1. 神经元模型
神经网络是一个多学科交叉的领域,比较常见的定义是:“”神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能模拟生物神经系统对真实世界物体做出的交互反应“”。
神经网络中最基本的成分是神经元模型,典型的为m-p神经元模型,从生物角度可以形象的理解为下图。
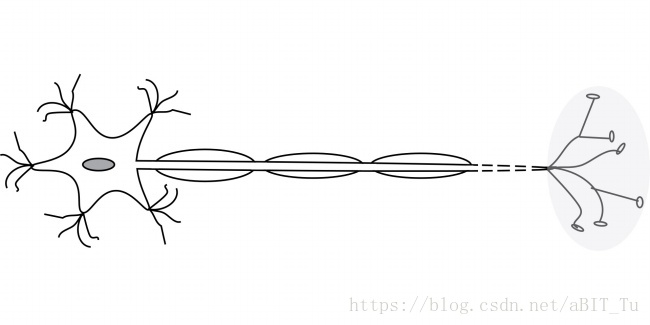
从模型角度而言,m-p神经元接收n个输入信号,并通过权重
连接形成总输入值,将总输入值与神经元的阈值
相比较,然后通过激活函数(activation function)处理以产生神经元的输出
。

神经网络就是将多个神经元按照一定的层次结构连接起来。
2. 感知器与多层网络
感知器由两层神经元组成,即输入层和输出层。单个感知器通过设置连接权重就可以实现“与”,“或“,”非”等线性问题,两层感知器可以解决“异或”问题,中间一层叫做隐含层。具体而言,在感知器学习时,将阈值视为“哑节点”,权重总为-1,即可采用“负反馈”的修正思想统一学习权重:,其中
为学习率,控制修正权值的步长。
虽然单个感知器可以有效解决线性可分问题,但是解决非线性可分问题需要使用多层功能神经元,即拥有激活函数的神经元。更一般的,若每层神经元只与下一层神经元互连,同层或跨层之间没有互连,则可称之为“多层前馈神经网络”(multi-layer feedorward neural networks)。
分享一段单个感知器的代码段,来源:https://blog.csdn.net/xmu_jupiter/article/details/21884501
function [ w,b ] = original_style( training_set,study_rate )
%training_set是一个m*n维矩阵,其中第一行是y_i,剩下的行的x_i
%选取初始值w_0,b_0
w=0;
b=0;
count=0; %每一次正确分类点个数
iteration_count=0; %迭代次数
fprintf('迭代次数\t误分类点\t\t权值w\t\t偏置b\t\n');%输出结果标题
while count ~= size(training_set,2)
count=0;
%在训练集中选取数据(x_i,y_i)
for i=1:size(training_set,2)
count = count+1;
%如果y_i(w*x_i+b)<=0,则对w和b进行相应的更新
if training_set(1,i)*(w'*training_set(2:size(training_set,1),i)+b)<=0
w = w + study_rate*training_set(1,i)*training_set(2:size(training_set,1),i);
b = b + study_rate*training_set(1,i);
iteration_count=iteration_count+1;
count=count-1;%不是正确分类点,减一
fprintf('\t%u\t',iteration_count);%输出迭代次数
fprintf('\t\t%u\t',i);%输出误分类点
fprintf('\t(%2.1g,%2.1g)''\t',w);%输出w
fprintf('\t%4.1g\n',b);%输出b
end
if w(2,1) ~= 0
x = [-5:0.1:5];
y = (-w(1,1)*x-b)/w(2,1);
plot(x, y); pause;
end
end
end
end主函数:
clear all;
training_set=[1,-1,1,-1;3,1,4,2;3,1,3,2];
hold on; xlim([-5,5]);
ylim([-5,5]);
plot(training_set(2,1),training_set(3,1),'*r');
plot(training_set(2,2),training_set(3,2),'*b');
plot(training_set(2,3),training_set(3,3),'*r');
plot(training_set(2,4),training_set(3,4),'*b');
study_rate=1;
[w,b]=original_style( training_set,study_rate );
hold off; 3. 误差反向传播(error BackPropagation)
3.1 标准BP算法和累积BP算法
BP算法是迄今最为成功的神经网络学习算法。为了详细解释BP算法,假设有训练集D={(xi,yi)| i=1...m},简单的前馈神经网络只有一层输入层(d个节点,某一个点为i),一层隐含层(q个节点,某一个点为h),一层输出层(l个节点,某一个点为j),记输入层到隐层的某一连接权重为,隐层到输出层的某一连接权重为
,隐层的某一阈值为
,输出层的某一阈值为
,隐层的某一节点的输入值为
,输出值为
,输出层的某一节点的输入值为
,输出值为
.
如图:明天来了补图,今天来不及画了,有点晚
根据向前传播的公式可知:
,
(f(*)为激活函数),
,
(f(*)为激活函数).
误差采用均方误差计算,则有:
向后修正误差:
基于梯度下降法(gradient descent),即以负梯度方向对目标函数进行调节,则有
,
,
和
类似,
以w的推导为例:
, 其中k表示第k个样本。
根据链式法则,有:
,
容易知道,,记
为输出层神经元的梯度项,后续可以根据数学求偏导继续计算,因每一个激活函数不同而不同
简单可以写成,
,
,
, 其中
为隐层神经元的梯度项。
至此标准BP算法的推导基本结束,总结一下就是:
输入训练数据集,确定学习率,随机初始化连接权重和阈值,开始训练:
repeat:
对每一个样本有:
step1. 根据前向传播公式计算当前样本的输出;
step2. 计算输出层神经元的梯度项;
step3. 计算隐层神经元的梯度项;
step4. 更新链接权重和阈值;
达到终止条件,保存权重和阈值。
以上是标准BP算法的步骤和推导,还有一个相像的称为“累积BP算法”,它通过计算整个训练集上的累积误差进行学习(即每读取整个训练集一遍后才更新阈值权重),而非每一个训练样本的误差,因此目标函数为:
,累积BP算法可以缓解标准BP算法在准样本修正中出现的反复无效修正等问题,但在误差下降到一定程度后,进一步下降的速度明显减慢,此时应该选用标准BP算法。
3.2 处理过拟合
一种策略是“早停”,即将训练集分为训练数据集和验证数据集,当训练数据集的误差降低而验证数据集的误差上升时,停止训练,并保存最小的验证集对应的权重阈值。
另一种策略是“正则化” (regularization),基本思想是增加一个用于描述网络复杂度的部分,对于误差和复杂度做以折中,如修正目标函数为,
。
3.3 处理局部极小
(1)使用多组值初始化。
(2)使用模拟退火算法,每一步都部分接收次优值。也有使用遗传算法的。·
(3)使用随机梯度下降法,即加入随机因素,扰乱陷入局部极小值的可能。