二分搜索树的优势
(1)查找表的实现-字典数据结构

(2)算法复杂度比普通数组,顺序数组低

总结如下

下面是二分搜索树(是棵二叉树)的定义


插入新节点 insert
(1)插入新元素60时,60比41大,60继续与41的右节点58比,60比58大,那么继续将60与58的右节点比,58没有右节点,那么就将60插入58的右节点位置处

(2)插入28,首先28比41小,那么28与41的左节点22比,28比22大,那么28继续与22的右节点33比,28比33小,那么继续将28与33的左节点比,33没有左节点,就将28放入33的左节点处

(3)插入42,42比41大,继续将42与41的右节点58比,42比58小,继续将42与58的左节点50比,42比50小,继续将42与50的左节点42比,42与42相等,就将新的42替换掉旧的42

二分查找树的 查找 search
(1)查找42,首先42比41大,继续将42与41的右节点58作比较,42比58小,继续将42与58的左节点50作比较,42比50小,继续将42与50的左节点作比较,42等于42查找成功

(2)查找59,59比41大,继续将59与41的右节点58比较,59比58大,继续将59与58的右节点60比较,59比60小,继续将59与60的左节点比较,60没有左节点,查找失败

程序中实现了两个函数
包含 contain,有该元素返回true,无返回false
查找 search,有该元素返回该元素的值,无返回空
search函数返回的是指针 Value*,这样在没有找到时可以返回空
search没有返回Node,因为如果返回的Node的话,那么需要将Node由private变为public,这样用户就需要了解Node的方法,这是不必要的,
而如果只使用Value,那么当没有查找到时,就会报错
下面是构建二分搜索树的程序,测试程序也在内,读入"bible.txt"文件,查找里面的“god”
#include <iostream>
#include <vector>
#include <string>
#include <ctime> //time()函数
#include "FileOps.h"
using namespace std;
template<typename Key, typename Value>
class BST{
private:
struct Node{
Key key;
Value value;
Node *left;
Node *right;
Node(Key key, Value value){
this->key = key;
this->value = value;
this->left = this->right = NULL;
}
};
Node *root;
int count;
public:
BST(){
root = NULL;
count = 0;
}
~BST(){
// TODO: ~BST()
}
int size(){
return count;
}
bool isEmpty(){
return count == 0;
}
void insert(Key key, Value value){
root = insert(root, key, value);
}
bool contain(Key key){
return contain(root, key);
}
Value *search(Key key){
return search(root, key);
}
private:
//向以node为根的二叉搜索树中,插入节点(key, value)
//返回插入新节点后的二叉搜索树的根
//递归插入
Node* insert(Node *node, Key key, Value value){
if (node == NULL){
count++;
return new Node(key, value);
}
if(node->key == key)
node->value = value;
else if (key < node->key)
node->left = insert(node->left, key, value);
else
node->right = insert(node->right, key, value);
return node;
}
//查找以node为根的二叉搜索树中是否包含键值为key的节点
bool contain(Node *node, Key key){
if (node == NULL){
return false;
}
if (key == node->key)
return true;
else if (key < node->key)
return contain(node->left, key);
else
return contain(node->right, key);
}
//在以node为根的二叉搜索树中查找key对应的value
Value* search(Node *node, Key key){
if (node == NULL)
return NULL;
if (key == node->key)
return &(node->value);
else if (key < node->key)
return search(node->left, key);
else
return search(node->right, key);
}
};
int main() {
string filename = "E:/Code/BinaryTree/bible.txt";
vector<string> words;
if( FileOps::readFile(filename, words) ) {
cout << "There are totally " << words.size() << " words in " << filename << endl;
cout << endl;
// test BST
time_t startTime = clock();
BST<string, int> bst = BST<string, int>();
for (vector<string>::iterator iter = words.begin(); iter != words.end(); iter++) {
int *res = bst.search(*iter);
if (res == NULL)
bst.insert(*iter, 1);
else
(*res)++;
}
cout << "'god' : " << *bst.search("god") << endl;
time_t endTime = clock();
cout << "BST , time: " << double(endTime - startTime) / CLOCKS_PER_SEC << " s." << endl;
cout << endl;
}
return 0;
}
FileOps.h为
//FileOps.h
#include <string>
#include <iostream>
#include <fstream>
#include <vector>
using namespace std;
namespace FileOps{
int firstCharacterIndex(const string& s, int start){
for( int i = start ; i < s.length() ; i ++ )
if( isalpha(s[i]) )
return i;
return s.length();
}
string lowerS( const string& s){
string ret = "";
for( int i = 0 ; i < s.length() ; i ++ )
ret += tolower(s[i]);
return ret;
}
bool readFile(const string& filename, vector<string> &words){
string line;
string contents = "";
//ifstream file(filename);
ifstream file("E:/Code/BinaryTree/bible.txt");
if( file.is_open() ){
while( getline(file, line))
contents += ( line + "\n" );
file.close();
}
else{
cout<<"Can not open "<<filename<<" !!!"<<endl;
return false;
}
int start = firstCharacterIndex(contents, 0);
for( int i = start + 1 ; i <= contents.length() ; ){
if( i == contents.length() || !isalpha(contents[i]) ){
words.push_back( lowerS( contents.substr(start,i-start) ) );
start = firstCharacterIndex(contents, i);
i = start + 1;
}
else{
i ++;
}
}
return true;
}
}
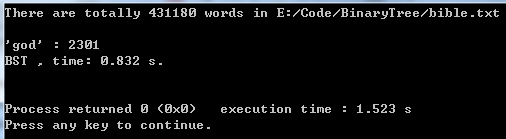
输出为