本篇博客参考https://blog.csdn.net/augusdi/article/details/12439805
1. 什么是CUDA?
CUDA全称是Compute Unified Device Architecture,中文名称即统一计算设备架构,它是NVIDIA公司提出了一种通用的并行计算平台和编程模型。使用CUDA,我们可以开发出同时在CPU和GPU上运行的通用计算程序,更加高效地利用现有硬件进行计算。为了简化并行计算学习,CUDA为程序员提供了一个类C语言的开发环境以及一些其它的如FORTRAN、DirectCOmpute、OpenACC的高级语言/编程接口来开发CUDA程序。
2. CUDA编程模型如何扩展?
我们知道,不同的GPU拥有不同的核心数目,在核心较多的系统上CUDA程序运行的时间较短,而在核心较少的系统上CUDA程序的执行时间较多。那么,CUDA是如何做到的呢?
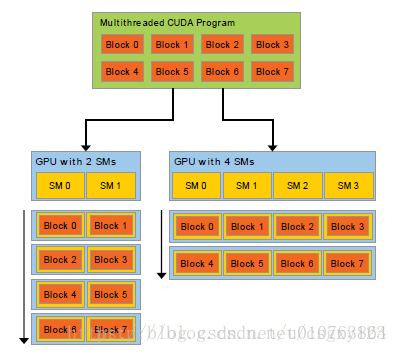
并行编程的中心思想是分而治之:将大问题划分为一些小问题,再把这些小问题交给相应的处理单元并行地进行处理。在CUDA中,这一思想便体现在它的具有两个层次的问题划分模型。一个问题可以首先被粗粒度地划分为若干较小的子问题,CUDA使用被称为块(Block)的单元来处理它们,每个块都由一些CUDA线程组成,线程是CUDA中最小的处理单元,将这些较小的子问题进一步划分为若干更小的细粒度的问题,我们便可以使用线程来解决这些问题了。对于一个普通的NVIDIA GPU,其CUDA线程数目通常能达到数千个甚至更多,因此,这样的问题划分模型便可以成倍地提升计算机的运算性能。
GPU是由多个流水多处理器构成的,流水处理器以块(Block)为基本调度单元,因此,对于流水处理器较多的GPU,它一次可以处理的块(Block)更多,从而运算速度更快,时间更短。而反之对于流水处理器较少的GPU,其运算速度便会较慢。这一原理可以通过下图形象地看出来:
3.主机和设备
CUDA 编程模型将CPU作为主机(Host),GPU作为协处理器或者设备(Device),在一个系统中可以存在一个主机和若干个设备。
在这个模型中,CPU与CPU协同工作,各司其职。CPU负责进行逻辑性强的事物处理和串行计算,GPU则专注于执行高度线程化的并行处理任务。CPU、GPU各自拥有相互独立的存储器地址空间:主机端的内存和设备端的显存。
一旦确定了程序的并行部分,就可以考虑把这部分计算工作交给GPU。
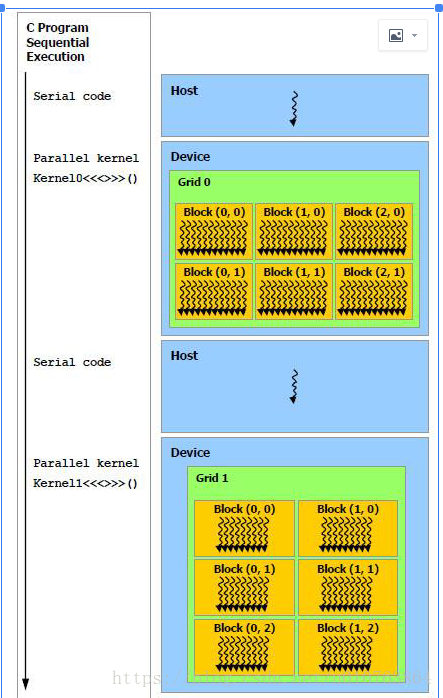
能够使用GPU计算的程序必须具有以下特点:需要处理的数据量比较大,数据以数组或矩阵形式有序存储,并且对这些数据要进行的处理方式基本相同,各个数据之间的依赖性或者说耦合很小,需要复杂数据结构的计算如树,图等,则不适用于使用GPU进行计算。找到程序中满足这些要求的部分后,就能将该部分程序移植GPU上。运行在GPU上的程序被称为内核(Kernel)。内核并不是完整的程序,只是整个程序中的一个可以使用数据并行处理的步骤。一个完整的程序由若干个内核函数以及CPU上的串行处理共同组成。一个完整的程序的计算流程如下所示:
Cuda 入门理论
猜你喜欢
转载自blog.csdn.net/u010763864/article/details/82119511
今日推荐
周排行