从前面的文章(MapReduce运行原理【源码跟踪】)我们知道计算切片的部分在JobSubmitter类中,然后我们看此类的Structure(在idea中View->Tool Windows ->Structure)查看类结构我们很轻易的就能找到有关split的方法
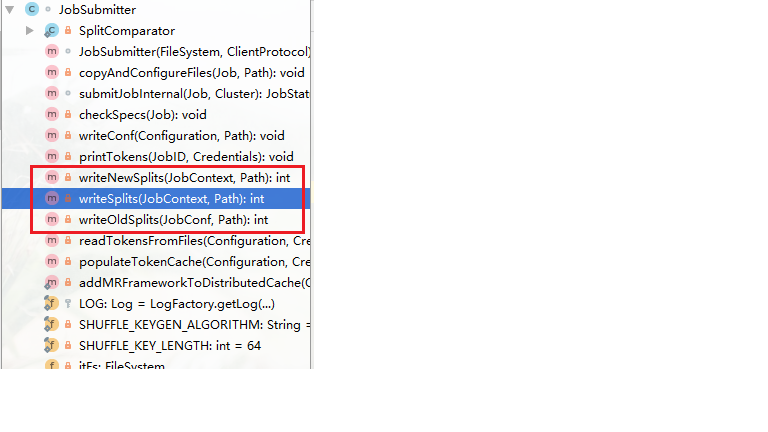
我们可以在writeSplits方法中打一个断点,随便运行一个计数程序Debug跟踪查看。
这里给出一下计数程序
WCmapper
1 package com.qin.MapReduce;
2
3 import org.apache.hadoop.io.IntWritable;
4 import org.apache.hadoop.io.LongWritable;
5 import org.apache.hadoop.io.Text;
6 import org.apache.hadoop.mapreduce.Mapper;
7
8 import java.io.IOException;
9
10 public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
11
12 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
13 Text outText = new Text();
14 IntWritable valueOut = new IntWritable();
15 String[] split = value.toString().split(" ");
16 for (String str: split ){
17 outText.set(str);
18 valueOut.set(1);
19 context.write(outText,valueOut);
20 }
21 }
22
23 }
WCreducer
package com.qin.MapReduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WCreducer extends Reducer<Text, IntWritable, Text, IntWritable>{
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values){
count = value.get() + count;
}
context.write(key, new IntWritable(count));
}
}
WCapp
package com.qin.MapReduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WCapp {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","file:///");
Job job = Job.getInstance(conf);
//Job的各种属性
job.setJobName("WCapp"); //设置作业名称
job.setJarByClass(WCapp.class); //设置搜索类
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCreducer.class);
job.setNumReduceTasks(1);
//添加输入路径
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true); //是否打印出详细信息
}
}
Debug运行以后,Step over到 maps = this.writeNewSplits(job, jobSubmitDir);的地方时
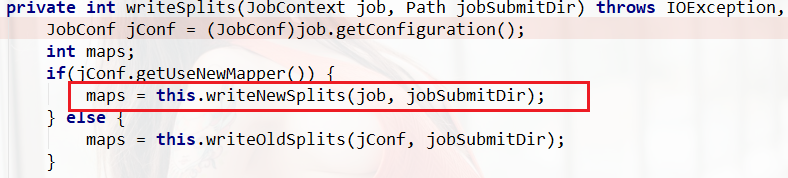
我们Step Into进去看看
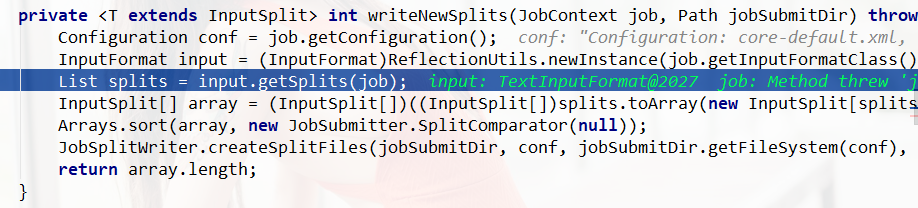
多次Step over到 List splits = input.getSplits(job);我们再次Step into

这里我们看见minSize是取两个参数中最大值。我们通过鼠标放在某个参数上Alt+鼠标左键看属性的详细定义,知道this.getFormatMinSplitSize()的值为1,
getMinSplitSize(job)是得到配置文件mapred-default.xml中的mapreduce.input.fileinputformat.split.minsize的值
默认配置图如下

所以minSize的值为1
然后我们在step over 然后step into到getMaxSplitSize(job)中

我们很容易就知道maxSize是long型的最大值
maxSize=9223372036854775807L
继续向下看

这里我们知道blockSize1在得到块大小。
blockSize1 = 33554432
进入到this.computeSplitSize()中看它是如何计算得到splitSize的

blockSize1 maxSize blockSize我们都得到了
一分析computeSplitSize方法,我们知道得到的是三个值的中间值。
总结:默认情况下,切片大小跟块大小是一样大
切片大小跟块大小一样的好处:
如果我们定义splitSize是1M,那么一块128M,切成128个split,分发到网络上128个结点同时运行(可以一个结点运行多个切片,但是集群并发情况下,负载均衡,系统会自动分发给其它结点),浪费时间与资源。
如果我的splitSize和块大小相同,直接就在本结点上运行了(nodemanage的本地优先策略)。