一 分布式系统
分布式系统的由来:
国内来讲,移动互联网的爆发伴随着分布式系统的突现,移动互联网最大的特点是2(to)c的o2o产品越来越多,这跟传统2B的系统最大区别就是用户量的不同,2C系统的用户量远远要高于2b系统,这就对系统提出了各种各样的高标准,响应时间,性能,灾备,吞吐量等等,各种分布式技术也是为了这些标准而服务。
分布式架构的应用:
分布式文件系统
分布式缓存系统
分布式数据库
分布式WebService
分布式计算
举例说明:
分布式文件系统: 出名的有 Hadoop 的HDFS ,还有 google的 GFS , 淘宝的 TFS 等
分布式缓存系统:memcache , hbase , mongdb 等
分布式数据库 : MySQL , Mariadb, PostgreSQL 等
以分布式MySQL数据库中间件MyCat 为例子,MySQL 在现在电商以及互联网公司的应用非常多,一个是因为他的免费开源,另外一个原因是因为分布式系统的水平可扩展性,随着移动互联网用户的暴增,互联网公司,像淘宝,天猫,唯品会等电商都采用分布式系统应对用户的高并发量以及大数据量的存储。
而在Mycat的商业案例中,有对中国移动的账单结算项目中,应用实时处理高峰期每天2亿的数据量,在对物联网的项目中,实现处理高达26亿的数据量,并提供实时查询的接口。
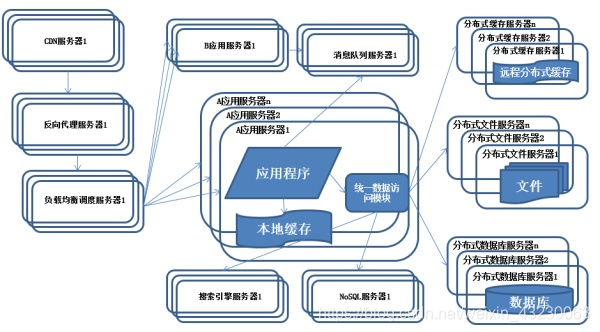
二 大型分布式网站系统的性能要求
1.响应时间(Response time)
2-5-8原则:(据统计当网站慢一秒就会流失十分之一的客户)
当用户再2-5秒之间得到响应时,会感觉系统的响应速度还可以;
当用户再5-8秒内得到响应时,感觉蛮,但是还可以接受;
当用户大于8秒内得到响应时,感觉无法接受;
2.吞吐量(Throughput)
指的是在单位时间内客户端和服务器成功传送数据的数量;
3.资源使用率(Resource utilization)
常见的有:cpu占用率、内存使用率、磁盘I/O、网络I/O;
4.每秒点击数(Hits per Second)
客户端每秒向服务器提交的请求数量,如果客户端发出的请求数量越多,与之相对的平均吞吐量也应该越大;
5.并发用户数(Concurrent users)
客户端的同一批用户同时执行一个操作的数量。
三 Java后台技术
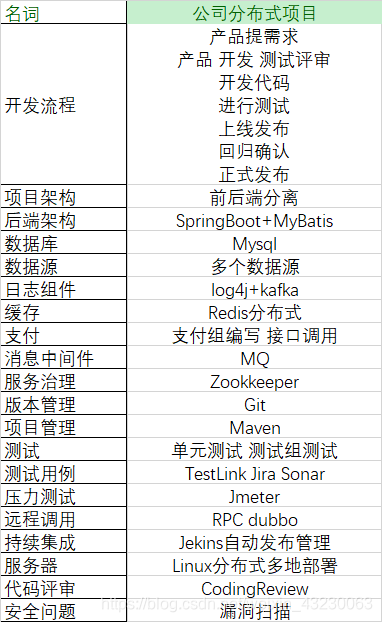
四 技术名词解释
-
分布式和集群
分布式和集群在通常情况下不做严格区分,正如同并发和并行一样,应用情况下很少会去考究它的区别,许多大公司面试也直接问分布式集群怎样怎样,一般都拿等同来讲了。在这里只在概念上做一下区别,使大家更合理的去理解,没有对错之分。
分布式:一个电商系统,用户模块部署在server1, 订单模块部署在server2, 促销模块部署在server3, 商品模块部署在server4,他们之间通过远程rpc实现服务调用,这就叫分布式。强调的是不同功能模块,单独部署在不同的server上,所有server加起来是一个完整的系统。
集群:更多强调的是灾备,一个电商系统,完整的部署在server1上一个,完成的部署在server2上一个,server1宕机后,server2仍然可以正常提供请求服务,这叫集群。同样对于某一功能模块,比如用户模块部署在server1上,同样部署在server2上,也叫做集群。分布式系统的每个功能模块节点,都可以用多机做成集群。
抽象问题具体化:拿做菜示例,假如一个厨师做菜要经历切菜,炒菜两个功能,饭店为了提高速度招了两个厨师,每个厨师的工作一样,都是切菜,炒菜,这是集群。还有另一种方法提高效率,饭店招了一个切菜师傅,配合厨师,厨师不管切菜,只管炒菜了,和切菜师傅共同配合把菜做好,这叫分布式。
-
Nginx
作用是反向代理和负载均衡。
反向代理是指请求真实是到server1的,但是系统中为了统一或者做比如单点登录,会在server2服务器上安装一个nginx,里面配置到server1的反向代理,那么之后请求url就可以写server2的地址,发出后到server2, server2会转发到server1上,类似一种代理的模式。
负载均衡是指如果一个系统的请求很多,我们可以把请求转发到不同的服务器上,用来分流。就类似于接了一个水管放水,水流量很大时候,水压大很可能会让一个水管爆炸,这时候接三个水管,就没问题了(这三个水管就是一个集群)。类似的在nginx服务器中配了3个tomcat服务器,每个tomcat服务器上都部署了整个系统,那么当请求数大的时候,可以分发到不同的tomcat。(其实这里每个tomcat上部署同一个功能模块也叫集群)
-
Java在分布式下的通信
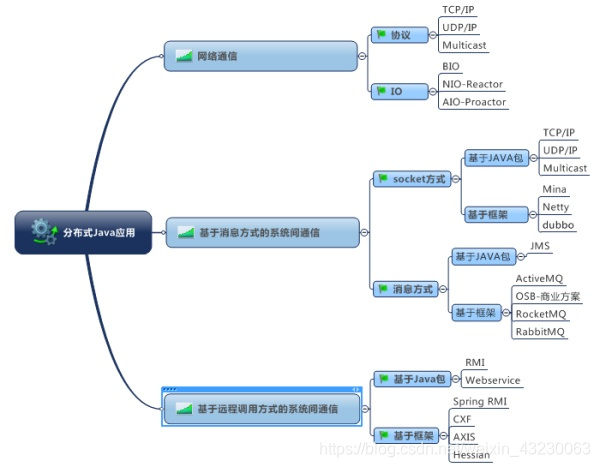
RPC(远程过程调用)
对于分布式系统来讲,tomcat1上部署了用户模块,tomcat2上部署了订单模块,当用户下单时,请求到tomcat2,这时候可能要判断这个用户是否是vip,或者是否有优惠券,这些方法是在tomcat1用户模块上的,那么tomcat2调用tomcat1的服务获取这些信息,就叫rpc调用。常见的rpc框架:轻量级的hessian, 阿里dubbo(当当dubbox), 新浪Motan, apache的Thrift,google的grpc, 百度的brpc, 腾讯的tars。
rpc调用底层涉及到对象的序列化,反序列化,http/tcp传输,网络异步传输netty。
-
消息中间件(MQ)
mq消息中间件在分布式系统中的作用有很多,但是经常用到的还是异步解耦。
比如天猫下单流程,当用户支付后,后台接口执行的操作可能包括:1 验签,2 支付密码校验,3 扣库存,4 用户积分增加等等操作,其实我们希望的是2操作执行成功后立即给用户结果提示,而不是等到后续各个操作完成后才去提示,因为后续的操作往往大部分是rpc调用,方法执行时间相对较长。另外对于下单支付这个操作,3和4是后续业务的需要,在设计上不能和下单支付本身出现强耦合度。所以这里我们可以引入mq解决,也就是说1和2执行完成后,生产者只需要通知下3和4,把后续的操作扔给消息队列,立即返回。这里的mq起到的作用一个是异步调用,一个是解耦。
-
NoSQL(非关系型数据库)
NoSQL是所有非关系型数据库的统称,在分布式系统中用到很多,主要用来提高QPS(query per second)。
Redis: 我们讲缓存,或者内存数据库,小巧强大,什么数据适合放在redis也就是缓存中,一个是经常查询的,需要频繁磁盘io的,例如有个快件系统,有个需求是当快件状态为异常时候,需要发送邮件提醒给系统管理员。接口入参是快件id,通常做法我们需要拿到id,去数据库查状态,然后发送,但是快件基数很大时候每天的问题件也可能会很多,接口调用频繁时候就需要改进做法,这时我们可以把快件状态信息放在redis里面,key是快件id, value是快进状态,每次进入接口时候直接redis里面取status就可以,速度很快。另一个是查询数据缓慢的,可以放在缓存中。
MongoDB: 可称为分布式文件数据库,可用来存储海量数据,它是NoSQL里面最像关系型数据库的,它的数据的存储形式可以就理解为json格式。之前曾经两次用到过mongoDB,一次是系统里面有个实时监控设备电流电压的功能,硬件设备实时会把数据同步到数据库里面,我们系统2-3s需要去拉次列表。另一个系统是一个轻型的行业IM工具,每天会有很大的聊天数据存储,我们直接用了mongoDB存储,后来系统相当稳定,从来没有出现过性能瓶颈。