激活函数的定义
加拿大蒙特利尔大学的Bengio教授在 ICML 2016 的文章[1]中给出了激活函数的定义:激活函数是映射 h:R→R,且几乎处处可导。
激活函数的性质
- 非线性: 当激活函数是线性的时候,一个两层的神经网络就可以逼近基本上所有的函数了。但是,如果激活函数是恒等激活函数的时候(即),就不满足这个性质了,而且如果MLP使用的是恒等激活函数,那么其实整个网络跟单层神经网络是等价的。
- 可微性: 当优化方法是基于梯度的时候,这个性质是必须的。
- 单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数
为什么要用激活函数?
神经网络中激活函数的主要作用是提供网络的非线性建模能力,如不特别说明,激活函数一般而言是非线性函数。假设一个示例神经网络中仅包含线性卷积和全连接运算,那么该网络仅能够表达线性映射,即便增加网络的深度也依旧还是线性映射,难以有效建模实际环境中非线性分布的数据。加入(非线性)激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。因此,激活函数是深度神经网络中不可或缺的部分。
激活函数可以帮助神经网络隔离噪声点。即激活有用的信息,抑制无关的数据点。
sigmod函数
Sigmoid 是使用范围最广的一类激活函数,具有指数函数形状 。正式定义为:
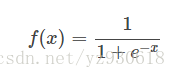
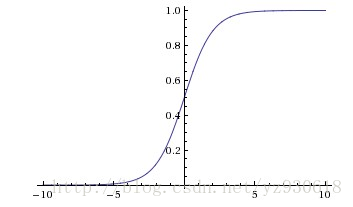
函数对应图像为:
优点:
- sigmoid函数的输出映射在(0,1)之间,单调连续,输出范围有限,优化稳定,可以用于输入的归一化,也可以用作输出层。
- 求导容易
缺点:
- 由于其软饱和性,即容易产生梯度消失,导致训练出现问题。
- 其输出并不是以0为中心的
说明:
饱和性可以分为软饱和、硬饱和。其中,软饱和是指函数的导数趋近于0,硬饱和是指函数的导数等于0。
Sigmoid 的软饱和性,使得深度神经网络在二三十年里一直难以有效的训练,是阻碍神经网络发展的重要原因。具体来说,由于在后向传递过程中,sigmoid向下传导的梯度包含了一个f'(x) 因子(sigmoid关于输入的导数),因此一旦输入落入饱和区,f'(x) 就会变得接近于0,导致了向底层传递的梯度也变得非常小。此时,网络参数很难得到有效训练。这种现象被称为梯度消失。一般来说, sigmoid 网络在 5 层之内就会产生梯度消失现象[2]。梯度消失问题至今仍然存在,但被新的优化方法有效缓解了,例如DBN中的分层预训练,Batch Normalization的逐层归一化,Xavier和MSRA权重初始化等代表性技术。
Sigmoid 的饱和性虽然会导致梯度消失,但也有其有利的一面。例如它在物理意义上最为接近生物神经元。 (0, 1) 的输出还可以被表示作概率,或用于输入的归一化,代表性的如Sigmoid交叉熵损失函数
sigmoid的输出均大于0,使得输出不是0均值,称为偏移现象,这将导致后一层的神经元将上一层输出的非0均值的信号作为输入。关于原点对称的输入和中心对称的输出,网络会收敛地更好。
tanh函数
tanh的公式如下:
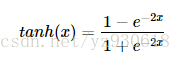
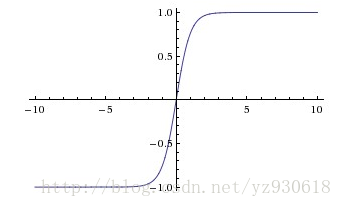
函数对应的图像如下:
优点:
- 比sigmoid函数收敛速度更快。
- 相比sigmoid函数,其输出以0为中心。
缺点:
- 依旧具有软饱和问题。
说明:
Xavier在文献[2]中分析了sigmoid与tanh的饱和现象及特点,具体见原论文。此外,文献 [3] 中提到tanh 网络的收敛速度要比sigmoid快。因为 tanh 的输出均值比 sigmoid 更接近 0,SGD会更接近 natural gradient[4](一种二次优化技术),从而降低所需的迭代次数。
ReLU函数
Relu的公式如下:
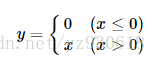
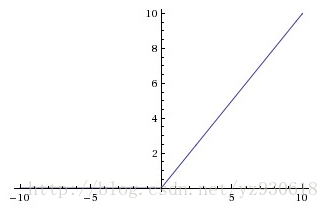
函数对应的图像如下:
优点:
- Relu具有线性、非饱和的特点,并且相比Sigmoid和tanh,Relu的收敛速度更快。
- Relu实现比较简单。
- Relu有效缓解了梯度下降问题。
- 提供了神经网络的稀疏表达能力
缺点:
- 随着训练的进行,可能会出现神经元死亡,权重无法更新的情况。
- 当x<0时,Relu是硬饱和的。
说明:
ReLU是一种后来才出现的激活函数。从图中可以看到,当x<0时,出现硬饱和,当x>0时,不存在饱和问题。因此,ReLU 能
够在x>0时保持梯度不衰减,从而缓解梯度消失问题。然而,随着训练的推进,部分输入会落入硬饱和区,导致对应权重无法更
新,这种现象被称为“神经元死亡”。
与sigmoid类似,ReLU的输出均值也大于0。偏移现象和神经元死亡会共同影响网络的收敛性。
激活函数大面积没有被激活的原因可能是:1)初始化时,参数的设置使得ReLU没有被激活;2)学习速率太高,神经元在一定范围内波动,可能会发生数据多样性的丢失,这种情况下神经元不会被激活,数据多样性的丢失不可逆转。
Leaky-ReLU 与 Parametric -ReLU函数
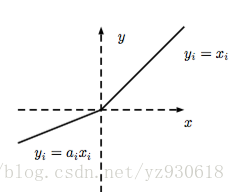
针对ReLU函数在x<0时的硬饱和问题,出现了Leaky-ReLU与P-ReLU进行改进,它们在形式上相似,不同的是在Leaky-ReLU中,α 是一个常数,实际中必须必须非常小心谨慎地重复训练,从而选取合适的参数a;在P-ReLU中,α 可以作为参数来学习,自适应地从数据中学习参数。PReLU具有收敛速度快、错误率低的特点,可以用于反向传播的训练。
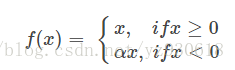
函数图像如下:
Maxout函数
Maxout[2]是ReLU的推广(出现在ICML2013),其发生饱和是一个零测集事件(measure zero event)。正式定义为:
Maxout网络能够近似任意连续函数,且当w2,b2,…,wn,bn为0时,退化为ReLU。 其实,Maxout的思想在视觉领域存在已久。例如,在HOG特征里有这么一个过程:计算三个通道的梯度强度,然后在每一个像素位置上,仅取三个通道中梯度强度最大的数值,最终形成一个通道。这其实就是Maxout的一种特例。
Maxout能够缓解梯度消失,同时又规避了ReLU神经元死亡的缺点,但增加了参数和计算量。
ELU函数
ELU[3]融合了sigmoid和ReLU,具有左侧软饱性。其正式定义为:
函数图像如下:
优点:
- ELU融合了sigmoid和ReLU,左侧具有软饱和性,右侧无饱和性。右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够 让ELU对输入变化或噪声更鲁棒。
- ELU的输出均值接近于零,所以收敛速度更快。
激活函数选择的建议
1 ) 由于梯度消失问题,有时要避免使用sigmoid和tanh函数
2)ReLU函数基本用在隐藏层。使用 ReLU,一定要小心设置 learning rate,注意不要让你的网络出现很多 “dead” 神经元
3)在人工神经网络(ANN)中,Softmax通常被用作输出层的激活函数。这不仅是因为它的效果好,而且因为它使得ANN的输出值更易于理解。
- softmax函数最明显的特点在于:它把每个神经元的输入占当前层所有神经元输入之和的比值,当作该神经元的输出。这使得输出更容易被解释:神经元的输出值越大,则该神经元对应的类别是真实类别的可能性更高。
- softmax不仅把神经元输出构造成概率分布,而且还起到了归一化的作用,适用于很多需要进行归一化处理的分类问题。
- softmax配合log似然代价函数,其训练效果也要比采用二次代价函数的方式好:二次代价函数在训练ANN时可能会导致训练速度变慢的问题(初始的输出值离真实值越远,训练速度就越慢)。这个问题可以通过采用交叉熵代价函数来解决(当激活函数是sigmod时候),也可以通过softmax的log似然代价函数。
参考文献
[1] Gulcehre, C., et al., Noisy Activation Functions, in ICML 2016.
[2] Goodfellow, I.J., et al. Maxout Networks. ICML 2013
[3] Djork-Arné Clevert, T.U., Sepp Hochreiter. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs). ICLR 2016