Spark2.0笔记
spark核心编程,spark基本工作原理与RDD
1. Spark基本工作原理
2. RDD以及其特点
3. 什么是Spark开发
1.Spark基本工作原理
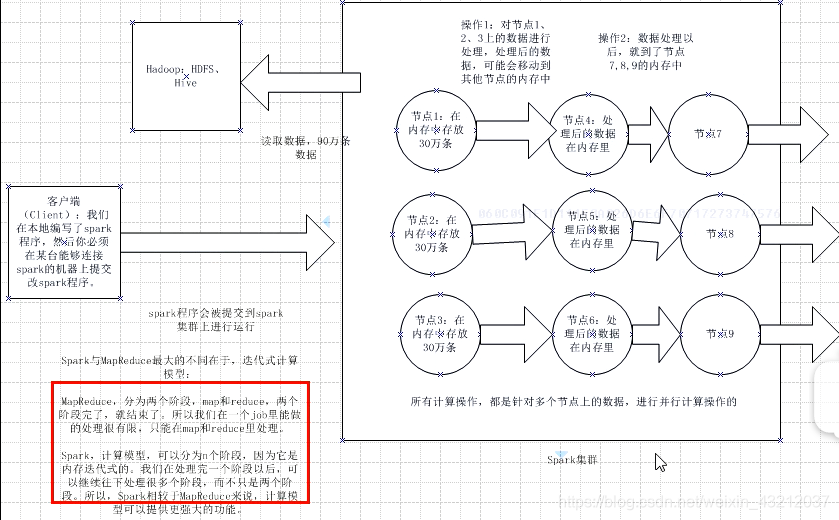
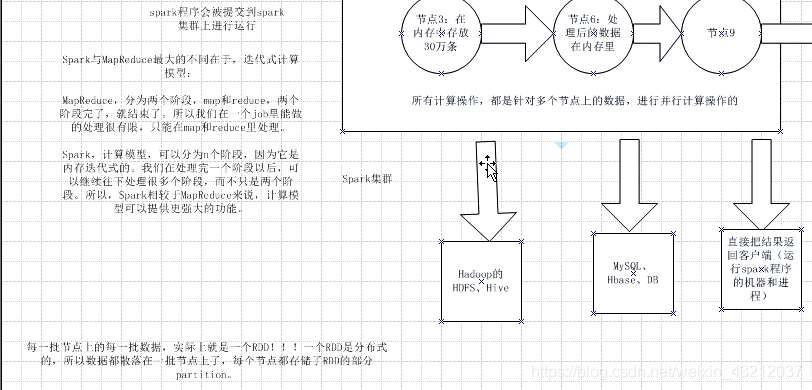
2. RDD以及其特点
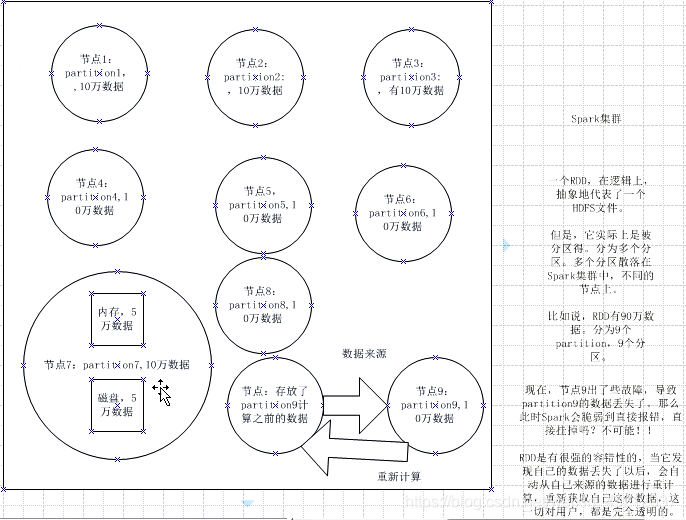
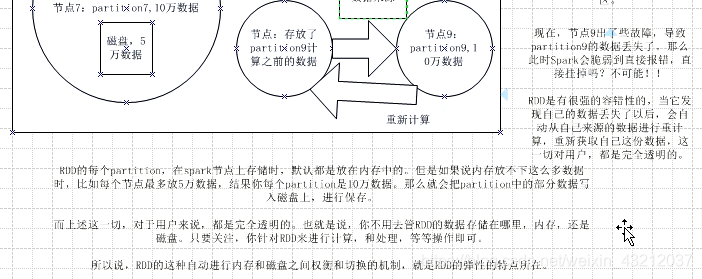
3. 什么是Spark开发
spark核心编程:
第一:定义初始的RDD,要定义的第一个RDD是从哪里读取数据,hdfs,linux本地文件,程序中的集合。
第二:定义对RDD的计算操作,这个在Spark称之为算子,map、reduce、flatmap,groupbykey。比hadoop提供的Map Reduce强大。
第三:其实就是循环往复的过程。第一个计算提交了之后,数据可能就会到了新的一批节点上,也就是变成了一个新的RDD,然后对新的RDD定义新的计算操作。
第四:获得最终的数据,把结果保存起来。
核心开发、SQL查询、实时计算底层都是RDD和计算操作。
4.spark中RDD的partition:
我们要想对spark中RDD的分区进行一个简单的了解的话,就不免要先了解一下hdfs的前世今生。hdfs是一个分布式文件系统。
hdfs文件为分布式存储,每个文件都被切分为block(默认为128M)。为了达到容错的目的,他们还提供为每个block存放了N个副本(默认为3个)。当然,以上说的这些也可以根据实际的环境业务调整。
多副本除了可以达到容错的目的,也为计算时数据的本地性提供了便捷。当数据所在节点的计算资源不充足时,多副本机制可以不用迁移数据,直接在另一个副本所在节点计算即可。此时看到这里,肯定就有人会问了,那如果所有副本所在的节点计算资源都不充足那该怎么办?
问的很好,一般会有一个配置来设置一个等待时长来等待的,假设等待时长为三秒,如果超过三秒,还没有空闲资源,就会分配给别的副本所在节点计算的,如果再别的副本所在节点也需等待且超过了三秒。则就会启动数据迁移了(诸多因素影响,代价就比较大了)。
接下来我们就介绍RDD,RDD是什么?弹性分布式数据集。
弹性:并不是指他可以动态扩展,而是血统容错机制 (可以参考spark的容错机制)。
分布式:顾名思义,RDD会在多个节点上存储,就和hdfs的分布式道理是一样的。hdfs文件被切分为多个block存储在各个节点上,而RDD是被切分为多个partition。不同的partition可能在不同的节点上。(这句话是本文最为核心的,详情可以看下面,这里partition和block不单单是类比,还有他们之间的联系,partition可以看做block的一个上层结构,下层有HDFS的block组成)
再spark读取hdfs的场景下,spark把hdfs的block读到内存就会抽象为spark的partition。至于后续遇到shuffle的操作,RDD的partition可以根据Hash再次进行划分(一般pairRDD是使用key做Hash再取余来划分partition)。
再spark计算末尾,一般会把数据做持久化到hive,hbase,hdfs等等。我们就拿hdfs举例,将RDD持久化到hdfs上,RDD的每个partition就会存成一个文件,如果文件小于128M,就可以理解为一个partition对应hdfs的一个block。反之,如果大于128M,就会被且分为多个block,这样,一个partition就会对应多个block。
鉴于上述partition大于128M的情况,在做sparkStreaming增量数据累加时一定要记得调整RDD的分区数。假设,第一次保存RDD时10个partition,每个partition有140M。那么该RDD保存在hdfs上就会有20个block,下一批次重新读取hdfs上的这些数据,RDD的partition个数就会变为20个。再后续有类似union的操作,导致partition增加,但是程序有没有repartition或者进过shuffle的重新分区,这样就导致这部分数据的partition无限增加,这样一直下去肯定是会出问题的。所以,类似这样的情景,再程序开发结束一定要审查需不需要重新分区。