sparkstreaming的窗口函数:
窗口函数的作用主要是计算一段时间之内的数据的变化,那么就会有人产生疑问,为什么窗口与窗口之间需要重叠呢?
其实不重叠也是可以的,但是如果不重叠的话,将来做出来的报表一个时间段与另一个时间段的数据就会产生剧烈的变化。
窗口函数可以让我们一下子操作多个批次。

上面这些就是窗口函数,那么我们怎么用呢?
我们这里举个例子:
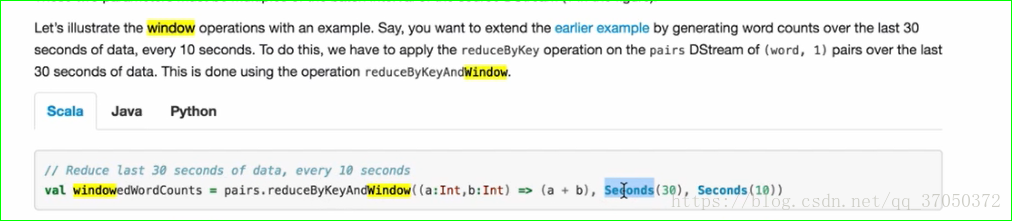
如果我们想使用reduceByKeyAndWindow的话,首先我们需要一个DStream,并且这个里面装的是键值对。
这里的Seconds(30)是窗口的间隔,Seconds(10)是滑动的间隔。
而且这两个间隔必须是生成批次的时间间隔。
假如生成批次的时间间隔是5秒,那么窗口就是6个,滑动就是2个。
那么我们如何将数据写到外部的存储介质(比如hdfs,redis,mysql...)?
我们可以通过foreachRDD.我们来看一下:
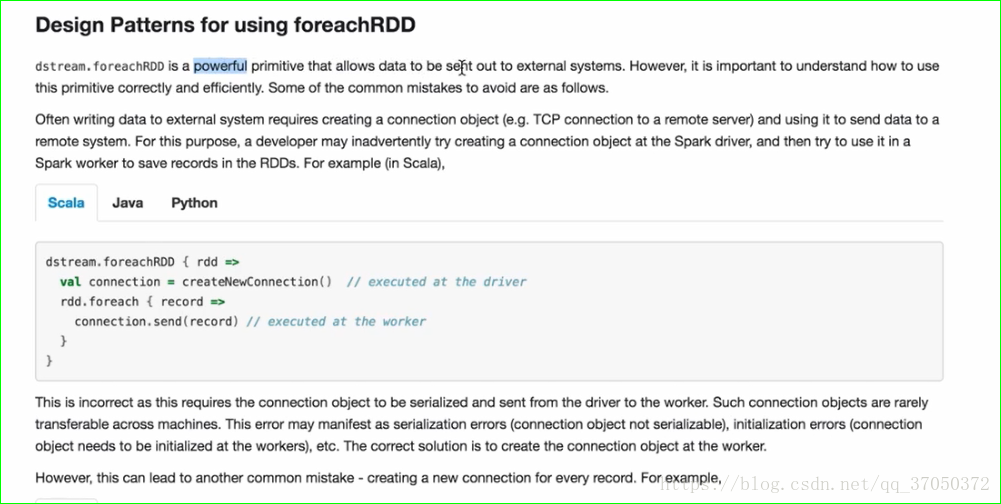
这段话的意思就是DStream的foreachRDD方法是一个强大的功能,他允许我们将数据写到外部系统中。
上面的这个方法中我们可以拿到一个批次对应的RDD,那我们为什么一次拿出来一个RDD呢?
因为他每隔一段时间生成一个RDD。我们在拿到一个RDD之后,首先拿到一个外部系统的连接。
拿到连接之后,将RDD里面的数据通过foreach写入。
这种方法其实并不好!
为什么这么说?因为RDD中有很多分区。而RDD中有很多的数据,这些数据是分散在多台机器上的。
一个RDD只有一个连接,所以他会将这个连接通过网络序列化到其他的机器上。
所以这种方式并不好。
接下来我们再看一看稍微好点的方式:
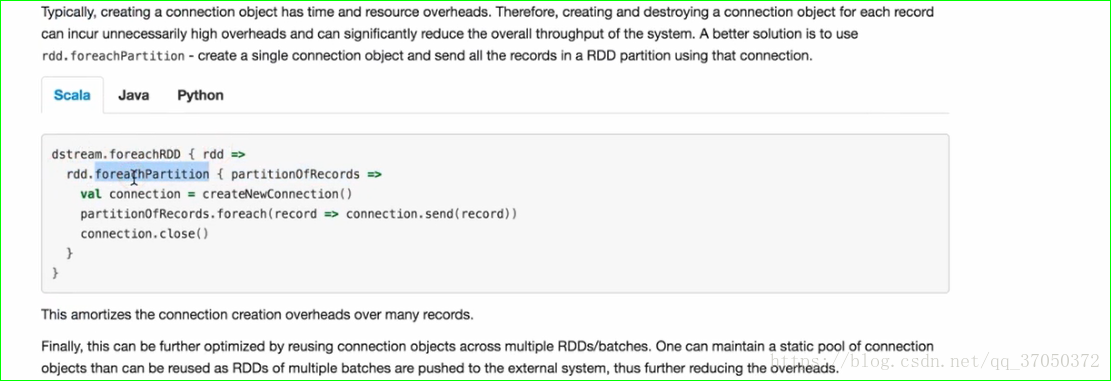
这里我们先通过foreachPartition拿到一个分区。然后每个分区拿一个连接。然后分区里面的数据再通过foreach写入。
但是这种方式还是不够好!
最好的方式是接下来的。
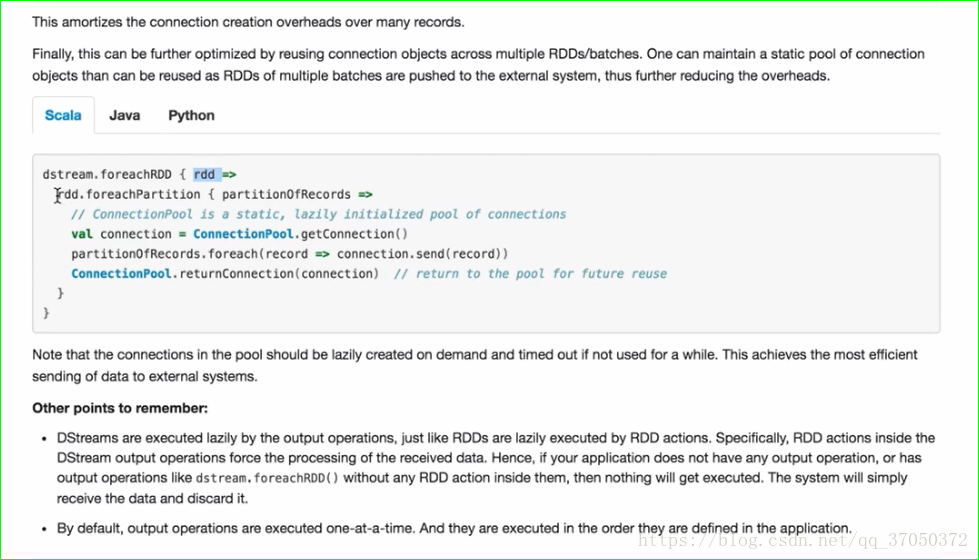
这种方式先拿到一个分区,接下来通过一个连接池拿到一个连接。
接下来这个分区中的数据使用这一个连接,用完之后再将这个连接还回去。