爱卡汽车论坛搜索结果页面:
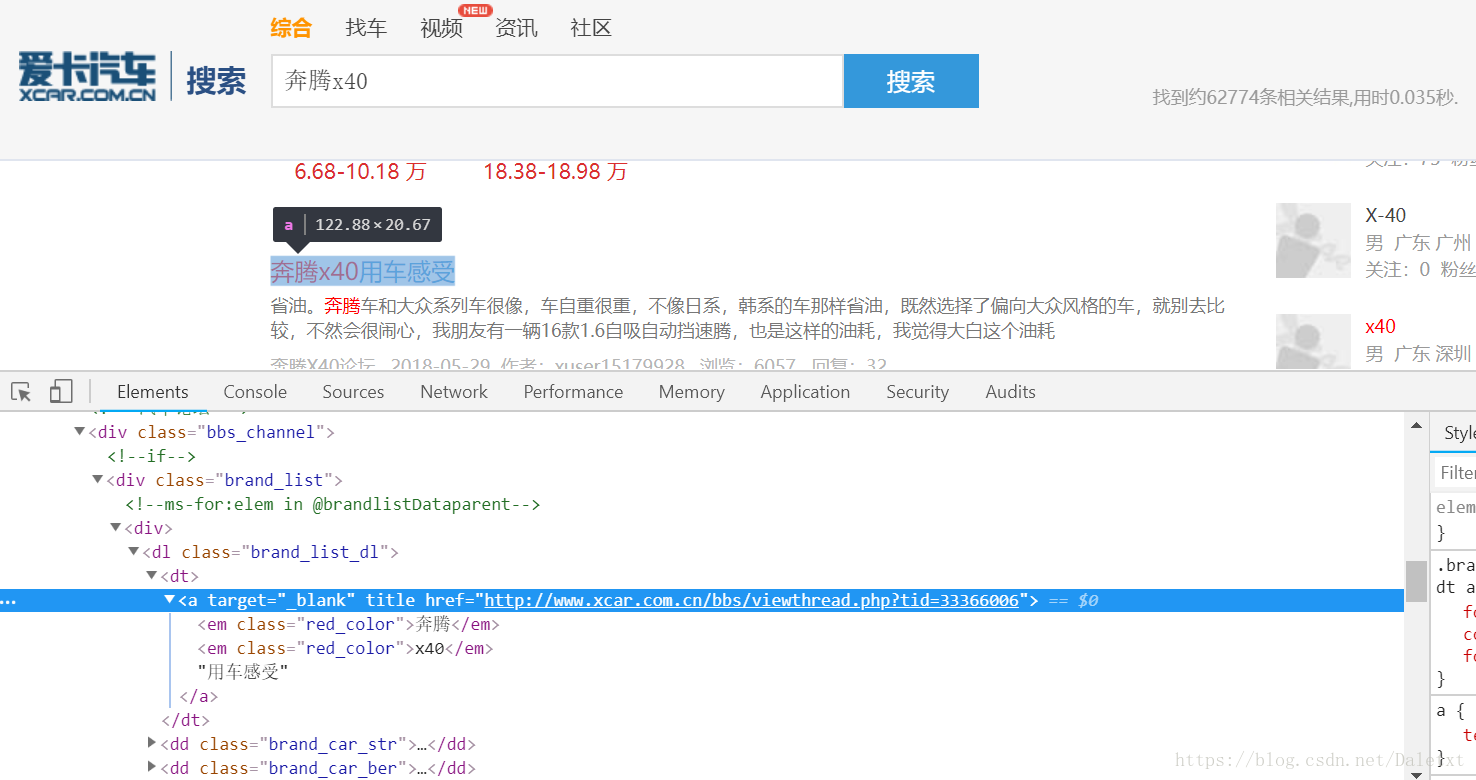
想要python爬取搜索结果链接:a标签中的href,但是这个url是动态生成的。
网页源代码:

用普通方式解析:
import urllib.request
url = "http://search.xcar.com.cn/metasearch.php#?&searchValue=奔腾x40"
data = urllib.request.urlopen(url).read()
data = data.decode('UTF-8')
print(data)
解析结果:

selenium:这是一个用于web应用程测试的工具
下载方式:pip install selenium
phantomjs
是一种无界面的浏览器,用于完成网页的渲染
下载地址
http://phantomjs.org/download.html
解压就可以用
打开解压后的文件,找到bin下的phantomjs.exe将这个路径放到PATH路径下
动态解析:
from selenium import webdriver
url = "http://search.xcar.com.cn/metasearch.php#?&searchValue=奔腾x40"
driver = webdriver.PhantomJS(executable_path='E:/phantomjs/bin/phantomjs.exe')
#这个路径就是你添加到PATH的路径
driver.get(url)
print (driver.page_source)
解析结果:

下一步如何取出:
参考文章:http://www.freebuf.com/column/142404.html
继续: