YOLOv1 是这周看的跟目标检测相关的第5篇paper,在了解了rcnn系列paper的work原理之后,YOLO还是有很大不同的,rcnn系列的论文要么通过ss方法要么通过RPN 产生bounding box,对每个产生的bounding box进行分类检测,而YOLO则从全局的角度出发,将ob任务当作一个regression任务,一次输入图片直接产生图片中bounding box的 coordinate 和类别概率。即 you only look once! YOLO最大的特点是解决了OB任务中速度慢的问题 基础YOLO版本GPU可以达到45fps 快速的可达155ps!
论文下载:http://arxiv.org/abs/1506.02640
代码下载:https://github.com/pjreddie/darknet
目录
1.YOLO的网络结构
YOLO的核心思想即将原图片分成S*S个cell,如果某个object落在这个cell中,这个cell就负责预测这个object的类别。(在此做了一个粗略估算,即一个cell中只有一个object,这样做近似显然影响YOLO对于密集小物体的召回率,但胜在速度很快。)。
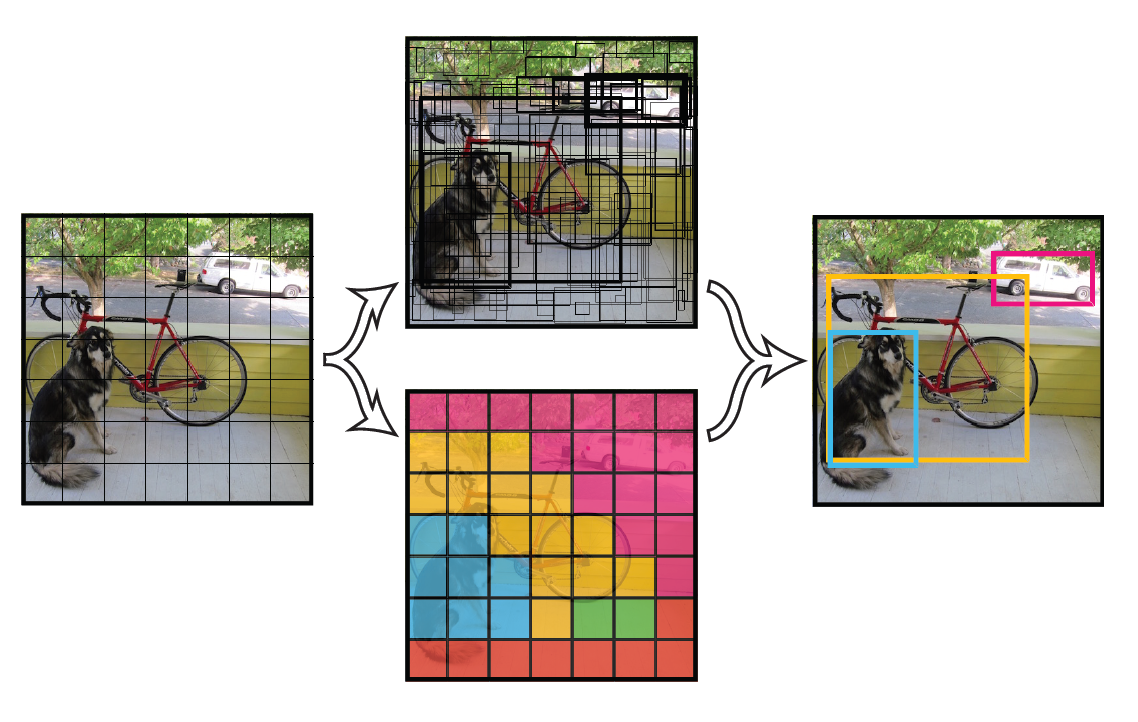
在此强调一个坑:这里所指的物体落入某个cell,是指物体的中心点落入这个cell,比如下图,狗的中心点落在这个cell中,那么这个cell就负责预测狗。

每一个cell 将会预测B个bounding box,并对每一个bounding box预算一个置信度 confidence,同时预测这个cell中物体的类别。所谓置信度包含了两个方面的考虑,bounding box中是否落入物体的可能性以及这个bounding box的准确度,前者记为Pr(object),当该边界框是背景时(即不包含目标),此时Pr(object)=0。而当该边界框包含目标时,Pr(object)=1。边界框的准确度可以用预测框与实际框(ground truth)的IOU(intersection over union,交并比)来表征,记为IOUtruthpred,因此置信度可以定义为Pr(object)∗IOUtruthpred。对于B个bounding box,预测(x,y,w,h),x,y代表中心点距离这个cell的偏移,w,h代表bounding box 相对于整张图片的W,H所占的比例还有分类问题,对于每一个单元格其还要给出预测出C
个类别概率值,其表征的是每一个cell中产生的bounding box负责的物体的类别概率。注意这里的类别概率是一个条件概率,是在该cell中存在object的时候,即cell中每一个bounding box的置信度不为0的情况下,即Pr(classi|object)。这里注意的一点是不管一个cell最后产出多少个bounding box,最终只输出一个概率,取置信度最高的那个bounding box来负责对这个object的类别进行预测,这是YOLO的一个缺点,即可能存在漏检查的情况。同时,我们可以计算出各个边界框类别置信度,Pr(classi|object)∗Pr(object)∗IOUtruthpred=Pr(classi)∗IOUtruthpred。边界框类别置信度表征的是该边界框中目标属于各个类别的可能性大小以及边界框匹配目标的好坏。后面会说,一般会根据类别置信度来过滤网络的预测框。
总结一下,每个单元格需要预测(B∗5+C)个值。如果将输入图片划分为S×S网格,那么最终预测值为S×S×(B∗5+C)
大小的张量。整个模型的预测值结构如下图所示。对于PASCAL VOC数据,其共有20个类别,如果使用S=7,B=2
,那么最终的预测结果就是7×7×30大小的张量。在下面的网络结构中我们会详细讲述每个单元格的预测值的分布位置。
举例说明: 在PASCAL VOC中,图像输入为448x448,取S=7,B=2,一共有20个类别(C=20)。则输出就是7x7x30的一个tensor。
整个网络结构如下图所示:

输入为448*448彩色图像,比RCNN系列增大一倍。其中包含24或9个卷积层(fast-YOLO),基本遵循googLeNet2的设计,降采样为,输出7*7*1024的特征图。两个全连层从特征图回归出每个网格的30个预测。
2.训练
output
如果目标的中心在一个网格内部,称为“目标在网格内”。
真实数据记为:
,
,:网格i中目标的左上角位置
,
,:网格i中目标的尺寸
,:网格i的第j个bounding box和目标的IOU的乘积
,:网格i的1-hot编码分类概率
对于每一个网格i,输出B*4个定位结果(目标在哪里):
xij,yij:bounding box左上角位置
wij,hij:bounding box尺寸
B个检测结果(是目标的可能性):
Cij:bounding box属于目标的概率
以及C个分类结果(目标是哪一类):
pi:长度为类别数的向量
代价

代价包含以下三个方面
【定位代价】考察每个含有目标的网格中置信度最高的的bounding box:应该与目标位置近似。


【检测代价】考察每个网格中置信度最高的预测结果:如果网格含有目标,应等于目标与bounding box的IOU;如果网格不含目标,应为0。

【分类代价】考察每个含有目标的网格

这里详细讲一下loss function。在loss function中,前面两行表示localization error(即坐标误差),第一行是box中心坐标(x,y)的预测,第二行为宽和高的预测。这里注意用宽和高的开根号代替原来的宽和高,这样做主要是因为相同的宽和高误差对于小的目标精度影响比大的目标要大。举个例子,原来w=10,h=20,预测出来w=8,h=22,跟原来w=3,h=5,预测出来w1,h=7相比,其实前者的误差要比后者小,但是如果不加开根号,那么损失都是一样:4+4=8,但是加上根号后,变成0.15和0.7。
第三、四行表示bounding box的confidence损失,就像前面所说的,分成grid cell包含与不包含object两种情况。这里注意下因为每个grid cell包含两个bounding box,所以只有当ground truth 和该网格中的某个bounding box的IOU值最大的时候,才计算这项。 第五行表示预测类别的误差,注意前面的系数只有在grid cell包含object的时候才为1。
所以具体实现的时候是什么样的过程呢?
训练的时候:输入N个图像,每个图像包含M个objec,每个object包含4个坐标(x,y,w,h)和1个label。然后通过网络得到7*7*30大小的三维矩阵。每个1*30的向量前5个元素表示第一个bounding box的4个坐标和1个confidence,第6到10元素表示第二个bounding box的4个坐标和1个confidence。最后20个表示这个grid cell所属类别。注意这30个都是预测的结果。然后就可以计算损失函数的第一、二 、五行。至于第二三行,confidence可以根据ground truth和预测的bounding box计算出的IOU和是否有object的0,1值相乘得到。真实的confidence是0或1值,即有object则为1,没有object则为0。 这样就能计算出loss function的值了。
3.预测
在test的时候,每个网格预测的class信息和bounding box预测的confidence信息相乘,就得到每个bounding box的class-specific confidence score:

等式左边第一项就是每个网格预测的类别信息,第二三项就是每个bounding box预测的confidence。这个乘积即encode了预测的box属于某一类的概率,也有该box准确度的信息。得到每个box的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
测试的时候:输入一张图像,跑到网络的末端得到7*7*30的三维矩阵,这里虽然没有计算IOU,但是由训练好的权重已经直接计算出了bounding box的confidence。然后再跟预测的类别概率相乘就得到每个bounding box属于哪一类的概率。
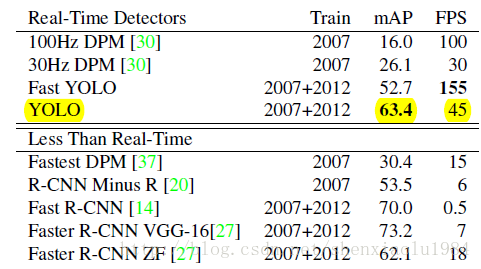
4.YOLO实验
作为实时检测器,YOLO在PASCAL VOC上取得了不错的性能
将YOLO与Fast-RCNN的分类结果进行比较,得到两个十分有启发性的结论:
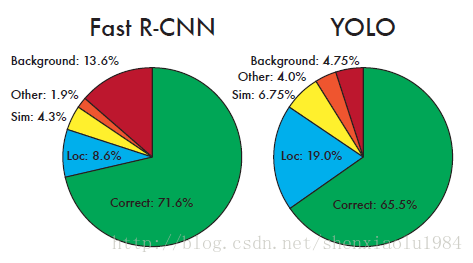
| 错误 | 解释 | 比较 | 原因 |
|---|---|---|---|
| 虚警(红) | 将背景误判为目标 | YOLO更佳 | YOLO在训练时,将整张图像送入网络,上下文信息更丰富 |
| 定位(蓝) | 类别正确,位置偏差 | YOLO更差 | YOLO的候选框受网格限制 |
5.YOLO缺点
YOLO对相互靠的很近的物体,还有很小的群体 检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
对测试图像中,同一类物体出现的新的不常见的长宽比和其他情况是。泛化能力偏弱。
由于损失函数的问题,定位误差是影响检测效果的主要原因。尤其是大小物体的处理上,还有待加强。
6.常见问题
1.为什么每个cell中只取一个置信度最高的bounding box?
原文说的意思是指定一个预测器“负责”根据哪个预测与真实值之间具有当前最高的IOU来预测目标。会使每个预测器可以更好地预测特定大小,方向角,或目标的类别,从而改善整体召回率。
2.YOLO准确度下降原因?
每个网格默认1类 ,多次下采样等原因
3.一个grid cell中是否有object怎么界定?
首先要明白grid cell的含义,以文中7*7为例,这个size其实就是对输入图像(假设是224*224)不断提取特征然后sample得到的(缩小了32倍),然后就是把输入图像划分成7*7个grid cell,这样输入图像中的32个像素点就对应一个grid cell。回归正题,那么我们有每个object的标注信息,也就是知道每个object的中心点坐标在输入图像的哪个位置,那么不就相当于知道了每个object的中心点坐标属于哪个grid cell了吗,而只要object的中心点坐标落在哪个grid cell中,这个object就由哪个grid cell负责预测,也就是该grid cell包含这个object。另外由于一个grid cell会预测两个bounding box,实际上只有一个bounding box是用来预测属于该grid cell的object的,因为这两个bounding box到底哪个来预测呢?答案是:和该object的ground truth的IOU值最大的bounding box。
7.YOLO源码
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import cv2
# leaky_relu激活函数
def leaky_relu(x, alpha=0.1):
return tf.maximum(alpha * x, x)
class Yolo(object):
def __init__(self, weights_file, input_image, verbose=True):
# 后面程序打印描述功能的标志位
self.verbose = verbose
# 检测超参数
self.S = 7 # cell数量
self.B = 2 # 每个网格的边界框数
self.classes = ["aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant",
"sheep", "sofa", "train", "tvmonitor"]
self.C = len(self.classes) # 类别数
self.x_offset = np.transpose(np.reshape(np.array([np.arange(self.S)] * self.S * self.B),
[self.B, self.S, self.S]), [1, 2, 0])
self.y_offset = np.transpose(self.x_offset, [1, 0, 2]) # 改变数组的shape
self.threshold = 0.2 # 类别置信度分数阈值
self.iou_threshold = 0.4 # IOU阈值,小于0.4的会过滤掉
self.max_output_size = 10 # NMS选择的边界框的最大数量
self.sess = tf.Session()
self._build_net() # 【1】搭建网络模型(预测):模型的主体网络部分,这个网络将输出[batch,7*7*30]的张量
self._build_detector() # 【2】解析网络的预测结果:先判断预测框类别,再NMS
self._load_weights(weights_file) # 【3】导入权重文件
self.detect_from_file(image_file=input_image) # 【4】从预测输入图片,并可视化检测边界框、将obj的分类结果和坐标保存成txt。
# 【1】搭建网络模型(预测):模型的主体网络部分,这个网络将输出[batch,7*7*30]的张量
def _build_net(self):
# 打印状态信息
if self.verbose:
print("Start to build the network ...")
# 输入、输出用占位符,因为尺寸一般不会改变
self.images = tf.placeholder(tf.float32, [None, 448, 448, 3]) # None表示不确定,为了自适应batchsize
# 搭建网络模型
net = self._conv_layer(self.images, 1, 64, 7, 2)
net = self._maxpool_layer(net, 1, 2, 2)
net = self._conv_layer(net, 2, 192, 3, 1)
net = self._maxpool_layer(net, 2, 2, 2)
net = self._conv_layer(net, 3, 128, 1, 1)
net = self._conv_layer(net, 4, 256, 3, 1)
net = self._conv_layer(net, 5, 256, 1, 1)
net = self._conv_layer(net, 6, 512, 3, 1)
net = self._maxpool_layer(net, 6, 2, 2)
net = self._conv_layer(net, 7, 256, 1, 1)
net = self._conv_layer(net, 8, 512, 3, 1)
net = self._conv_layer(net, 9, 256, 1, 1)
net = self._conv_layer(net, 10, 512, 3, 1)
net = self._conv_layer(net, 11, 256, 1, 1)
net = self._conv_layer(net, 12, 512, 3, 1)
net = self._conv_layer(net, 13, 256, 1, 1)
net = self._conv_layer(net, 14, 512, 3, 1)
net = self._conv_layer(net, 15, 512, 1, 1)
net = self._conv_layer(net, 16, 1024, 3, 1)
net = self._maxpool_layer(net, 16, 2, 2)
net = self._conv_layer(net, 17, 512, 1, 1)
net = self._conv_layer(net, 18, 1024, 3, 1)
net = self._conv_layer(net, 19, 512, 1, 1)
net = self._conv_layer(net, 20, 1024, 3, 1)
net = self._conv_layer(net, 21, 1024, 3, 1)
net = self._conv_layer(net, 22, 1024, 3, 2)
net = self._conv_layer(net, 23, 1024, 3, 1)
net = self._conv_layer(net, 24, 1024, 3, 1)
net = self._flatten(net)
net = self._fc_layer(net, 25, 512, activation=leaky_relu)
net = self._fc_layer(net, 26, 4096, activation=leaky_relu)
net = self._fc_layer(net, 27, self.S * self.S * (self.B * 5 + self.C))
# 网络输出,[batch,7*7*30]的张量
self.predicts = net
# 【2】解析网络的预测结果:先判断预测框类别,再NMS
def _build_detector(self):
# 原始图片的宽和高
self.width = tf.placeholder(tf.float32, name='img_w')
self.height = tf.placeholder(tf.float32, name='img_h')
# 网络回归[batch,7*7*30]:
idx1 = self.S * self.S * self.C
idx2 = idx1 + self.S * self.S * self.B
# 1.类别概率[:,:7*7*20] 20维
class_probs = tf.reshape(self.predicts[0, :idx1], [self.S, self.S, self.C])
# 2.置信度[:,7*7*20:7*7*(20+2)] 2维
confs = tf.reshape(self.predicts[0, idx1:idx2], [self.S, self.S, self.B])
# 3.边界框[:,7*7*(20+2):] 8维 -> (x,y,w,h)
boxes = tf.reshape(self.predicts[0, idx2:], [self.S, self.S, self.B, 4])
# 将x,y转换为相对于图像左上角的坐标
# w,h的预测是平方根乘以图像的宽度和高度
boxes = tf.stack([(boxes[:, :, :, 0] + tf.constant(self.x_offset, dtype=tf.float32)) / self.S * self.width,
(boxes[:, :, :, 1] + tf.constant(self.y_offset, dtype=tf.float32)) / self.S * self.height,
tf.square(boxes[:, :, :, 2]) * self.width,
tf.square(boxes[:, :, :, 3]) * self.height], axis=3)
# 类别置信度分数:[S,S,B,1]*[S,S,1,C]=[S,S,B,类别置信度C]
scores = tf.expand_dims(confs, -1) * tf.expand_dims(class_probs, 2)
scores = tf.reshape(scores, [-1, self.C]) # [S*S*B, C]
boxes = tf.reshape(boxes, [-1, 4]) # [S*S*B, 4]
# 只选择类别置信度最大的值作为box的类别、分数
box_classes = tf.argmax(scores, axis=1) # 边界框box的类别
box_class_scores = tf.reduce_max(scores, axis=1) # 边界框box的分数
# 利用类别置信度阈值self.threshold,过滤掉类别置信度低的
filter_mask = box_class_scores >= self.threshold
scores = tf.boolean_mask(box_class_scores, filter_mask)
boxes = tf.boolean_mask(boxes, filter_mask)
box_classes = tf.boolean_mask(box_classes, filter_mask)
# NMS (不区分不同的类别)
# 中心坐标+宽高box (x, y, w, h) -> xmin=x-w/2 -> 左上+右下box (xmin, ymin, xmax, ymax),因为NMS函数是这种计算方式
_boxes = tf.stack([boxes[:, 0] - 0.5 * boxes[:, 2], boxes[:, 1] - 0.5 * boxes[:, 3],
boxes[:, 0] + 0.5 * boxes[:, 2], boxes[:, 1] + 0.5 * boxes[:, 3]], axis=1)
nms_indices = tf.image.non_max_suppression(_boxes, scores,
self.max_output_size, self.iou_threshold)
self.scores = tf.gather(scores, nms_indices)
self.boxes = tf.gather(boxes, nms_indices)
self.box_classes = tf.gather(box_classes, nms_indices)
# 【3】导入权重文件
def _load_weights(self, weights_file):
# 打印状态信息
if self.verbose:
print("Start to load weights from file:%s" % (weights_file))
# 导入权重
saver = tf.train.Saver() # 初始化
saver.restore(self.sess, weights_file) # saver.restore导入/saver.save保存
# 【4】从预测输入图片,并可视化检测边界框、将obj的分类结果和坐标保存成txt。
# image_file是输入图片文件路径;
# deteted_boxes_file="boxes.txt"是最后坐标txt;detected_image_file="detected_image.jpg"是检测结果可视化图片
def detect_from_file(self, image_file, imshow=True, deteted_boxes_file="boxes.txt",
detected_image_file="detected_image.jpg"):
# read image
image = cv2.imread(image_file)
img_h, img_w, _ = image.shape
scores, boxes, box_classes = self._detect_from_image(image)
predict_boxes = []
for i in range(len(scores)):
# 预测框数据为:[概率,x,y,w,h,类别置信度]
predict_boxes.append((self.classes[box_classes[i]], boxes[i, 0],
boxes[i, 1], boxes[i, 2], boxes[i, 3], scores[i]))
self.show_results(image, predict_boxes, imshow, deteted_boxes_file, detected_image_file)
################# 对应【1】:定义conv/maxpool/flatten/fc层#############################################################
# 卷积层:x输入;id:层数索引;num_filters:卷积核个数;filter_size:卷积核尺寸;stride:步长
def _conv_layer(self, x, id, num_filters, filter_size, stride):
# 通道数
in_channels = x.get_shape().as_list()[-1]
# 均值为0标准差为0.1的正态分布,初始化权重w;shape=行*列*通道数*卷积核个数
weight = tf.Variable(
tf.truncated_normal([filter_size, filter_size, in_channels, num_filters], mean=0.0, stddev=0.1))
bias = tf.Variable(tf.zeros([num_filters, ])) # 列向量
# padding, 注意: 不用padding="SAME",否则可能会导致坐标计算错误
pad_size = filter_size // 2 # 除法运算,保留商的整数部分
pad_mat = np.array([[0, 0], [pad_size, pad_size], [pad_size, pad_size], [0, 0]])
x_pad = tf.pad(x, pad_mat)
conv = tf.nn.conv2d(x_pad, weight, strides=[1, stride, stride, 1], padding="VALID")
output = leaky_relu(tf.nn.bias_add(conv, bias))
# 打印该层信息
if self.verbose:
print('Layer%d:type=conv,num_filter=%d,filter_size=%d,stride=%d,output_shape=%s'
% (id, num_filters, filter_size, stride, str(output.get_shape())))
return output
# 池化层:x输入;id:层数索引;pool_size:池化尺寸;stride:步长
def _maxpool_layer(self, x, id, pool_size, stride):
output = tf.layers.max_pooling2d(inputs=x,
pool_size=pool_size,
strides=stride,
padding='SAME')
if self.verbose:
print('Layer%d:type=MaxPool,pool_size=%d,stride=%d,out_shape=%s'
% (id, pool_size, stride, str(output.get_shape())))
return output
# 扁平层:因为接下来会连接全连接层,例如[n_samples, 7, 7, 32] -> [n_samples, 7*7*32]
def _flatten(self, x):
tran_x = tf.transpose(x, [0, 3, 1, 2]) # [batch,行,列,通道数channels] -> [batch,通道数channels,列,行]
nums = np.product(x.get_shape().as_list()[1:]) # 计算的是总共的神经元数量,第一个表示batch数量所以去掉
return tf.reshape(tran_x, [-1, nums]) # [batch,通道数channels,列,行] -> [batch,通道数channels*列*行],-1代表自适应batch数量
# 全连接层:x输入;id:层数索引;num_out:输出尺寸;activation:激活函数
def _fc_layer(self, x, id, num_out, activation=None):
num_in = x.get_shape().as_list()[-1] # 通道数/维度
# 均值为0标准差为0.1的正态分布,初始化权重w;shape=行*列*通道数*卷积核个数
weight = tf.Variable(tf.truncated_normal(shape=[num_in, num_out], mean=0.0, stddev=0.1))
bias = tf.Variable(tf.zeros(shape=[num_out, ])) # 列向量
output = tf.nn.xw_plus_b(x, weight, bias)
# 正常全连接层是leak_relu激活函数;但是最后一层是liner函数
if activation:
output = activation(output)
# 打印该层信息
if self.verbose:
print('Layer%d:type=Fc,num_out=%d,output_shape=%s'
% (id, num_out, str(output.get_shape())))
return output
######################## 对应【4】:可视化检测边界框、将obj的分类结果和坐标保存成txt#########################################
def _detect_from_image(self, image):
"""Do detection given a cv image"""
img_h, img_w, _ = image.shape
img_resized = cv2.resize(image, (448, 448))
img_RGB = cv2.cvtColor(img_resized, cv2.COLOR_BGR2RGB)
img_resized_np = np.asarray(img_RGB)
_images = np.zeros((1, 448, 448, 3), dtype=np.float32)
_images[0] = (img_resized_np / 255.0) * 2.0 - 1.0
scores, boxes, box_classes = self.sess.run([self.scores, self.boxes, self.box_classes],
feed_dict={self.images: _images, self.width: img_w,
self.height: img_h})
return scores, boxes, box_classes
def show_results(self, image, results, imshow=True, deteted_boxes_file=None,
detected_image_file=None):
"""Show the detection boxes"""
img_cp = image.copy()
if deteted_boxes_file:
f = open(deteted_boxes_file, "w")
# draw boxes
for i in range(len(results)):
x = int(results[i][1])
y = int(results[i][2])
w = int(results[i][3]) // 2
h = int(results[i][4]) // 2
if self.verbose:
print("class: %s, [x, y, w, h]=[%d, %d, %d, %d], confidence=%f"
% (results[i][0], x, y, w, h, results[i][-1]))
# 中心坐标 + 宽高box(x, y, w, h) -> xmin = x - w / 2 -> 左上 + 右下box(xmin, ymin, xmax, ymax)
cv2.rectangle(img_cp, (x - w, y - h), (x + w, y + h), (0, 255, 0), 2)
# 在边界框上显示类别、分数(类别置信度)
cv2.rectangle(img_cp, (x - w, y - h - 20), (x + w, y - h), (125, 125, 125), -1) # puttext函数的背景
cv2.putText(img_cp, results[i][0] + ' : %.2f' % results[i][5], (x - w + 5, y - h - 7),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1)
if deteted_boxes_file:
# 保存obj检测结果为txt文件
f.write(results[i][0] + ',' + str(x) + ',' + str(y) + ',' +
str(w) + ',' + str(h) + ',' + str(results[i][5]) + '\n')
if imshow:
cv2.imshow('YOLO_small detection', img_cp)
cv2.waitKey(1)
if detected_image_file:
cv2.imwrite(detected_image_file, img_cp)
if deteted_boxes_file:
f.close()
if __name__ == '__main__':
yolo_net = Yolo(weights_file='D:/Python/YOLOv1-Tensorflow-master/YOLO_small.ckpt',
input_image='D:/Python/YOLOv1-Tensorflow-master/car.jpg')
附上参考的blog:
https://blog.csdn.net/u014380165/article/details/72616238
https://blog.csdn.net/shenxiaolu1984/article/details/78826995