一、摘要
这篇论文提出一个系统,在大范围主题的知识库中,学习使用较少的手工特征来回答问题。我们的模型学习单词和知识库组成的低维词向量。这些表示用于根据候选答案对自然语言问题打分。使用成对的问题和对应答案的结构化表示,和成对的问题释义来训练系统,在最近的文献基准中产生有竞争力的结果。
二、介绍
开放域QA最先进的技术可以分为两大类,即基于信息抽取和基于语义解析。信息抽取系统首先通过查询KB的搜索API将问题转换为正确的查询来检索一组广泛的候选答案,然后使用细粒度检测启发式方法来确定正确的答案。语义解析通过语义解析系统侧重于正确解释问题的含义。最近的研究表明这种系统可以在间接和不完善的监督下进行有效的训练,从而达到大规模管理的规模,同时绕过大多数注释成本。
尽管这样的系统可以处理大规模知识库,但是仍然需要专家手工制作词典、语法和知识库模式才能有效。这种人为的方法可能不通用,无法方便地扩展到其他模式的新知识库,更广泛的词汇或其他语言。于是作者提出了一个几乎不需要人工注释的开放域QA的框架,《Open question answering with weakly supervised embedding models》【5】介绍了一种嵌入模型,学习单词和符号的低维向量表示,并且可以在比系统更少的监督下训练,同时获得更好的预测性能。但是,这个方法只与《Paraphrase-driven learning for open question answering》这篇论文进行了比较,这篇论文在简化的环境中运行,并未应用于更现实的场景,也未针对性能最佳的方法进行评估。
在本文中,我们通过提供回答更复杂问题的能力来改进【5】的模型。这篇论文的主要贡献在于:更复杂的推理过程更有效并且可以考虑更长的路径(【5】只考虑到在图中答案直接连接到问题的情况);更丰富的答案表示,它对KB的问答路径和周围子图进行编码。我们的方法与目前最新技术的基准WebQuestions相比更有竞争力,在训练过程中不像大多数其他系统一样,没有使用任何词库、规则、词性标记的额外系统、语法或依存分析。
三、任务定义
我们主要动机是为开放域QA提供一个系统能够训练,只要它能访问:一组问题与答案配对的训练集;提供答案中的结构的KB。我们假设全部潜在的答案都是KB的实体,问题是单词的序列,并且报告一个确定的KB实体。当实体不确定时,简单的字符串匹配来识别实体。数据的处理这里不做介绍。

四、问题和答案的嵌入
q表示问题,a表示答案,学习词嵌入是通过学习一个评分函数 S(q,a),如果a是q的正确答案,那么S越大。q和a都表示为各个单词和 / 或符号嵌入的组合。评分函数的形式如下:

W是R (kxN)的一个矩阵,k是词向量的维度,N是词典的大小。N表示全部单词数,Ns表示全部的实体和关系数。N = Nw + Ns。W的第i列表示在词典的第 i 个单词 (或 实体、关系)的词向量。函数f(.)将问题映射到词向量空间,定义为 f(q) = WΦ(q), Φ(q)是一个离散向量,表示每个单词出现在问题q中的次数。同理,g(.)表示将答案映射到相同的词向量空间,g(a) = WΦ(a)。Φ(a)是答案的离散向量表示。
1.表示候选答案
- 单一实体。答案表示为FreeBase的单一实体。Φ(a)是一个1-of-NS编码向量(我的理解就是Ns维的向量中,某一维为1,其余为0),对应答案实体位置为1,其它位置为0.
- 路径表示。答案表示为从问题中的实体到答案实体的路径。实验过程中,我们考虑1或2跳路径。比如 (barack_obama,people.person.place_of_birth,honolulu)是1跳路径;(barack_obama,people.person.place_of_birth,location.location.containedby,hawaii)是2跳路径。那么Φ(a)是3-of-NS或4-of-NS的编码向量,表示路径中开始和结束的实体以及关系类型。
- 子图表示。我们编码来自(ii)的路径表示和连接到候选答案实体的实体的整个子图。对每一个连接到答案的实体,表示Φ(a)包括了关系类型和实体本身。为了表示答案路径不同于周围的子图(因此模型可以区分他们)。我们将实体的字典大小加倍,如果他们在路径中使用一种向量表示,在子图中使用另外一种。因此我们学习一个参数矩阵R (kxN),N=Nw + 2Ns。
上述整个流程如下图:

2.训练和损失函数
我们使用基于margin的排名损失函数来训练模型,让D={(qi,ai):i=1,...,|D| }表示训练集,最小化损失函数:
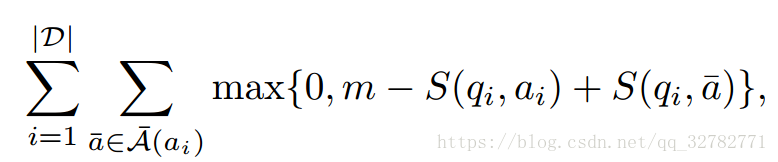
其中m是margin(固定值0.1),学习词向量矩阵W,使得问题与正确答案配对的分数大
于任何与错误答案配对的分数。使用Hogwild提出的多线程SGD进行优化。
3.词向量的多任务训练
由于我们的训练数据集中的大量问题是综合生成的,因此它们不能充分涵盖自然语言中
使用 的语法范围。因此我们通过释义检测任务来多任务训练模型。我们通过将S的训练与评
分函数的训练交替进行,使用相同的词向量矩阵,如果它们是释义,那么q1和q2词向量相
似。
五、实验
根据问题首先要确定候选答案,这里作者确定候选答案的方式和信息抽取略有不同。首先在
从问题中主题词对应的知识库实体出发,通过beam search的方式保存10个和问题最相关的实体
关系(通过把实体关系当成答案,用式子的得分作为beam search的排序标准)。接下来选取主
题词两跳范围以内的路径,且该路径必须包含这10个关系中的关系,将满足条件的路径的终点对
应的实体作为候选答案,其中,1跳路径的权值是2跳的1.5倍(因为2跳包含的元素更多)。确定
完候选答案后,选取 S(q,a) 得分最高的作为最终答案。实验结果如下:
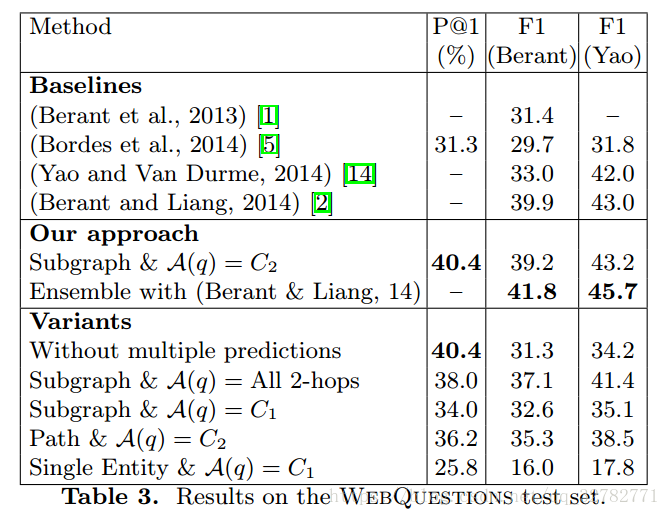
六、总结
这篇论文的优点在于提出了一个不需要人工特征的词向量模型,同时也扩充了训练集。在问题和答案的表示上类似于BOW,这就会引入两个问题,向量会很稀疏,并且这种表示是没有考虑词序问题的。