一,三,四都参考:
- https://www.cnblogs.com/supiaopiao/p/7240308.html
- https://blog.csdn.net/u010185220/article/details/79095179/
- https://blog.csdn.net/qq_14809913/article/details/81705273
- https://www.cnblogs.com/xinaixia/p/7641612.html
hadoop location指的是hadoop集群位置或者win10安装hadoop的位置
注意:win10系统下,蓝色部分必须设置,Linux的hadoop集群下可以不设置,会同意放在hadoop安装目录下的自定义目录,如hadoop/data/tem,都没设置则放在Linux根目录下的tem目录
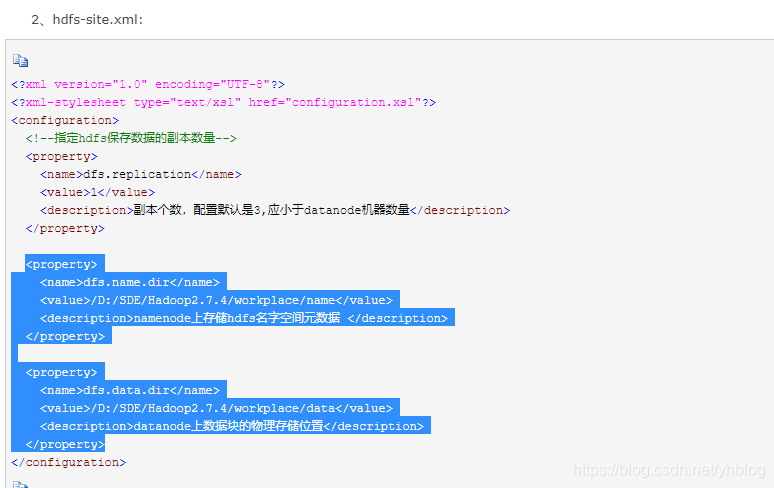
<property>
<name>dfs.name.dir</name>
<value>/D:/SDE/Hadoop2.7.4/workplace/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/D:/SDE/Hadoop2.7.4/workplace/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
win10下eclipse安装hadoop-eclipse-plugin-2.7.3.jar成功后如下
windows-》preference
windows-》show view

- win10启动hadoop后运行窗口可能没有消失,不能关闭,否则会关闭对应服务,把窗口缩小即可
-
win10下eclipse直接运行mapreduce程序
一。
1.解压hadoop安装包,并配置jdk和hadoop的环境变量
2.直接创建一个java工程,到后导入hadoop的lib依赖包,build path
3.直接运行
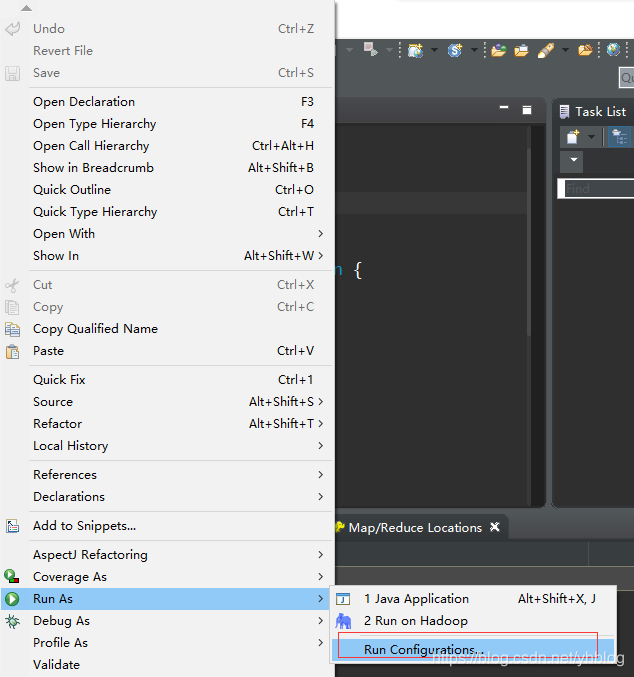
写好输入数据参数和输出数据的参数后点击Run就可以运行

运行结果:
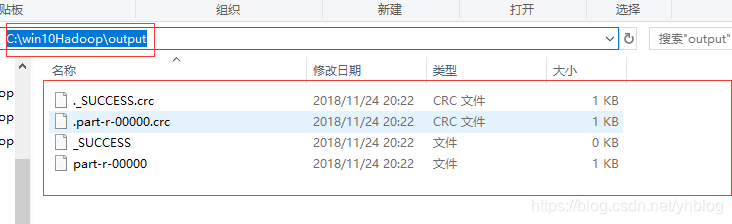
-
win10下eclipse编辑mapreduce在Linux的hadoop集群上运行
二。
1.安装hadoop-eclipse-plugin-2.7.3.jar(该jar包用来连接hadoop或者hadoop集群的,可以是连接windows下的,也可以连接Linux下的,通过配置)
参考:https://blog.csdn.net/psp0001060/article/details/54728436
Map/Reduce Master没有设置的话默认是50020(点击finish,若没有报错,则表示连接成功,在Eclipse左侧的DFS Locations中可以看到HDFS文件系统的目录结构和文件内容;
若遇到 An internal error occurred during: “Map/Reduce location status updater”. java.lang.NullPointerExcept的问题,则表示当前HDFS文件系统为空,只需在HDFS文件系统上创建文件,刷新DFS Locations后即可看到文件系统内容;)

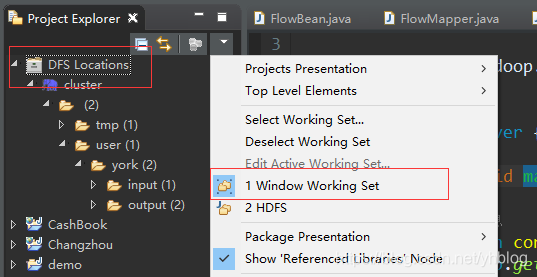
连接成功后(一定注意,如果eclipse中有其他工作集,一定切换到默认的工作集,不然看不到DFS Location)
2.安装hadoop及配置环境变量
3.启动hadoop,eclipse连接,再运行项目程序
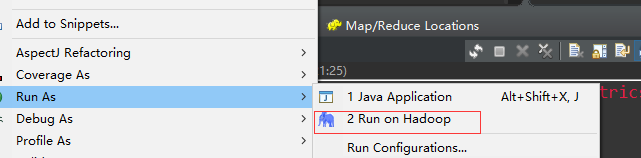
-
win10下eclipse编辑mapreduce在win10本地hadoop上运行
三。
1.与Linux中集群运行性质一样,两个不同点(连接和运行前先配置)
一是连接配置信息不一样
二是在输入数据的路径和输出数据的参数路径不一样,因为一个是集群路径,一个是win10系统路径

**maptask原理:**https://www.cnblogs.com/acSzz/p/6383618.html
**reducetask:**https://blog.csdn.net/luomingkui1109/article/details/80950857