参考文档如下:
https://jasper-zhang1.gitbooks.io/influxdb/content/
InfluxDB是一个用于存储和分析时间序列数据的开源数据库。
主要特性有:
- 内置HTTP接口,使用方便
- 数据可以打标记,查让查询可以很灵活
- 类SQL的查询语句
- 安装管理很简单,并且读写数据很高效
- 能够实时查询,数据在写入时被索引后就能够被立即查出
- ……
本文按照如下顺序介绍influxdb:
- 1、概念介绍
- 2、快速入门
- 3、Influx HttpAPI
- 4、InfluxQL查询语言
1、概念介绍
| field value | field key | field set |
|---|---|---|
| tag value | tag key | tag set |
| timestamp | measurement | retention policy |
| series | point | database |
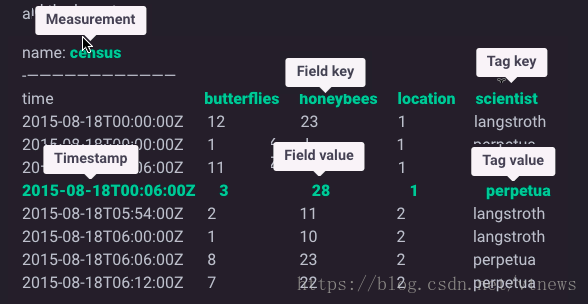
timestamp:time存着时间戳,这个时间戳以RFC3339格式展示了与特定数据相关联的UTC日期和时间。
field set:每组field key和field value的集合,如butterflies = 3, honeybees = 28
field key/value:在InfluxDB中不能没有field,field没有索引。
tag set:不同的每组tag key和tag value的集合,如location = 1, scientist = langstroth
tag key/value:在InfluxDB中可以没有tag,tag是索引起来的。
measurement: 是一个容器,包含了列time,field和tag。概念上类似表。
retention policy:单个measurement可以有不同的retention policy。measurement默认会有一个autogen的保留策略,autogen中的数据永不删除且备份数replication为1(只有一份数据,在集群中起作用)。
series:series是共同retention policy,measurement和tag set的集合。如下:
| 任意series编号 | retention policy | measurement | tag set |
|---|---|---|---|
| series 1 | autogen | census | location = 1,scientist = langstroth |
| series 2 | autogen | census | location = 2,scientist = langstroth |
| series 3 | autogen | census | location = 1,scientist = perpetua |
| series 4 | autogen | census | location = 2,scientist = perpetua |
point:point是具有相同timestamp、相同series(measurement,rp,tag set相同)的field。这个点在此时刻是唯一存在的。 相反,当你使用与该series中现有点相同的timestamp记将新point写入同一series时,该field set将成为旧field set和新field set的并集。
1.1、专业术语
省略了一些简单的术语。按字母排序,可以跳过。
### batch
用换行符分割的数据点的集合,这批数据可以使用HTTP请求写到数据库中。用这种HTTP接口的方式可以大幅降低HTTP的负载。尽管不同的场景下更小或更大的batch可能有更好地性能,InfluxData建议每个batch的大小在5000~10000个数据点。
### continuous query(CQ)
这个一个在数据库中自动周期运行的InfluxQL的查询。Continuous query在select语句里需要一个函数,并且一定会包含一个GROUP BY time()的语法。
### duration
retention policy中的一个属性,决定InfluxDB中数据保留多长时间。在duration之前的数据会自动从database中删除掉。
### function
包括InfluxQL中的聚合,查询和转换,可以在InfluxQL函数中查看InfluxQL中的完整函数列表。
### identifier
涉及continuous query的名字,database名字,field keys,measurement名字,retention policy名字,subscription 名字,tag keys以及user 名字的一个标记。
### line protocol
写入InfluxDB时的数据点的文本格式。如:cpu,host=serverA,region=us_west value=0.64
### metastore
包含了系统状态的内部信息。metastore包含了用户信息,database,retention policy,shard metadata,continuous query以及subscription。
### node
一个独立的influxd进程。
### now()
本地服务器的当前纳秒级时间戳。
### query
从InfluxDB里面获取数据的一个操作
### replication factor
retention policy的一个参数,决定在集群模式下数据的副本的个数。InfluxDB在N个数据节点上复制数据,其中N就是replication factor。
replication factor在单节点的实例上不起作用
### retention policy(RP)
InfluxDB数据结构的一部分,描述了InfluxDB保存数据的长短(duration),数据存在集群里面的副本数(replication factor),以及shard group的时间范围(shard group duration)。RPs在每个database里面是唯一的,连同measurement和tag set定义一个series。
当你创建一个database的时候,InfluxDB会自动创建一个叫做autogen的retention policy,其duration为永远,replication factor为1,shard group的duration设为的七天。
### schema
数据在InfluxDB里面怎么组织。InfluxDB的schema的基础是database,retention policy,series,measurement,tag key,tag value以及field keys。
### series cardinality
在InfluxDB实例上唯一database,measurement和tag set组合的数量。
例如,假设一个InfluxDB实例有一个单独的database,一个measurement。这个measurement有两个tag key:email和status。如果有三个不同的email,并且每个email的地址关联两个不同的status,那么这个measurement的series cardinality就是6(3*2=6):
| status | |
|---|---|
| [email protected] | start |
| [email protected] | finish |
| [email protected] | start |
| [email protected] | finish |
| [email protected] | start |
| [email protected] | finish |
注意到,因为所依赖的tag的存在,在某些情况下,简单地执行该乘法可能会高估series cardinality。 依赖的tag是由另一个tag限定的tag并不增加series cardinality。 如果我们将tagfirstname添加到上面的示例中,则系列基数不会是18(3 * 2 * 3 = 18)。 它将保持不变为6,因为firstname已经由email覆盖了:
| status | firstname | |
|---|---|---|
| [email protected] | start | lorraine |
| [email protected] | finish | lorraine |
| [email protected] | start | marvin |
| [email protected] | finish | marvin |
| [email protected] | start | clifford |
| [email protected] | finish | clifford |
### server
一个运行InfluxDB的服务器,可以使虚拟机也可以是物理机。每个server上应该只有一个InfluxDB的进程。
### shard
shard包含实际的编码和压缩数据,并由磁盘上的TSM文件表示。 每个shard都属于唯一的一个shard group。多个shard可能存在于单个shard group中。每个shard包含一组特定的series。给定shard group中的给定series上的所有点将存储在磁盘上的相同shard(TSM文件)中。
### shard duration
shard duration决定了每个shard group跨越多少时间。具体间隔由retention policy中的SHARD DURATION决定。
例如,如果retention policy的SHARD DURATION设置为1w,则每个shard group将跨越一周,并包含时间戳在该周内的所有点。
### shard group
shard group是shard的逻辑组合。shard group由时间和retention policy组织。包含数据的每个retention policy至少包含一个关联的shard group。给定的shard group包含shard group覆盖的间隔的数据的所有shard。每个shard group跨越的间隔是shard的持续时间。
### subscription
subscription允许Kapacitor在push model中接收来自InfluxDB的数据,而不是基于查询数据的pull model。当Kapacitor配置为使用InfluxDB时,subscription将自动将订阅的数据库的每个写入从InfluxDB推送到Kapacitor。subscription可以使用TCP或UDP传输写入。
### tsm(Time Structured Merge tree)
InfluxDB的专用数据存储格式。 TSM可以比现有的B+或LSM树实现更大的压缩和更高的写入和读取吞吐量。
### user
在InfluxDB里有两种类型的用户:
- admin用户对所有数据库都有读写权限,并且有管理查询和管理用户的全部权限。
- 非admin用户有针对database的可读,可写或者二者兼有的权限。
当认证开启之后,InfluxDB只执行使用有效的用户名和密码发送的HTTP请求。
### values per second
对数据持续到InfluxDB的速率的度量,写入速度通常以values per second表示。
要计算每秒速率的值,将每秒写入的点数乘以每点存储的值数。 例如,如果这些点各有四个field,并且每秒写入batch是5000个点,那么values per second是每点4个field x 每batch 5000个点 x 10个batch/秒=每秒200,000个值。
### wal(Write Ahead Log)
最近写的点数的临时缓存。为了减少访问永久存储文件的频率,InfluxDB将最新的数据点缓冲进WAL中,直到其总大小或时间触发然后flush到长久的存储空间。这样可以有效地将写入batch处理到TSM中。
可以查询WAL中的点,并且系统重启后仍然保留。在进程开始时,在系统接受新的写入之前,WAL中的所有点都必须flushed。
1.2、与关系型数据库比较
### 一般来说
InfluxDB用于存储大量的时间序列数据,并对这些数据进行快速的实时分析。SQL数据库也可以提供时序的功能,但时序并不是其目的。
在InfluxDB中,timestamp标识了在任何给定数据series中的单个点。就像关系型数据库中的主键。
InfluxDB考虑到schema可能随时间而改变,因此赋予了其便利的动态能力。比如只需要在新的数据line中加入所需的值,cpu,host=serverA,region=us_west,newTag=aa value=0.64,newValue=bbb
### 更形象一点
下表是一个叫foodships的SQL数据库的例子,并有没有索引的#_foodships列和有索引的park_id,planet和time列。
| park_id | planet | time | _foodships |
|---|---|---|---|
| 1 | Earth | 1429185600000000000 | 0 |
| 1 | Earth | 1429185601000000000 | 3 |
| 1 | Earth | 1429185602000000000 | 15 |
| 1 | Earth | 1429185603000000000 | 15 |
| 2 | Saturn | 1429185600000000000 | 5 |
| 2 | Saturn | 1429185601000000000 | 9 |
| 2 | Saturn | 1429185602000000000 | 10 |
| 2 | Saturn | 1429185603000000000 | 14 |
这些数据在InfluxDB看起来就像这样:
name: foodships
tags: park_id=1, planet=Earth
time #_foodships
---- ------------
2015-04-16T12:00:00Z 0
2015-04-16T12:00:01Z 3
2015-04-16T12:00:02Z 15
2015-04-16T12:00:03Z 15
name: foodships
tags: park_id=2, planet=Saturn
time #_foodships
---- ------------
2015-04-16T12:00:00Z 5
2015-04-16T12:00:01Z 9
2015-04-16T12:00:02Z 10
2015-04-16T12:00:03Z 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
参考上面的数据,一般可以这么说:
- InfluxDB的measurement(
foodships)和SQL数据库里的table类似; - InfluxDB的tag(
park_id和planet)类似于SQL数据库里索引的列; - InfluxDB中的field(
#_foodships)类似于SQL数据库里没有索引的列; - InfluxDB里面的数据点(例如
2015-04-16T12:00:00Z 5)类似于SQL数据库的行;
基于这些数据库术语的比较,InfluxDB的continuous query和retention policy与SQL数据库中的存储过程类似。 它们被指定一次,然后定期自动执行。
在InfluxDB中InfluxQL是一种类SQL的语言。对于来自其他SQL或类SQL环境的用户来说,它已经被精心设计,而且还提供特定于存储和分析时间序列数据的功能。
InfluxQL的select语句来自于SQL中的select形式:
SELECT <stuff> FROM <measurement_name> WHERE <some_conditions>
- 1
如果你想看到planet为Saturn,并且在UTC时间为2015年4月16号12:00:01之后的数据:
SELECT * FROM "foodships" WHERE "planet" = 'Saturn' AND time > '2015-04-16 12:00:01'
- 1
如上例所示,InfluxQL允许您在WHERE子句中指定查询的时间范围。您可以使用包含单引号的日期时间字符串,格式为YYYY-MM-DD HH:MM:SS.mmm(mmm为毫秒,为可选项,您还可以指定微秒或纳秒。您还可以使用相对时间与now()来指代服务器的当前时间戳:
SELECT * FROM "foodships" WHERE time > now() - 1h
- 1
该查询输出measurement为foodships中的数据,其中时间戳比服务器当前时间减1小时。与now()做计算来决定时间范围的可选单位有:
| 字母 | 意思 |
|---|---|
| u或µ | 微秒 |
| ms | 毫秒 |
| s | 秒 |
| m | 分钟 |
| h | 小时 |
| d | 天 |
| w | 星期 |
SQL数据库和InfluxDB之间存在一些重大差异。SQL中的JOIN不适用于InfluxDB中的measurement。InfluxQL还支持正则表达式,表达式中的运算符,SHOW语句和GROUP BY语句。 InfluxQL功能还包括COUNT,MIN,MAX,MEDIAN,DERIVATIVE等。
### 为什么InfluxDB不是CRUD的一个解释
InfluxDB是针对时间序列数据进行了优化的数据库。这些数据通常来自分布式传感器组,来自大型网站的点击数据或金融交易列表等。
这个数据有一个共同之处在于它只看一个点没什么用。一个读者说,在星期二UTC时间为12:38:35时根据他的电脑CPU利用率为12%,这个很难得出什么结论。只有跟其他的series结合并可视化时,它变得更加有用。随着时间的推移开始显现的趋势,是我们从这些数据里真正想要看到的。另外,时间序列数据通常是一次写入,很少更新。
结果是,由于优先考虑create和read数据的性能而不是update和delete,InfluxDB不是一个完整的CRUD数据库,更像是一个CR-ud。
2、快速入门
$ wget https://dl.influxdata.com/influxdb/releases/influxdb_1.5.2_amd64.deb
$ sudo dpkg -i influxdb_1.5.2_amd64.deb
$ sudo systemctl start influxdb
$ influx -precision rfc3339
Connected to http://localhost:8086 version 1.2.x
InfluxDB shell 1.2.x
> CREATE DATABASE mydb
>
> SHOW DATABASES
name: databases
---------------
name
_internal
mydb
> USE mydb
Using database mydb
> INSERT cpu,host=serverA,region=us_west value=0.64
>
> SELECT "host", "region", "value" FROM "cpu"
name: cpu
---------
time host region value
2018-05-19T19:28:07.580664347Z serverA us_west 0.64
>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
3、Influx HttpAPI
详见官方文档。
| Endpoint | Description |
|---|---|
| /debug/requests | 测试某时间段的用户(client)query或write的情况。 |
| /ping | 测试数据库状态,返回204则正常 |
| /query | 查询的请求 |
| /write | 写入数据的请求 |
$ curl http://localhost:8086/debug/requests?seconds=60
{
"user1:123.45.678.91": {"writes":3,"queries":0},
"user1:000.0.0.0": {"writes":0,"queries":16},
"user2:xx.xx.xxx.xxx": {"writes":4,"queries":0}
}
$ curl -sl -I localhost:8086/ping
HTTP/1.1 204 No Content
Content-Type: application/json
Request-Id: [...]
X-Influxdb-Version: 1.4.x
Date: Wed, 08 Nov 2017 00:09:52 GMT
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
### /query
GET http://localhost:8086/query
POST http://localhost:8086/query
| Verb | Query Type |
|---|---|
| GET | 使用场景: SELECT, SHOW |
| POST | 使用场景:SELECT INTO, ALTER, CREATE, DELETE, DROP, GRANT, KILL, REVOKE |
$ curl -G 'http://localhost:8086/query?db=mydb' --data-urlencode 'q=SELECT * FROM "mymeas"'
$ curl -XPOST 'http://localhost:8086/query?db=mydb' --data-urlencode 'q=SELECT * INTO "newmeas" FROM "mymeas"'
$ curl -XPOST 'http://localhost:8086/query' --data-urlencode 'q=CREATE DATABASE "mydb"'
$ curl -XPOST 'http://localhost:8086/query?u=myusername&p=mypassword' --data-urlencode 'q=CREATE DATABASE "mydb"'
$ curl -G 'http://localhost:8086/query?db=mydb&epoch=s' --data-urlencode 'q=SELECT * FROM "mymeas";SELECT mean("myfield") FROM "mymeas"'
$ curl -H "Accept: application/csv" -G 'http://localhost:8086/query?db=mydb' --data-urlencode 'q=SELECT * FROM "mymeas"'
// 返回svg格式
name,tags,time,myfield,mytag1,mytag2
mymeas,,1488327378000000000,33.1,mytag1,mytag2
mymeas,,1488327438000000000,12.4,12,14
$ curl -G 'http://localhost:8086/query?db=mydb'
--data-urlencode 'q=SELECT * FROM "mymeas" WHERE "mytag1" = $tag_value AND "myfield" < $field_value'
--data-urlencode 'params={"tag_value":"12","field_value":30}'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
### /write
$ curl -i -XPOST "http://localhost:8086/write?db=mydb" --data-binary 'mymeas,mytag=1 myfield=90'
// 支持多行
$ curl -i -XPOST "http://localhost:8086/write?db=mydb" --data-binary 'mymeas,mytag=3 myfield=89
mymeas,mytag=2 myfield=34 1463689152000000000'
// 支持文件
$ curl -i -XPOST "http://localhost:8086/write?db=mydb" --data-binary @data.txt
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4、InfluxQL查询语言
4.1、查询数据
4.1.1、基本的SELECT语句
SELECT <field_key>[,<field_key>,<tag_key>] FROM <measurement_name>[,<measurement_name>]
- 1
##### SELECT子句
SLECT *:返回所有的field和tag。
SELECT "<field_key>":返回特定的field。
SELECT "<field_key>","<field_key>":返回多个field。
SELECT "<field_key>","<tag_key>":返回特定的field和tag,SELECT在包括一个tag时,必须只是指定一个field。
SELECT "<field_key>"::field,"<tag_key>"::tag:返回特定的field和tag,::[field | tag]语法指定标识符的类型。 使用此语法来区分具有相同名称的field key和tag key。
##### FROM子句
FROM <measurement_name>:从单个measurement返回数据。如果使用CLI需要先用USE指定数据库,并且使用的DEFAULT存储策略。如果您使用HTTP API,需要用db参数来指定数据库,也是使用DEFAULT存储策略。
FROM <measurement_name>,<measurement_name>:从多个measurement中返回数据。
FROM <database_name>.<retention_policy_name>.<measurement_name>:从一个完全指定的measurement中返回数据,这个完全指定是指指定了数据库和存储策略。
FROM <database_name>..<measurement_name>:从一个用户指定的数据库中返回存储策略为DEFAULT的数据。
##### 引号
如果标识符包含除[A-z,0-9,_]之外的字符,如果它们以数字开头,或者如果它们是InfluxQL关键字,那么它们必须用双引号。比如把emoji当作measurement名。
注意:查询的语法与行协议是不同的。
#### 例子
// 例一:从单个measurement查询所有的field和tag
> SELECT * FROM "h2o_feet"
// 例二:从单个measurement中查询特定tag和field
> SELECT "level description","location","water_level" FROM "h2o_feet"
// 例三:从单个measurement中选择特定的tag和field,并提供其标识符类型
> SELECT "level description"::field,"location"::tag,"water_level"::field FROM "h2o_feet"
// 例四:从单个measurement查询所有field
> SELECT *::field FROM "h2o_feet"
// 例五:从measurement中选择一个特定的field并执行基本计算
> SELECT ("water_level" * 2) + 4 from "h2o_feet"
// 例六:从多个measurement中查询数据
> SELECT * FROM "h2o_feet","h2o_pH"
// 例七:从完全限定的measurement中选择所有数据
> SELECT * FROM "NOAA_water_database"."autogen"."h2o_feet"
// 例八:从特定数据库中查询measurement的所有数据
> SELECT * FROM "NOAA_water_database".."h2o_feet"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
4.1.2、WHERE子句
WHERE子句在field,tag和timestamp上支持conditional_expressions.
SELECT_clause FROM_clause WHERE <conditional_expression> [(AND|OR) <conditional_expression> [...]]
- 1
##### fields
WHERE子句支持field value是字符串,布尔型,浮点数和整数这些类型。
在WHERE子句中单引号来表示字符串字段值。具有无引号字符串字段值或双引号字符串字段值的查询将不会返回任何数据,并且在大多数情况下也不会返回错误。
field_key <operator> ['string' | boolean | float | integer]
- 1
支持的操作符:
= 等于
<> 不等于
!= 不等于
> 大于
>= 大于等于
< 小于
<= 小于等于
##### tags
WHERE子句中的用单引号来把tag value引起来。具有未用单引号的tag或双引号的tag查询将不会返回任何数据,并且在大多数情况下不会返回错误。
tag_key <operator> ['tag_value']
- 1
支持的操作符:
= 等于
<> 不等于
!= 不等于
##### timestamps
对于大多数SELECT语句,默认时间范围为UTC的1677-09-21 00:12:43.145224194到2262-04-11T23:47:16.854775806Z。 对于只有GROUP BY time()子句的SELECT语句,默认时间范围在UTC的1677-09-21 00:12:43.145224194和now()之间。
#### 例子
// 例二:查询有特定field的key value为字符串的数据
> SELECT * FROM "h2o_feet" WHERE "level description" = 'below 3 feet'
// 例三:查询有特定field的key value并且带计算的数据
> SELECT * FROM "h2o_feet" WHERE "water_level" + 2 > 11.9
// 例六:根据时间戳来过滤数据
> SELECT * FROM "h2o_feet" WHERE time > now() - 7d
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.1.3、GROUP BY子句
GROUP BY子句后面可以跟用户指定的tags或者是一个时间间隔。
### GROUP BY tags
SELECT_clause FROM_clause [WHERE_clause] GROUP BY [* | <tag_key>[,<tag_key]]
- 1
GROUP BY *:对结果中的所有tag作group by。
GROUP BY <tag_key>:对结果按指定的tag作group by。
GROUP BY <tag_key>,<tag_key>:对结果数据按多个tag作group by,其中tag key的顺序没所谓。
#### 例子
// 例一:对单个tag作group by
> SELECT MEAN("water_level") FROM "h2o_feet" GROUP BY "location"
name: h2o_feet
tags: location=coyote_creek
time mean
---- ----
1970-01-01T00:00:00Z 5.359342451341401
name: h2o_feet
tags: location=santa_monica
time mean
---- ----
1970-01-01T00:00:00Z 3.530863470081006
# epoch 0(`1970-01-01T00:00:00Z`)通常用作等效的空时间戳。
// 例二:对多个tag作group by
> SELECT MEAN("index") FROM "h2o_quality" GROUP BY location,randtag
name: h2o_quality
tags: location=coyote_creek, randtag=1
time mean
---- ----
1970-01-01T00:00:00Z 50.69033760186263
name: h2o_quality
tags: location=coyote_creek, randtag=2
time mean
---- ----
1970-01-01T00:00:00Z 49.661867544220485
// 例三:对所有tag作group by
> SELECT MEAN("index") FROM "h2o_quality" GROUP BY *
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
### GROUP BY time()
GROUP BY time()返回结果按指定的时间间隔group by。
SELECT <function>(<field_key>) FROM_clause WHERE <time_range> GROUP BY time(<time_interval>,<offset_interval>),[tag_key] [fill(<fill_option>)]
- 1
time(time_interval,offset_interval) :
time_interval是一个时间duration。决定了InfluxDB按什么时间间隔group by。例如:time_interval为5m则在WHERE子句中指定的时间范围内将查询结果分到五分钟时间组里。
offset_interval是一个持续时间。它向前或向后移动InfluxDB的预设时间界限。offset_interval可以为正或负。
fill(<fill_option>) :可选的,它会更改不含数据的时间间隔的返回值。
覆盖范围:基本GROUP BY time()查询依赖于time_interval,offset_interval和InfluxDB的预设时间边界来确定每个时间间隔中包含的原始数据以及查询返回的时间戳。
##### 例子
// 例二:时间间隔为12分钟并且还对tag key作group by
> SELECT COUNT("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m),"location"
name: h2o_feet
tags: location=coyote_creek
time count
---- -----
2015-08-18T00:00:00Z 2
2015-08-18T00:12:00Z 2
2015-08-18T00:24:00Z 2
name: h2o_feet
tags: location=santa_monica
time count
---- -----
2015-08-18T00:00:00Z 2
2015-08-18T00:12:00Z 2
2015-08-18T00:24:00Z 2
// 例一:查询结果间隔按18分钟group by,并将预设时间边界向前移动
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >= '2015-08-18T00:06:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(18m,6m)
name: h2o_feet
time mean
---- ----
2015-08-18T00:06:00Z 7.884666666666667
2015-08-18T00:24:00Z 7.502333333333333
2015-08-18T00:42:00Z 7.108666666666667
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >= '2015-08-18T00:06:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(18m)
name: h2o_feet
time mean
---- ----
2015-08-18T00:00:00Z 7.946
2015-08-18T00:18:00Z 7.6323333333333325
2015-08-18T00:36:00Z 7.238666666666667
2015-08-18T00:54:00Z 6.982
# fill()的例子
> SELECT MAX("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >= '2015-09-18T16:00:00Z' AND time <= '2015-09-18T16:42:00Z' GROUP BY time(12m)
name: h2o_feet
--------------
time max
2015-09-18T16:00:00Z 3.599
2015-09-18T16:12:00Z 3.402
2015-09-18T16:24:00Z 3.235
2015-09-18T16:36:00Z
> SELECT MAX("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >= '2015-09-18T16:00:00Z' AND time <= '2015-09-18T16:42:00Z' GROUP BY time(12m) fill(100)
name: h2o_feet
--------------
time max
2015-09-18T16:00:00Z 3.599
2015-09-18T16:12:00Z 3.402
2015-09-18T16:24:00Z 3.235
2015-09-18T16:36:00Z 100
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
## ORDER BY TIME DESC
默认情况下,InfluxDB以升序的顺序返回结果; 返回的第一个点具有最早的时间戳,返回的最后一个点具有最新的时间戳。 ORDER BY time DESC反转该顺序,使得InfluxDB首先返回具有最新时间戳的点。
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] ORDER BY time DESC
- 1
### 例子
// 例一:首先返回最新的点
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica' ORDER BY time DESC
name: h2o_feet
time water_level
---- -----------
2015-09-18T21:42:00Z 4.938
2015-09-18T21:36:00Z 5.066
[...]
2015-08-18T00:06:00Z 2.116
2015-08-18T00:00:00Z 2.064
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.1.4、INTO子句
INTO子句将查询的结果写入到用户自定义的measurement中。
SELECT_clause INTO <measurement_name> FROM_clause [WHERE_clause] [GROUP_BY_clause]
- 1
INTO支持多种格式的measurement。
INTO <measurement_name>:写入到特定measurement中,用CLI时,写入到用USE指定的数据库,保留策略为DEFAULT,用HTTP API时,写入到db参数指定的数据库,保留策略为DEFAULT。INTO <database_name>.<retention_policy_name>.<measurement_name>:写入到完整指定的measurement中。INTO <database_name>..<measurement_name>:写入到指定数据库保留策略为DEFAULT。INTO <database_name>.<retention_policy_name>.:MEASUREMENT FROM /<regular_expression>/:将数据写入与FROM子句中正则表达式匹配的用户指定数据库和保留策略的所有measurement。:MEASUREMENT是对FROM子句中匹配的每个measurement的反向引用。(相当于从一个库的这些表,拷贝到新数据源的同名表下)
### 例子
// 例一:重命名数据库
> SELECT * INTO "copy_NOAA_water_database"."autogen".:MEASUREMENT FROM "NOAA_water_database"."autogen"./.*/ GROUP BY *
name: result
time written
---- -------
0 76290
因为influxdb不支持重命名数据库,所以可以这样重新导入一边数据。`group by *`的作用是将原measurement中的tag key,依旧在新的measurement当成tag key。如果不加,
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.1.5、LIMIT和SLIMIT子句
LIMIT <N> N指定每次measurement返回的点数。如果N大于measurement的点数,InfluxDB将从该测量中返回所有点。
SLIMIT <M> M指定从指定measurement返回的series数。如果M大于measurement中series联数,InfluxDB将从该measurement中返回所有series。
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] LIMIT <N> SLIMIT <M>
- 1
### 例子
// 例一:限制返回的点数
> SELECT "water_level","location" FROM "h2o_feet" LIMIT 3
// 例一:限制返回的series的数目
> SELECT "water_level" FROM "h2o_feet" GROUP BY * SLIMIT 1
// 例二:限制数据点数和series数并且包括一个GROUP BY time()子句
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:42:00Z' GROUP BY *,time(12m) LIMIT 2 SLIMIT 1
name: h2o_feet
tags: location=coyote_creek
time mean
---- ----
2015-08-18T00:00:00Z 8.0625
2015-08-18T00:12:00Z 7.8245
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4.1.6、OFFSET和SOFFSET子句
OFFSET <N>从查询结果中返回分页的N个数据点
SOFFSET <M>从查询结果中返回分页的M个series
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] LIMIT_clause OFFSET <N> SLIMIT_clause SOFFSET <M>
- 1
OFFSET子句需要一个LIMIT子句。使用没有LIMIT子句的OFFSET子句可能会导致不一致的查询结果。SOFFSET子句需要一个SLIMIT子句。使用没有SLIMIT子句的SOFFSET子句可能会导致不一致的查询结果。
### 例子
// 例一:分页数据点
> SELECT "water_level","location" FROM "h2o_feet" LIMIT 3 OFFSET 3
// 例一:分页series
> SELECT "water_level" FROM "h2o_feet" GROUP BY * SLIMIT 1 SOFFSET 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
4.1.7、Time Zone子句
tz()子句返回指定时区的UTC偏移量。
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause] tz('<time_zone>')
- 1
默认情况下,InfluxDB以UTC为单位存储并返回时间戳。 tz()子句包含UTC偏移量,或UTC夏令时(DST)偏移量到查询返回的时间戳中。 返回的时间戳必须是RFC3339格式,用于UTC偏移量或UTC DST才能显示。time_zone参数遵循Internet Assigned Numbers Authority时区数据库中的TZ语法,它需要单引号。
### 例子
// 例一:返回从UTC偏移到芝加哥时区的数据
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:18:00Z' tz('America/Chicago')
name: h2o_feet
time water_level
---- -----------
2015-08-17T19:00:00-05:00 2.064
2015-08-17T19:06:00-05:00 2.116
2015-08-17T19:12:00-05:00 2.028
2015-08-17T19:18:00-05:00 2.126
查询的结果包括UTC偏移-5个小时的美国芝加哥时区的时间戳。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.1.8、时间语法
对于大多数SELECT语句,默认时间范围为UTC的1677-09-21 00:12:43.145224194到2262-04-11T23:47:16.854775806Z。 对于具有GROUP BY time()子句的SELECT语句,默认时间范围在UTC的1677-09-21 00:12:43.145224194和now()之间。以下部分详细说明了如何在SELECT语句的WHERE子句中指定替代时间范围。
### 绝对时间
用时间字符串或是epoch时间来指定绝对时间
SELECT_clause FROM_clause WHERE time <operator> ['<rfc3339_date_time_string>' |
'<rfc3339_like_date_time_string>' | <epoch_time>] [AND ['<rfc3339_date_time_string>' |
'<rfc3339_like_date_time_string>' | <epoch_time>] [...]]
- 1
- 2
- 3
最近,InfluxDB不再支持在WHERE的绝对时间里面使用OR了。
##### rfc3399时间字符串
'YYYY-MM-DDTHH:MM:SS.nnnnnnnnnZ'
- 1
.nnnnnnnnn是可选的,如果没有的话,默认是.00000000,rfc3399格式的时间字符串要用单引号引起来。
##### epoch_time
Epoch时间是1970年1月1日星期四00:00:00(UTC)以来所经过的时间。默认情况下,InfluxDB假定所有epoch时间戳都是纳秒。也可以在epoch时间戳的末尾包括一个表示时间精度的字符,以表示除纳秒以外的精度。
##### 基本算术
所有时间戳格式都支持基本算术。用表示时间精度的字符添加(+)或减去(-)一个时间。请注意,InfluxQL需要+或-和表示时间精度的字符之间用空格隔开。
#### 例子
// 例五:对RFC3339格式的时间戳的基本计算
> SELECT "water_level" FROM "h2o_feet" WHERE time > '2015-09-18T21:24:00Z' + 6m
// 例六:对epoch时间戳的基本计算
> SELECT "water_level" FROM "h2o_feet" WHERE time > 24043524m - 6m
- 1
- 2
- 3
- 4
- 5
- 6
### 相对时间
使用now()查询时间戳相对于服务器当前时间戳的的数据。
SELECT_clause FROM_clause WHERE time <operator> now() [[ - | + ] <duration_literal>] [(AND|OR) now() [...]]
- 1
now()是在该服务器上执行查询时服务器的Unix时间。-或+和时间字符串之间需要空格。
#### 例子
// 例一:用相对时间指定时间间隔
> SELECT "water_level" FROM "h2o_feet" WHERE time > now() - 1h
// 例二:用绝对和相对时间指定时间间隔
> SELECT "level description" FROM "h2o_feet" WHERE time > '2015-09-18T21:18:00Z' AND time < now() + 1000d
- 1
- 2
- 3
- 4
- 5
- 6
4.1.9、正则表达式
InluxDB支持在以下场景使用正则表达式:
- 在
SELECT中的field key和tag key; - 在
FROM中的measurement - 在
WHERE中的tag value和字符串类型的field value - 在
GROUP BY中的tag key
目前,InfluxQL不支持在WHERE中使用正则表达式去匹配不是字符串的field value,以及数据库名和retention policy。
注意:正则表达式比精确的字符串更加耗费计算资源; 具有正则表达式的查询比那些没有的性能要低一些。
SELECT /<regular_expression_field_key>/ FROM /<regular_expression_measurement>/ WHERE [<tag_key> <operator> /<regular_expression_tag_value>/ | <field_key> <operator> /<regular_expression_field_value>/] GROUP BY /<regular_expression_tag_key>/
- 1
正则表达式前后使用斜杠/,并且使用Golang的正则表达式语法。
支持的操作符:
=~ 匹配
!~ 不匹配
### 例子:
// 例一:在SELECT中使用正则表达式指定field key和tag key
> SELECT /l/ FROM "h2o_feet" LIMIT 1
// 例二:在SELECT中使用正则表达式指定函数里面的field key
> SELECT DISTINCT(/level/) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00.000000000Z' AND time <= '2015-08-18T00:12:00Z'
// 例三:在FROM中使用正则表达式指定measurement
> SELECT MEAN("degrees") FROM /temperature/
// 例四:在WHERE中使用正则表达式指定tag value
> SELECT MEAN(water_level) FROM "h2o_feet" WHERE "location" =~ /[m]/ AND "water_level" > 3
// 例五:在WHERE中使用正则表达式指定无值的tag
> SELECT * FROM "h2o_feet" WHERE "location" !~ /./
// 例六:在WHERE中使用正则表达式指定有值的tag
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE "location" =~ /./
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
4.1.10、子查询
子查询是嵌套在另一个查询的FROM子句中的查询。使用子查询将查询作为条件应用于其他查询。子查询提供与嵌套函数和SQLHAVING子句类似的功能。
SELECT_clause FROM ( SELECT_statement ) [...]
- 1
InfluxDB首先执行子查询,再次执行主查询。
主查询围绕子查询,至少需要SELECT和FROM子句。主查询支持本文档中列出的所有子句。
子查询显示在主查询的FROM子句中,它需要附加的括号。 子查询支持本文档中列出的所有子句。
InfluxQL每个主要查询支持多个嵌套子查询。 多个子查询的示例语法:
SELECT_clause FROM ( SELECT_clause FROM ( SELECT_statement ) [...] ) [...]
- 1
### 例子
// 例一:计算多个`MAX()`值的`SUM()`
> SELECT SUM("max") FROM (SELECT MAX("water_level") FROM "h2o_feet" GROUP BY "location")
name: h2o_feet
time sum
---- ---
1970-01-01T00:00:00Z 17.169
// 例二:计算两个field的差值的`MEAN()`
> SELECT MEAN("difference") FROM (SELECT "cats" - "dogs" AS "difference" FROM "pet_daycare")
name: pet_daycare
time mean
---- ----
1970-01-01T00:00:00Z 1.75
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4.2、数据库概要

比较简单,语法如下:
SHOW DATABASES
SHOW RETENTION POLICIES [ON <database_name>]
SHOW SERIES [ON <database_name>] [FROM_clause] [WHERE <tag_key> <operator> [ '<tag_value>' | <regular_expression>]] [LIMIT_clause] [OFFSET_clause]
SHOW MEASUREMENTS [ON <database_name>] [WITH MEASUREMENT <regular_expression>] [WHERE <tag_key> <operator> ['<tag_value>' | <regular_expression>]] [LIMIT_clause] [OFFSET_clause]
SHOW TAG KEYS [ON <database_name>] [FROM_clause] [WHERE <tag_key> <operator> ['<tag_value>' | <regular_expression>]] [LIMIT_clause] [OFFSET_clause]
SHOW TAG VALUES [ON <database_name>][FROM_clause] WITH KEY [ [<operator> "<tag_key>" | <regular_expression>] | [IN ("<tag_key1>","<tag_key2")]] [WHERE <tag_key> <operator> ['<tag_value>' | <regular_expression>]] [LIMIT_clause] [OFFSET_clause]
SHOW FIELD KEYS [ON <database_name>] [FROM <measurement_name>]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.3、管理数据

4.3.1、管理数据库
CREATE DATABASE <database_name> [WITH [DURATION <duration>] [REPLICATION <n>] [SHARD DURATION <duration>] [NAME <retention-policy-name>]]
DROP DATABASE <database_name>
- 1
- 2
- 3
WITH,DURATION,REPLICATION,SHARD DURATION和NAME子句是可选的用来创建与数据库相关联的单个保留策略。如果您没有在WITH之后指定其中一个子句,将默认为autogen保留策略。创建的保留策略将自动用作数据库的默认保留策略。
一个成功的CREATE DATABASE查询返回一个空的结果。如果您尝试创建已存在的数据库,InfluxDB什么都不做,也不会返回错误。
DROP DATABASE从指定数据库删除所有的数据,以及measurement,series,continuous queries, 和retention policies。语法为:
#### 例子
> CREATE DATABASE "NOAA_water_database"
> CREATE DATABASE "NOAA_water_database" WITH DURATION 3d REPLICATION 1 SHARD DURATION 1h NAME "liquid"
- 1
- 2
4.3.2、用DROP从索引中删除series
DROP SERIES删除一个数据库里的一个series的所有数据,并且从索引中删除series。
DROP SERIES不支持WHERE中带时间间隔。
该查询采用以下形式,您必须指定FROM子句或WHERE子句:
DROP SERIES FROM <measurement_name[,measurement_name]> WHERE <tag_key>='<tag_value>'
- 1
#### 例子
从单个measurement删除所有series:
DROP SERIES FROM "h2o_feet"
从单个measurement删除指定tag的series:
DROP SERIES FROM "h2o_feet" WHERE "location" = 'santa_monica'
从数据库删除有指定tag的所有measurement中的所有数据:
DROP SERIES WHERE "location" = 'santa_monica'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.3.3、用DELETE删除series
DELETE删除数据库中的measurement中的所有点。与DROP SERIES不同,它不会从索引中删除series,并且它支持WHERE子句中的时间间隔。
该查询采用以下格式,必须包含FROM子句或WHERE子句,或两者都有:
DELETE FROM <measurement_name> WHERE [<tag_key>='<tag_value>'] | [<time interval>]
- 1
#### 例子
删除measurement`h2o_feet`的所有相关数据:
> DELETE FROM "h2o_feet"
删除measurement`h2o_quality`并且tag`randtag`等于3的所有数据:
> DELETE FROM "h2o_quality" WHERE "randtag" = '3'
删除数据库中2016年一月一号之前的所有数据:
> DELETE WHERE time < '2016-01-01'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
一个成功的DELETE返回一个空的结果。 关于DELETE的注意事项:
- 当指定measurement名称时,
DELETE在FROM子句中支持正则表达式,并在指定tag时支持WHERE子句中的正则表达式。 DELETE不支持WHERE子句中的field。- 如果你需要删除之后的数据点,则必须指定
DELETE SERIES的时间间隔,因为其默认运行的时间为time <now()。
4.3.4、删除measurement
DROP MEASUREMENT删除指定measurement的所有数据和series,并且从索引中删除measurement。
DROP MEASUREMENT <measurement_name>
- 1
注意:
DROP MEASUREMENT删除measurement中的所有数据和series,但是不会删除相关的continuous queries。
4.3.5、删除shard
DORP SHARD删除一个shard,也会从metastore中删除shard。格式如下:
DROP SHARD <shard_id_number>
- 1
4.3.6、保留策略管理
以下部分介绍如何创建,更改和删除保留策略。 请注意,创建数据库时,InfluxDB会自动创建一个名为autogen的保留策略,该保留策略保留时间为无限。您可以重命名该保留策略或在配置文件中禁用其自动创建。
### 创建保留策略
CREATE RETENTION POLICY <retention_policy_name> ON <database_name> DURATION <duration> REPLICATION <n> [SHARD DURATION <duration>] [DEFAULT]
- 1
DURATION子句确定InfluxDB保留数据的时间。 <duration>是持续时间字符串或INF(无限)。 保留策略的最短持续时间为1小时,最大持续时间为INF。
REPLICATION子句确定每个点的多少独立副本存储在集群中,其中n是数据节点的数量。该子句不能用于单节点实例。
SHARD DURATION子句确定shard group覆盖的时间范围。 <duration>是一个持续时间字符串,不支持INF(无限)持续时间。此设置是可选的。 默认情况下,shard group持续时间由保留策略的DURATION决定:
| 保留策略的持续时间 | shard group的持续时间 |
|---|---|
| (0,2d) | 1小时 |
| [2d,6m] | 1天 |
| (6m,INF) | 7天 |
最小允许SHARD GROUP DURATION为1小时。 如果CREATE RETENTION POLICY查询尝试将SHARD GROUP DURATION设置为小于1小时且大于0,则InfluxDB会自动将SHARD GROUP DURATION设置为1h。 如果CREATE RETENTION POLICY查询尝试将SHARD GROUP DURATION设置为0,InfluxDB会根据上面列出的默认设置自动设置SHARD GROUP DURATION。
DEFAULT将新的保留策略设置为数据库的默认保留策略。此设置是可选的。
#### 例子
> CREATE RETENTION POLICY "one_day_only" ON "NOAA_water_database" DURATION 1d REPLICATION 1
> CREATE RETENTION POLICY "one_day_only" ON "NOAA_water_database" DURATION 23h60m REPLICATION 1 DEFAULT
如果您尝试创建与已存在的保留策略相同的保留策略,InfluxDB不会返回错误。
如果您尝试创建与现有保留策略名称相同但具有不同属性的保留策略,InfluxDB会返回错误。
- 1
- 2
- 3
- 4
注意:也可以在
CREATE DATABASE时指定一个新的保留策略。
### 修改保留策略
ALTER RETENTION POLICY形式如下,你必须至少指定一个属性:DURATION, REPLICATION, SHARD DURATION,或者DEFAULT:
ALTER RETENTION POLICY <retention_policy_name> ON <database_name> DURATION <duration> REPLICATION <n> SHARD DURATION <duration> DEFAULT
- 1
#### 例子
> ALTER RETENTION POLICY "what_is_time" ON "NOAA_water_database" DURATION 3w SHARD DURATION 30m DEFAULT
>
- 1
- 2
4.3.7、删除保留策略
删除指定保留策略的所有measurement和数据:
DROP RETENTION POLICY <retention_policy_name> ON <database_name>
- 1
4.4、聚合函数
连续查询(Continuous Queries下文统一简称CQ)是InfluxQL对实时数据自动周期运行的查询,然后把查询结果写入到指定的measurement中。
4.4.1、高级语法
CREATE CONTINUOUS QUERY <cq_name> ON <database_name>
BEGIN
<cq_query>
END
SELECT <function[s]> INTO <destination_measurement> FROM <measurement> [WHERE <stuff>] GROUP BY time(<interval>)[,<tag_key[s]>]
- 1
- 2
- 3
- 4
- 5
- 6
cq_query需要一个函数,一个INTO子句和一个GROUP BY time()子句:
注意:请注意,在
WHERE子句中,cq_query不需要时间范围。 InfluxDB在执行CQ时自动生成cq_query的时间范围。cq_query的WHERE子句中的任何用户指定的时间范围将被系统忽略。
#### 例子
例一:自动采样数据
CREATE CONTINUOUS QUERY "cq_basic" ON "transportation"
BEGIN
SELECT mean("passengers") INTO "average_passengers" FROM "bus_data" GROUP BY time(1h)
END
例二:自动采样数据到另一个保留策略里
CREATE CONTINUOUS QUERY "cq_basic_rp" ON "transportation"
BEGIN
SELECT mean("passengers") INTO "transportation"."three_weeks"."average_passengers" FROM "bus_data" GROUP BY time(1h)
END
例三:使用逆向引用自动采样数据
CREATE CONTINUOUS QUERY "cq_basic_br" ON "transportation"
BEGIN
SELECT mean(*) INTO "downsampled_transportation"."autogen".:MEASUREMENT FROM /.*/ GROUP BY time(30m),*
END
例四:自动采样数据并配置CQ的时间边界
CREATE CONTINUOUS QUERY "cq_basic_offset" ON "transportation"
BEGIN
SELECT mean("passengers") INTO "average_passengers" FROM "bus_data" GROUP BY time(1h,15m)
END
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
4.4.2、高级语法
CREATE CONTINUOUS QUERY <cq_name> ON <database_name>
RESAMPLE EVERY <interval> FOR <interval>
BEGIN
<cq_query>
END
- 1
- 2
- 3
- 4
- 5
CQs以与RESAMPLE子句中的EVERY间隔相同的间隔执行,并且它们在InfluxDB的预设时间边界开始时运行。如果EVERY间隔是两个小时,InfluxDB将在每两小时的开始执行CQ。
当CQ执行时,它运行一个单一的查询,在now()和now()减去RESAMPLE子句中的FOR间隔之间的时间范围。如果FOR间隔为两个小时,当前时间为17:00,查询的时间间隔为15:00至16:59999999999。
EVERY间隔和FOR间隔都接受时间字符串。RESAMPLE子句适用于同时配置EVERY和FOR,或者是其中之一。如果没有提供EVERY间隔或FOR间隔,则CQ默认为相关为基本语法。
例一:配置执行间隔
CREATE CONTINUOUS QUERY "cq_advanced_every" ON "transportation"
RESAMPLE EVERY 30m
BEGIN
SELECT mean("passengers") INTO "average_passengers" FROM "bus_data" GROUP BY time(1h)
END
每30分钟运行一边CQ,覆盖区间为`now() - 1h` ~ `now()`。
例二:配置CQ的重采样时间范围
CREATE CONTINUOUS QUERY "cq_advanced_for" ON "transportation"
RESAMPLE FOR 1h
BEGIN
SELECT mean("passengers") INTO "average_passengers" FROM "bus_data" GROUP BY time(30m)
END
每30分钟执行一次,覆盖区间为`now() - 1h` ~ `now()`
例三:配置执行间隔和CQ时间范围
CREATE CONTINUOUS QUERY "cq_advanced_every_for" ON "transportation"
RESAMPLE EVERY 1h FOR 90m
BEGIN
SELECT mean("passengers") INTO "average_passengers" FROM "bus_data" GROUP BY time(30m)
END
每1小时执行一次,覆盖区间为`now() - 1h30m` ~ `now()`
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
4.4.3、CQ的管理
只有admin用户允许管理CQ。
### 列出CQ
SHOW CONTINUOUS QUERIES
- 1
SHOW CONTINUOUS QUERIES按照database作分组。
### 删除CQ
DROP CONTINUOUS QUERY <cq_name> ON <database_name>
- 1
DROP CONTINUOUS QUERY返回一个空的结果。
### 修改CQ
CQ一旦创建就不能修改了,你必须DROP再CREATE才行。
## CQ的使用场景
采样和数据保留:使用CQ与InfluxDB的保留策略(RP)来减轻存储问题。结合CQ和RP自动将高精度数据降低到较低的精度,并从数据库中移除可分配的高精度数据。
预先计算昂贵的查询:通过使用CQ预先计算昂贵的查询来缩短查询运行时间。使用CQ自动将普通查询的高精度数据下采样到较低的精度。较低精度数据的查询需要更少的资源并且返回更快。
替换HAVING子句:InfluxQL不支持
HAVING子句。通过创建CQ来聚合数据并查询CQ结果以达到应用HAVING子句相同的功能。替换嵌套函数:一些InfluxQL函数支持嵌套其他函数,大多数是不行的。如果函数不支持嵌套,可以使用CQ获得相同的功能来计算最内部的函数。然后简单地查询CQ结果来计算最外层的函数。
参考文档如下: