习、掌握的零碎的知识穿成了一条线,收获非常大。希望楼主的这些经验能够帮助到读者完成你们的服务器性能优化的工作,欢迎读者跟帖一起分析、解决你们的问题。