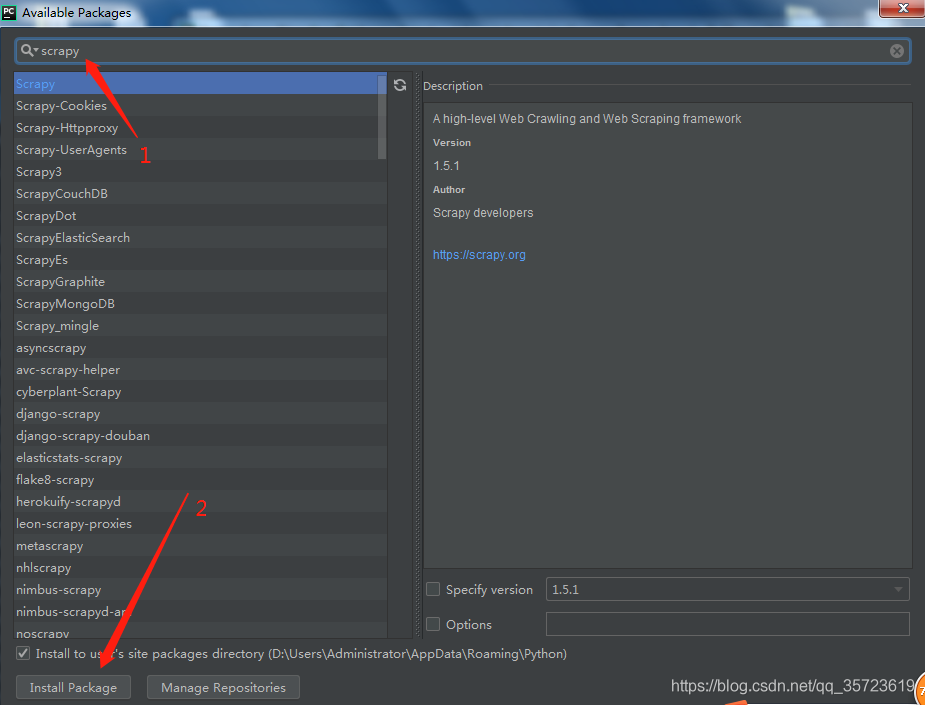
我是用的IDE是pycharm,要想使用scrapy我们先安装模块file-settings-project Interpreter
安装完成之后我们打开Terminal
在终端输入:scrapy startproject tencent
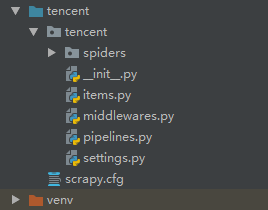
创建spiders我们需要进入spiders中,输入scrapy genscrapy tencentPosition 'tencent.com'
创建项目完成,
我们开始写items
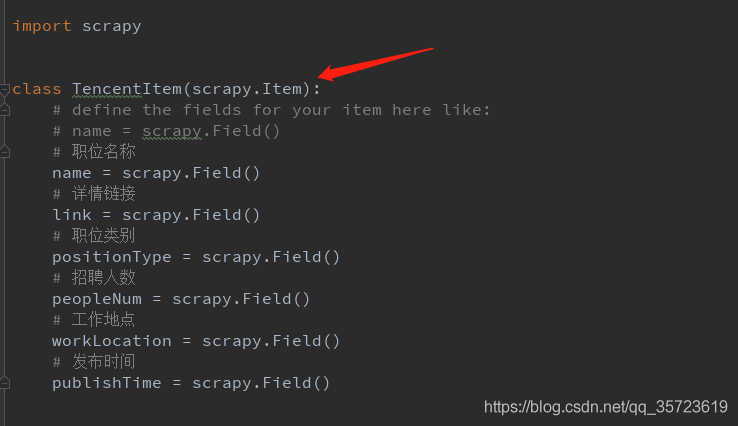
在构建spiders
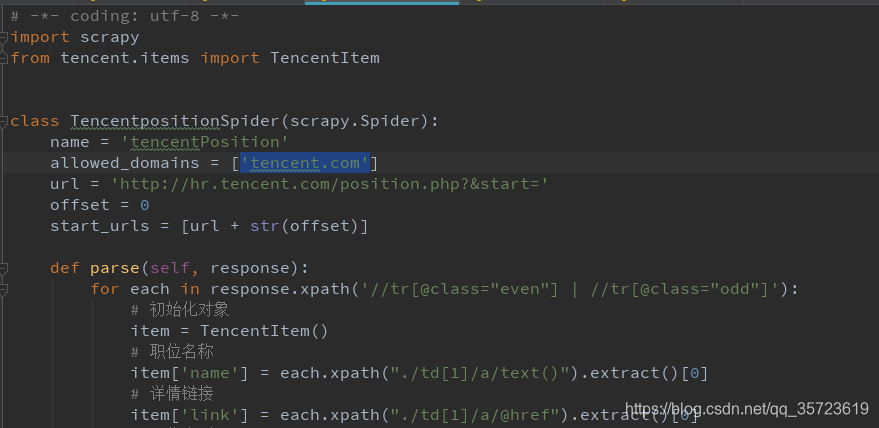
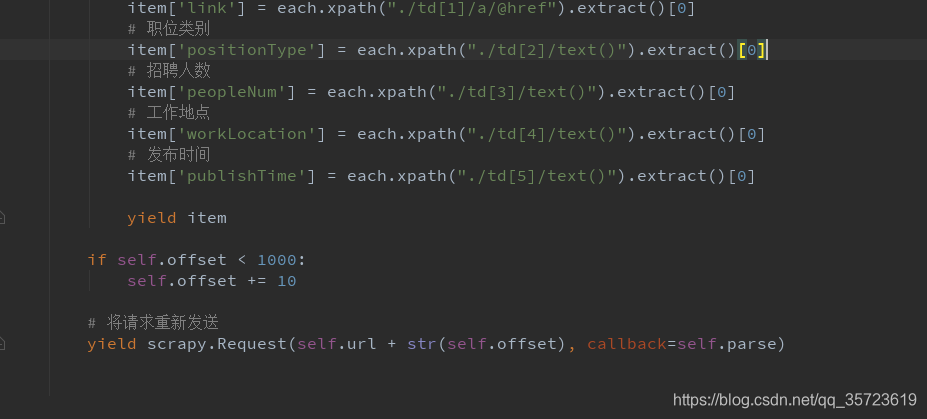
需要配置管道
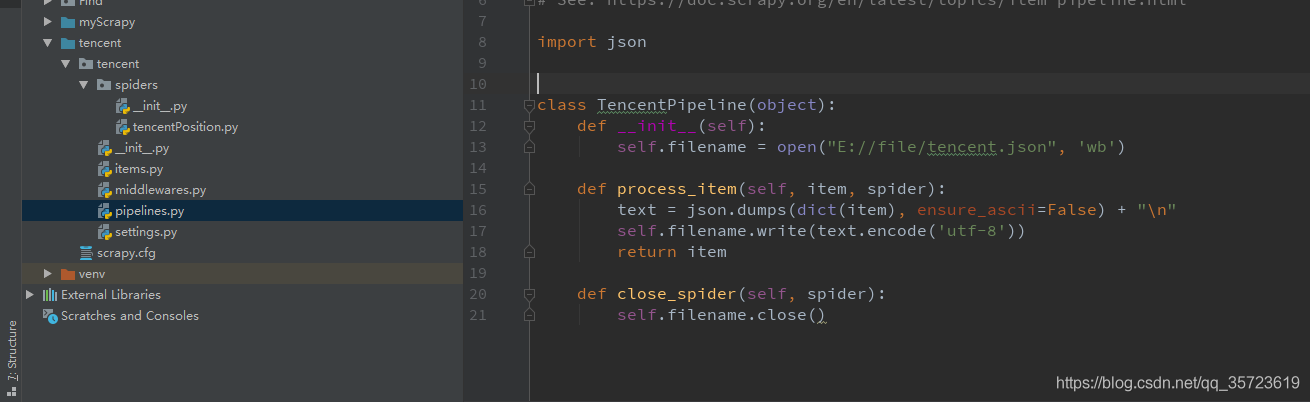
在settings.py配置
ITEM_PIPELINES = {
'tencent.pipelines.TencentPipeline': 300,
}

如有需要我们还必须配置headers
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}

在终端输入scrapy crawl tencentPosition 回车运行

另一个运行方法是创建start.py文件:
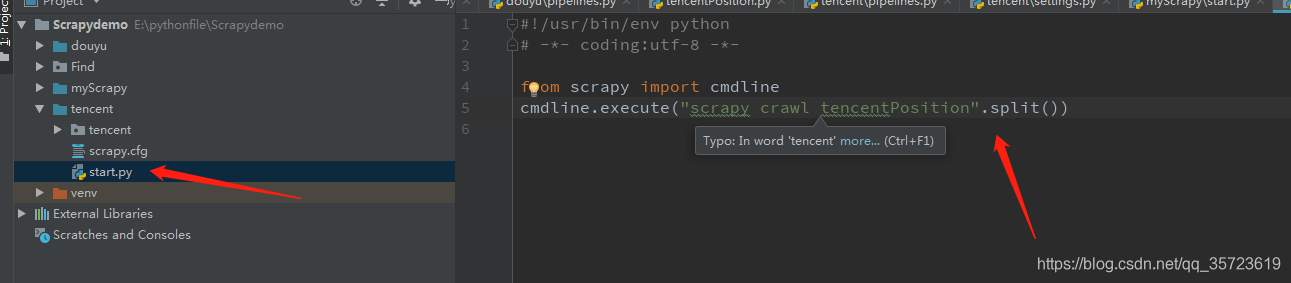
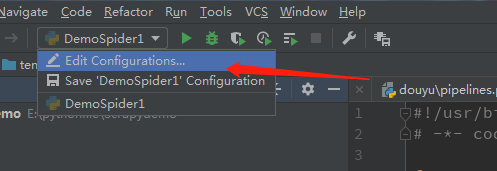
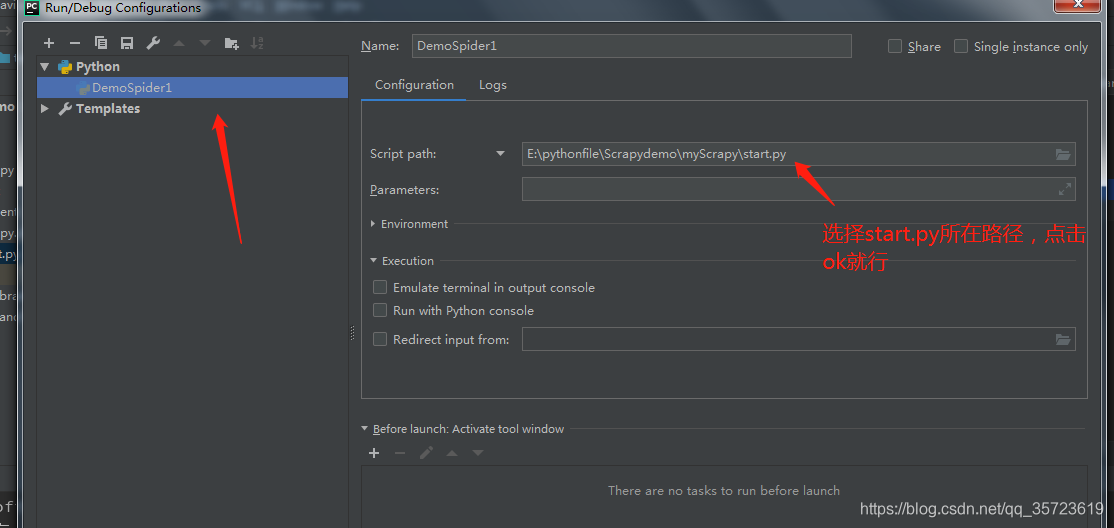
然后我们就可以通过run来运行了,刚刚学习scrapy框架走了很多弯路希望你能帮到你,感谢阅读。
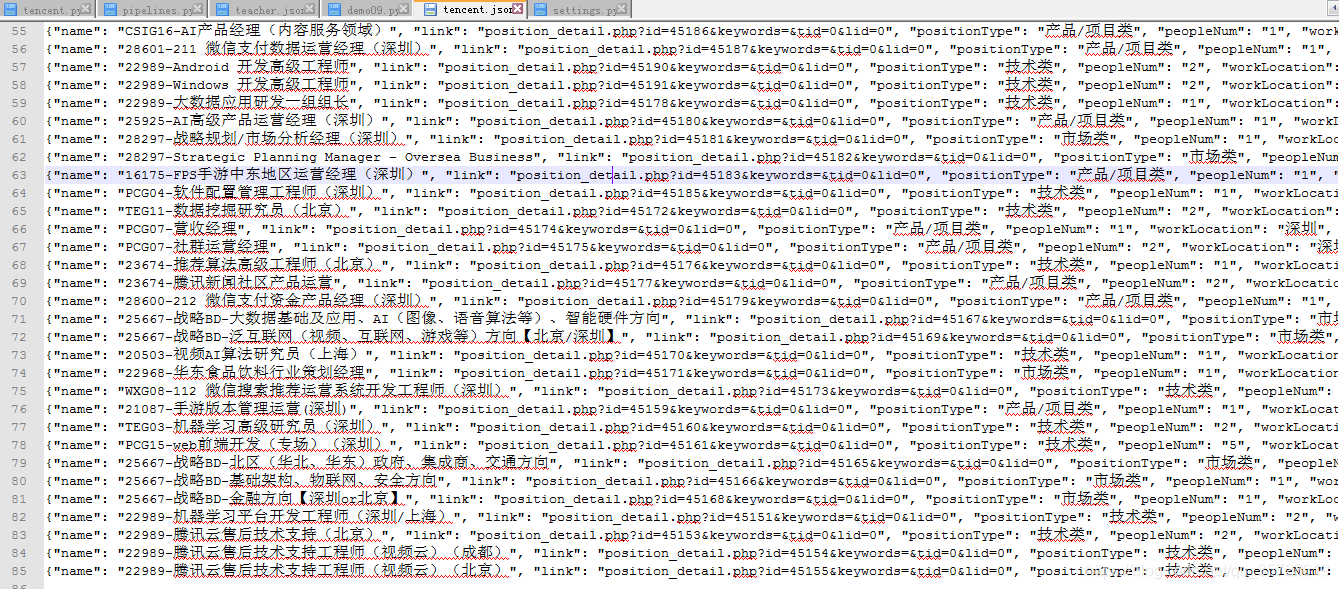
运行结果: