缓存是一种提高数据读取性能的技术,比如常见的cpu缓存以及浏览器缓存!但是缓存的大小有限,当缓存用满的时候,哪些数据应该被清理出去,哪些数据应该被保留?
解决方案:FIFO--->先进先出 LFU---> 最少使用 LRU-->最近最少使用
比方:买来很多技术书太占用书房空间了,这时候会选择扔掉一些书籍,但是采取啥样的策率呢?一般就是上面三种策率!
问题:如何使用链表实现LRU缓存淘汰策率呢?
1.五花八门的链表结构
1)数组与链表底层存储结构的对比
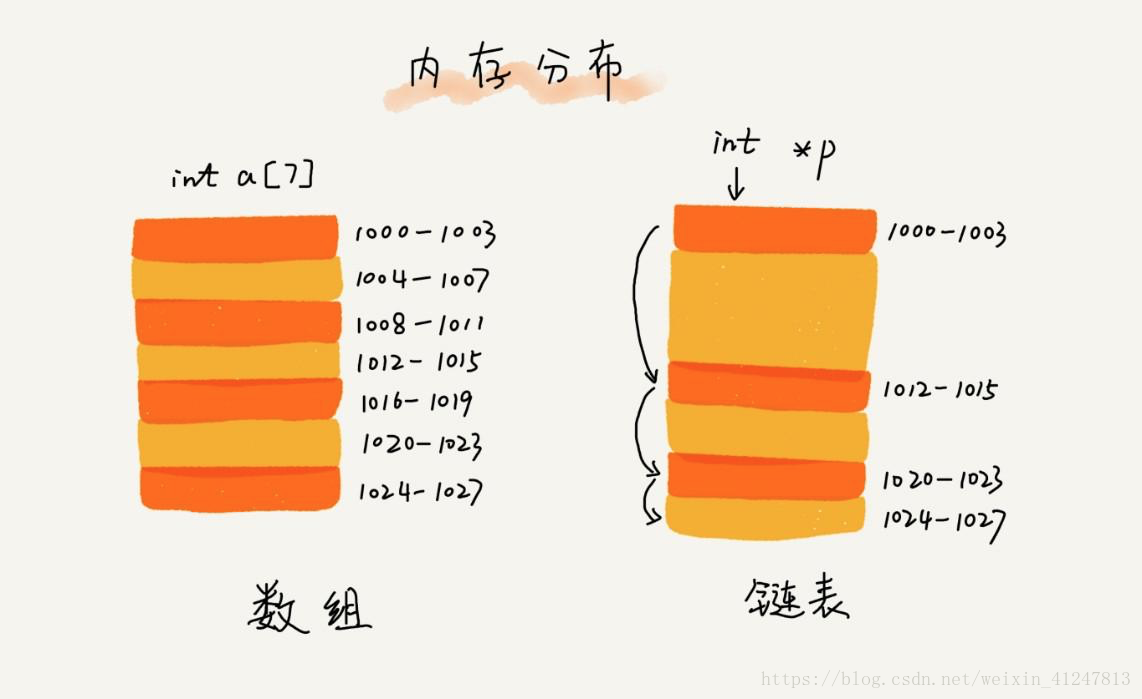
详解:数组需要一块连续的内存空间来存储,对内存的要求比较高。如果我们申请一个100M内存的大小的数组,当内存中没有连续足够大的空间时,即便内存中没有连续足够大的存储空间的时候,仍然会申请失败!而链表恰恰相反,它并不许呀一块连续的内存空间,它通过指针将一组零散的内存块串联起来使用,所以我们申请一个100MB大小的链表,根本不会有问题。
2)链表的分类
链表:通过指针将一组零散的内存快串联在一起,我们把内存块称为链表的节点,为了将所有节点都串起来,每个链表的节点除了存储数据之外,还需要记录下一个结点的地址。我们把这个记录下个结点地址的指针叫作后继指针next
11)单链表
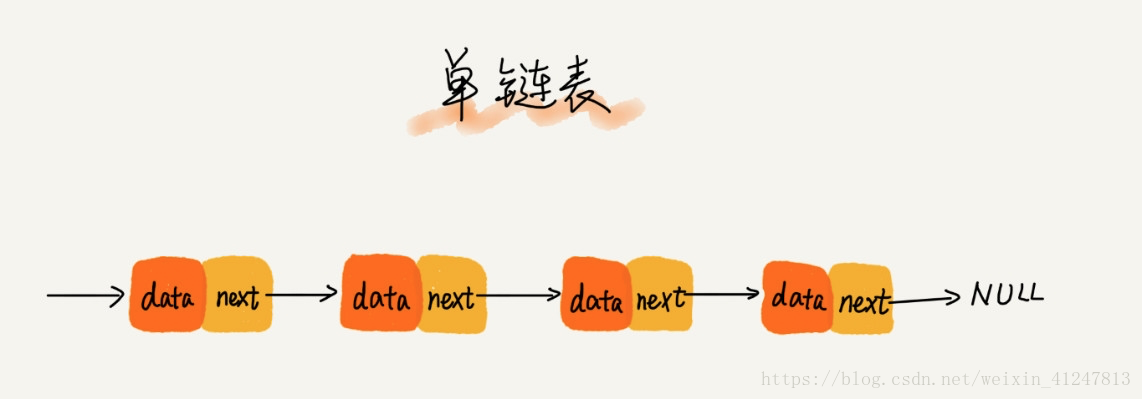
其中俩个节点比较特殊,分别是第一个节点和最后一个节点,我们把第一个结点叫作头结点,把最后一个节点叫作尾节点,头节点用来记录链表的基地址,有了它,就可以遍历整个链表。而尾节点特殊的地方是:指针不指向下一个结点,而是指向一个空地址null,表示这个是链表上最后一个结点。
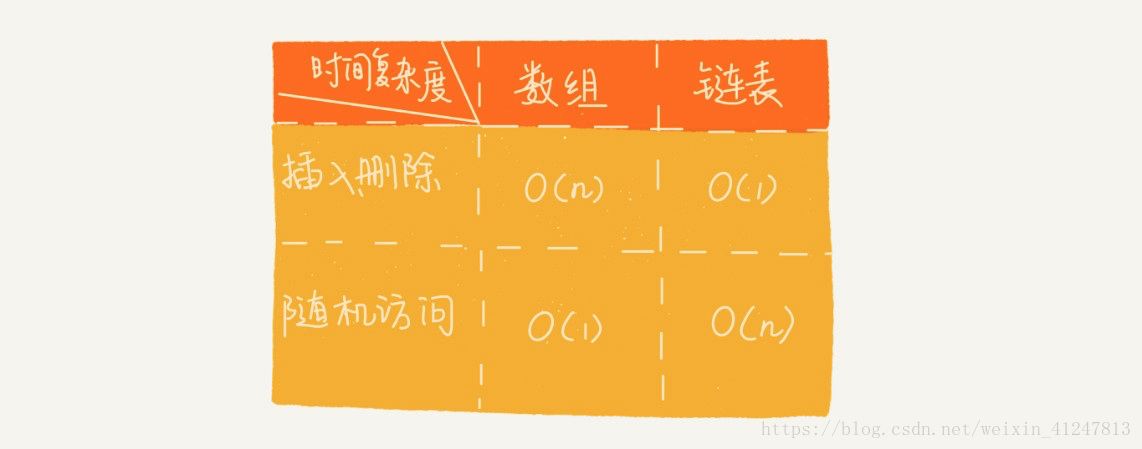
链表与数组相比,插入和删除(仅仅对本身单独的操作)效率更高,时间复杂度为O(1),数组时间复杂度为O(n)
22)循环链表
定义:是一种特殊的单链表,实际上链表也很简单,它和单链表唯一的区别就在尾结点,循环链表的尾结点指针是指向链表的头结点
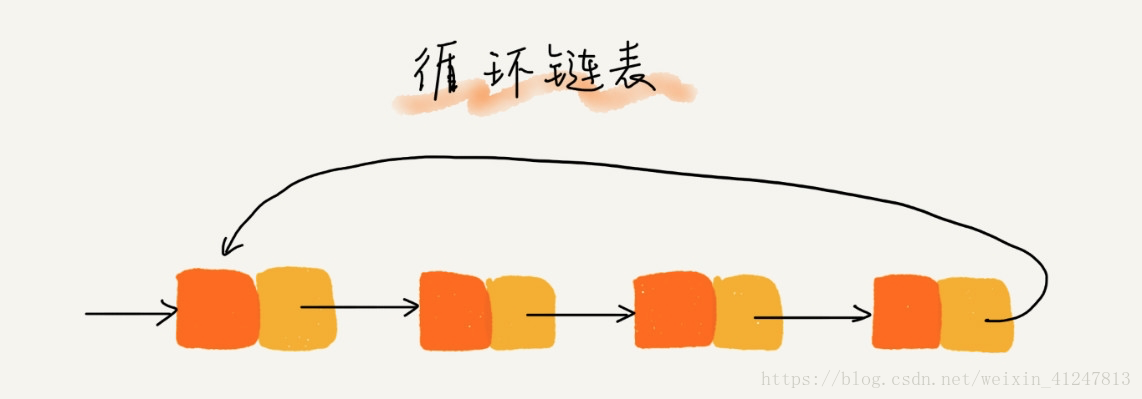
与单链表相比的优点:从链尾到链头比较方便,当要处理的数据具有环形结构特点的时候,就特别适合采用循环链表。
33)双向链表
单向链表只有一个方向,结点只有一个后继指针next指向后面的结点。而双向链表,顾名思义,它支持俩个方向,每个结点不止有一个后继指针next指向后面的结点,还有一个前继指针prev指向前面的结点。
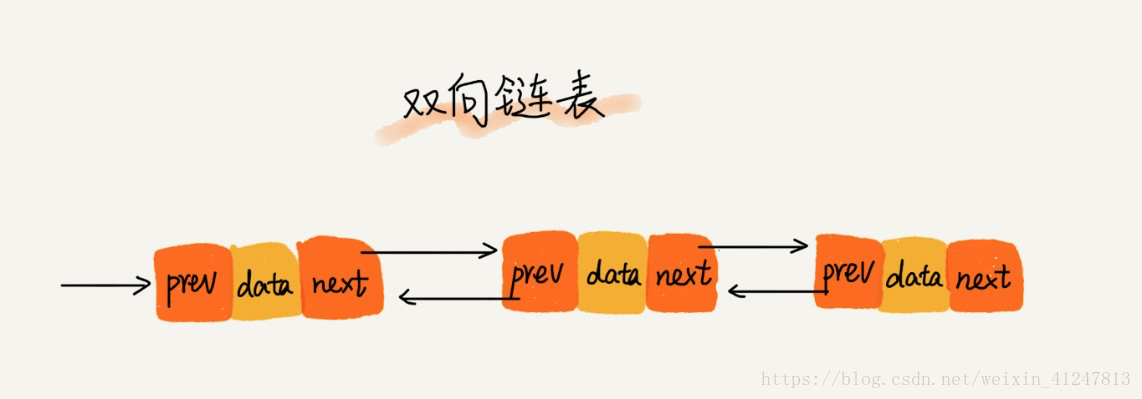
双向链表需要额外的俩个空间来存储后继结点和前驱结点的地址。所以,存储同样多的数据,双向链表要比单链表占用更多的存储空间。虽然俩个指针比较浪费存储空间,但可以支持双向遍历,这样给双向链表带来灵活性!
双向链表适合解决哪种问题呢?
双向链表可以支持O(1)时间复杂度的情况下,找到前驱结点,正是这样的特点使双向链表在某些情况下的插入删除更加的高效。
问题:单链表的插入和删除时间复杂度已经是O(1)呢?还怎么进行高效呢?
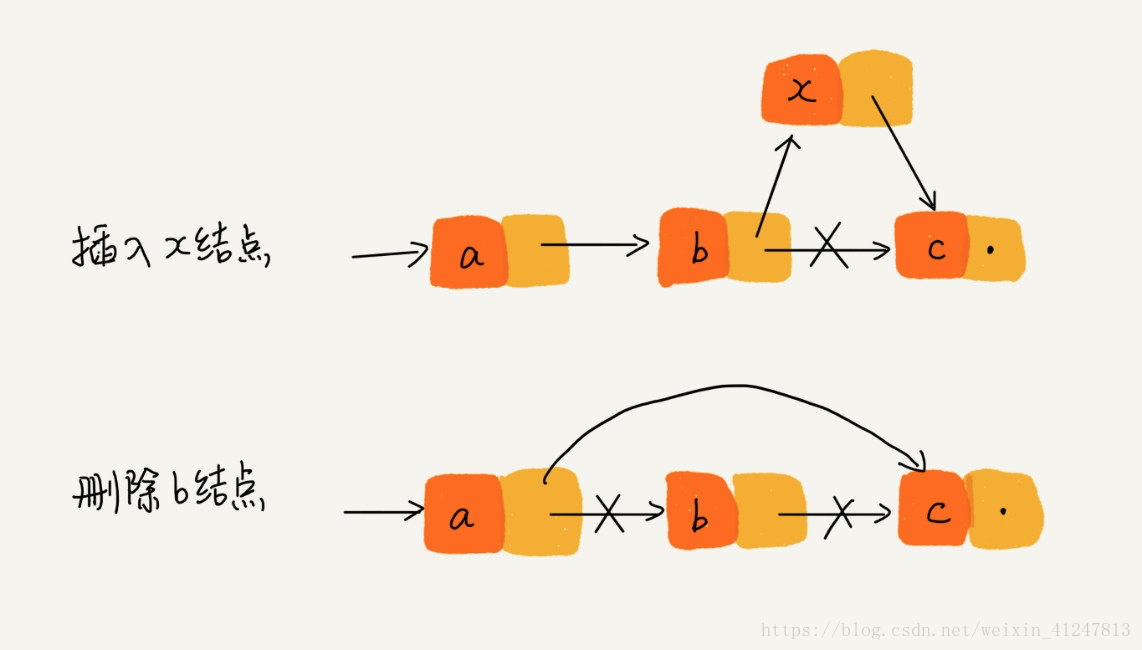
在实际的开发中,从链表中删除一个数据无外乎俩种情况:
.删除结点中 “值等于某个定值”的结点
.删除给定指针指向的结点
对于第一种情况,不管是单链表还是双链表,为了查找某个值等于给定值的结点,都需要从头开始一个一个一次遍历对比,直到找到值等于给定值的结点,然后再通过指针操作将其删除。尽管单纯的删除操作时间复杂度是O(1),但遍历查找的时间是主要的耗时点,对应的时间复杂度为O(n),所以删除值等于给定值的时间复杂度为O(n)
对于第二种情况,我们已经找到了要删除的结点,但是删除某结点需要知道其前驱结点,单链表是不支持获取前驱结点的,所以为了找到前驱结点,我们还是要从头开始去寻找,直到p--next=q,这个时候说明p是q的前驱结点。但是对于双向链表来说,因为双向链表中的结点已经保存了前驱结点的指针,不需要像单链表一样去遍历,所以俩者的复杂度分别为O(n)和O(1)
同样的对于插入操作,如果在某个指定结点之前插入一个值,双向链表对比单向链表也具有很大的优势,时间复杂度分别为O(1)和O(n)
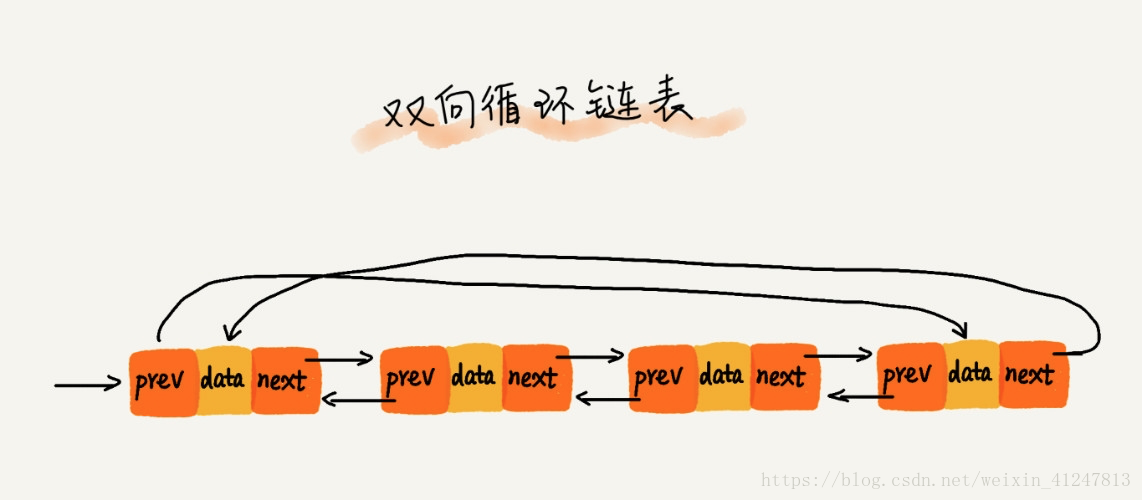
44)双向循环链表
3)链表数组大比拼
2.如何使用链表实现LRU缓存淘汰策率呢?
思路:
我们去维护一个有序单向链表,越靠近链表尾部的结点是越早之前访问的。当有一个新的数据被访问的时候,我们从头开始顺序遍历链表。
1)如果此数据之前已经被缓存在链表中了,我们遍历得到这个数据对应的结点,并将其从原来的位置删除,然后再插入到链表的头部。
2)如果此数据没有被缓存在链表中,又可以分为俩种情况:
11)如果此时缓存未满,则将此结点直接插入到链表的头部
22)如果此时缓存已满,则链表尾结点删除,将新的数据结点插入到链表的头部。