GoogLeNet网络核心模块是Inception module,一共经历了4代,其中第一代网络获得了2014年ILSVRC竞赛的分类任务第一名,因此促使了研究者对Inception module的兴趣,使Inception module不断完善。而这次比赛的第二名大家也很熟悉,就是VGGNet。
Inception V1
出发点
一般来说,提升网络性能最直接的方法就是增加网络的深度和宽度。但是这也带来两个问题:一是网络参数量的急剧增加会导致网络陷入过拟合,尤其是对小数据集而言;二是消耗巨大的计算资源。
文章认为解决上述两个问题的根本方法是将全连接甚至卷积转化为稀疏连接。对这个观点有两方面解释:一方面,现实中的生物神经网络连接本身就是稀疏的;另一方面,Arora等人证明,对于大规模的稀疏网络,可通过分析前一层激活值的相关统计数据和对高度相关的输出神经元聚类来逐层构建最优的网络结构。这种方法可以在不损失性能的前提下降低网络参数量。
实际上,传统的网络基本都使用了随机稀疏连接。但是,计算机对非均匀稀疏数据的计算非常低效,所以在AlexNet中又重新使用了全连接层,目的是就为了更好地进行并行运算。
那么问题来了,是不是有一种方法既能够保持网络结构的稀疏性,并且充分利用密集矩阵的高效计算?还真有。大量文献表明对稀疏矩阵进行聚类为密集矩阵可以提高性能。Inception module就是基于这种思想提出来的。
网络描述
下图为Google提出的Inception module的基本结构:

该结构采用了四个分支,每个分支分别由1x1卷积、3x3卷积、5x5卷积和3x3max pooling组成,既增加了网络的宽度,也增加了网络对不同尺度的适用性。四个分支输出后在通道维度上进行叠加,作为下一层的输入。四个分支输出的feature map的尺寸可由padding的大小进行控制,以保证它们的特征维度相同(不考虑通道数)。
但是,3x3和5x5卷积依然会带来很大的计算量。受Network in Network的启发,作者使用1x1卷积对特征图厚度进行降维,这就是Inception v1的网络结构,如下:

基于Inception的GoogLeNet网络结构如下:
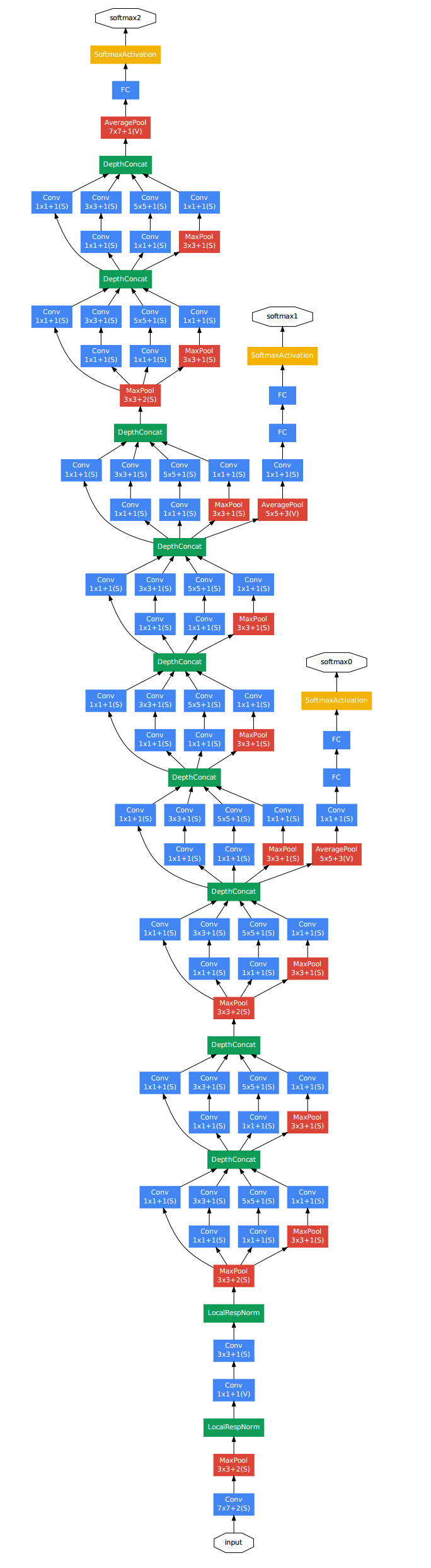
GoogLeNet一共包含22层,网络参数量只有Alexnet的1/12。但是随着网络层数的加深,梯度弥散的问题依然存在,所以作者在中间层加入两个辅助的softmax,以此增加反向传播的梯度大小,同时也起到了正则化的作用。在计算网络损失的时候,中间的辅助softmax loss会乘以一个权重(0.3)加入到最后层的loss值中。在预测时,则忽略中间softmax层的输出。
代码实现
这部分通过keras实现Inception v1网络结构:
from keras.layers import Input
from keras.layers import Conv2D, MaxPool2D, concatenate
from keras.models import Model
from keras.utils import plot_model
def inception_v1(input_shape=(10,10,128)):
"""
build inception block using keras with TensorFlow backend.
:param input_shape: input shape of block
:return: inception_v1 block output
"""
input_ = Input(shape=input_shape)
# 构建inception的每个branch,大家可以尝试把branch2和branch3的1x1卷积去掉,比较一下网络参数量的变化
branch_1 = Conv2D(128, kernel_size=(1, 1), strides=(1, 1), activation='relu', padding='same')(input_)
branch_2 = Conv2D(32, kernel_size=(1, 1), strides=(1, 1), activation='relu', padding='same')(input_)
branch_2 = Conv2D(128, kernel_size=(3, 3), strides=(1, 1), activation='relu', padding='same')(branch_2)
branch_3 = Conv2D(32, kernel_size=(1, 1), strides=(1, 1), activation='relu', padding='same')(input_)
branch_3 = Conv2D(128, kernel_size=(5, 5), strides=(1, 1), activation='relu', padding='same')(branch_3)
branch_4 = MaxPool2D(pool_size=(3, 3), strides=(1, 1), padding='same')(input_)
branch_4 = Conv2D(128, kernel_size=(1, 1), strides=(1, 1), activation='relu', padding='same')(branch_4)
output_ = concatenate([branch_1, branch_2, branch_3, branch_4], axis=3)
# 这里使用Model构建模型是为了直观的显示inception v1的结构,在实际使用中输入参数应为上一层的输出,返回值为当前层的输出
model = Model(input_, output_)
model.summary()
return model
if __name__ == '__main__':
model = inception_v1()
plot_model(model, 'Inception_v1.png', show_shapes=True) # 保存模型图