1 前言
无论我们多么关心程序性能,在开始担心优化效果之前,我们首先需要能够工作的代码。编写清晰、直观的深度学习代码非常具有挑战性,任何实践者必须处理的第一件事就是语言语法本身。在众多的深度学习库中,每种库都有自己的编程风格。
在本文中,我们将重点讨论两个最重要的高级设计决策:
- 数学计算是采用符号范式还是命令式范式;
- 是构建更大(更抽象)的网络,还是构建更多原子操作的网络。
自始至终,我们将重点关注编程模型本身。当编程风格决定可能影响性能时,我们会指出这一点,但是我们不会详细讨论具体的实现细节。
2 符号式编程 VS. 命令式编程
如果您是Python或c++程序员,那么您已经熟悉命令式程序。命令式程序在运行时执行计算。您用Python编写的大多数代码都是必须的,下面的NumPy代码片段也是如此。
import numpy as np
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
d = c + 1
当程序执行c = b * a时,它进行了实际的数值计算。
符号程序有所不同。使用符号样式的程序,我们首先抽象地定义一个(可能很复杂的)函数。在定义函数时,不需要进行实际的数值计算。我们根据占位符定义抽象函数,然后我们可以编译这个函数,并在给定的实际输入时对其进行求值。在下面的例子中,我们将上面的命令式程序重写为一个符号样式的程序:
A = Variable('A')
B = Variable('B')
C = B * A
D = C + Constant(1)
# compiles the function
f = compile(D)
d = f(A=np.ones(10), B=np.ones(10)*2)
如您所见,在符号版本中,当C = B * A执行时,不会进行实际的计算。相反,该操作生成一个表示计算的计算图(也称为符号图)。下图是计算D的计算图。
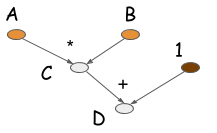
大多数符号风格的程序包含显式或隐式的编译步骤。编译过程将计算图转换为我们稍后可以调用的函数。在上面的例子中,数值计算只发生在代码的最后一行。符号式编程的特征是在构建计算图和执行计算图之间有明显的分离。对于神经网络而言,我们通常将整个模型定义为单个计算图。
在其他流行的深度学习库中,Torch、Chainer和Minerva采用命令式风格。符号式深度学习库的例子包括Theano、CGT和TensorFlow。我们还可以将依赖于配置文件的库,如CXXNet和Caffe,看作是符号风格的库,在这些库中,我们将配置文件的内容视为定义计算图。
现在您已经了解了这两种编程模型之间的区别,接下来让我们比较下两种编程模型的优点。
2.1 命令式程序往往更灵活
当您使用来自Python的命令式库时,您使用的是Python。几乎所有用Python编写的直观的东西,都可以通过在适当的地方调用必要的深度学习库来加速。另一方面,当您编写符号程序时,您可能无法访问所有熟悉的Python结构,比如迭代。考虑以下命令式程序,并考虑如何将其转换为符号程序。
a = 2
b = a + 1
d = np.zeros(10)
for i in range(d):
d += np.zeros(10)
如果符号API不支持Python for循环,那么这个改写过程就不那么容易了。当您用Python编写符号程序时,您不是用Python编写的。相反,您使用的是由符号API定义的领域特定语言(DSL)。在深度学习库中发现的符号API是功能强大的DSL,可以为神经网络生成可调用的计算图。
直觉上,您可能会说命令式程序比符号程序更直观,可以更容易地使用语言本身的特性。例如,很容易在计算过程中打印出值,或者在计算流中的任何一点使用控制流和循环。
2.2 符号式程序往往更高效
正如我们所看到的,命令式程序往往是灵活的,非常适合于宿主语言的编程流程。所以你可能会想,为什么那么多的深度学习库都采用符号式编程呢?主要原因是效率,包括内存占用和处理速度。让我们回顾一下前面的示例。
import numpy as np
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
d = c + 1
假设数组中的每个单元格占用8字节内存。在Python控制台中执行这个程序需要多少内存?
在命令式编程中,我们需要在每一行分配内存。这样我们就分配了4个大小为10的数组。所以我们需要4 * 10 * 8 = 320字节。但是,如果我们构建一个计算图,并且事先知道我们只需要d,我们就可以重用最初分配给中间值的内存。例如,通过就地执行计算,我们可以回收分配给b的空间用于存储c,也可以回收分配给c的空间存储d。最终,我们可以将内存需求减半,只需要2 * 10 * 8 = 160字节。
符号式程序受到更多的限制。当我们在D上调用compile时,我们告诉系统只需要D的值。计算的中间值,也就是这里的c,对我们来说是不可见的。
我们可以从中受益,因为符号程序可以安全地重用内存进行就地计算。但如果我们后来决定需要访问c,那么就非常不方便了。因此,命令式程序能够更好地满足所有可能的需求。如果我们在Python控制台中运行代码的命令式版本,将来就可以检查任何中间变量。
符号程序还可以执行另一种优化,称为操作折叠。如下图所示,在上面的示例中,乘法和加法操作可以折叠成一个操作。
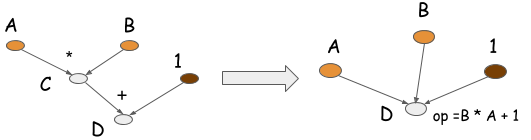 如果计算在GPU处理器上运行,操作折叠之后将使用一个GPU内核,而不是两个。实际上,这是我们在优化的库(如CXXNet和Caffe)中手工操作的一种方法。操作折叠提高了计算效率。
如果计算在GPU处理器上运行,操作折叠之后将使用一个GPU内核,而不是两个。实际上,这是我们在优化的库(如CXXNet和Caffe)中手工操作的一种方法。操作折叠提高了计算效率。
注意,您不能在命令式程序中执行操作折叠,因为中间值可能在将来被引用。在符号式程序中,操作折叠是可能的,因为您可以得到整个计算图形,以及需要哪些值和不需要哪些值的明确说明。
2.3 案例分析:Backprop和AutoDiff
在这一节中,我们将比较关于自动微分或反向传播问题的两种编程模型。微分在深度学习中至关重要,因为它是我们训练模型的机制。在任何深度学习模型中,我们都定义了一个损失函数。损失函数度量模型与期望输出之间的距离。然后我们通常会反向传播到训练示例(输入和实际输出对)。在每个步骤中,我们更新模型的参数以最小化损失。为了确定更新参数的方向,我们需要将损失函数对参数求导。
在过去,每当有人定义一个新模型时,他们必须手工计算出导数。虽然数学计算相当简单,但对于复杂的模型来说,这可能是一项费时而乏味的工作。所有现代的深度学习库通过自动解决梯度计算问题,使从业者/研究人员的工作更容易。
命令式程序和符号式程序都可以执行梯度计算。我们来看看如何对每个函数进行自动微分。
让我们从命令式程序开始。下面的示例Python代码使用我们的示例执行自动微分:
class array(object) :
"""Simple Array object that support autodiff."""
def __init__(self, value, name=None):
self.value = value
if name:
self.grad = lambda g : {name : g}
def __add__(self, other):
assert isinstance(other, int)
ret = array(self.value + other)
ret.grad = lambda g : self.grad(g)
return ret
def __mul__(self, other):
assert isinstance(other, array)
ret = array(self.value * other.value)
def grad(g):
x = self.grad(g * other.value)
x.update(other.grad(g * self.value))
return x
ret.grad = grad
return ret
# some examples
a = array(1, 'a')
b = array(2, 'b')
c = b * a
d = c + 1
print d.value
print d.grad(1)
# Results
# 3
# {'a': 2, 'b': 1}
在这段代码中,每个数组对象都包含一个grad函数(它实际上是一个闭包)。当你运行d.grad,它递归调用其输入的梯度函数,支持梯度值返回,并返回每个输入的梯度值。
这看起来可能有点复杂,所以让我们考虑符号程序的梯度计算。下面的程序对相同的任务执行符号梯度计算。
A = Variable('A')
B = Variable('B')
C = B * A
D = C + Constant(1)
# get gradient node.
gA, gB = D.grad(wrt=[A, B])
# compiles the gradient function.
f = compile([gA, gB])
grad_a, grad_b = f(A=np.ones(10), B=np.ones(10)*2)
D的grad函数生成一个向后计算图,返回梯度节点gA、gB,对应下图中的红色节点:

命令式程序实际上做了与符号式程序相同的事情。它隐式地在grad闭包中保存一个向后计算图。当您调用d.grad,你从d(D)开始,通过图形回溯来计算梯度,并收集结果。
符号式编程和命令式编程中的梯度计算遵循相同的模式。那有什么区别呢?回想一下,要准备好面对命令式程序中所有可能的需求。如果您正在创建一个支持自动微分的数组库,则必须在计算的同时保持grad闭包。这意味着没有一个历史变量可以被垃圾收集,因为它们是由变量d通过函数闭包引用的。
如果你只想计算d的值,而不想要梯度值呢?在符号式编程中,使用f=compile ([D])声明。这也声明了计算的边界,告诉系统您只想计算前向过程。因此,系统可以释放以前结果的内存,并在输入和输出之间共享内存。
想象运行一个有n层的深层神经网络。如果您只运行前向传递,而不运行后向(梯度)传递,那么您只需要分配两个时间空间副本来存储中间层的值,而不是它们的n个副本。然而,由于命令式编程需要准备好满足获得梯度的所有可能需求,它们必须存储中间值,这需要时间空间的n个副本。
正如您所看到的,优化级别取决于您所能做的限制。符号式编程要求您在编译图时清楚地指定这些限制。另一方面,命令式编程必须为更广泛的需求做好准备。符号式编程有一个自然的优势,因为它们更了解你想做什么和不想要什么。
我们可以通过一些方法修改命令式程序,以包含类似的限制。例如,一个解决方案是引入一个上下文变量,您可以引入一个无梯度上下文变量来关闭梯度计算。
with context.NoGradient():
a = array(1, 'a')
b = array(2, 'b')
c = b * a
d = c + 1
但是,这个示例仍然必须准备好满足所有可能的需求,这意味着您不能执行就地计算来在前向过程中重用内存(这是一种通常用于减少GPU内存使用的技巧)。我们讨论的技术生成显式的向后传递。一些库(如Caffe和CXXNet)在同一个图上隐式地执行backprop。我们在本节中讨论的方法也适用于它们。
大多数基于配置文件的库,如CXXNet和Caffe,都是为满足一两个通用需求而设计的:获得每一层的激活,或者获得所有权重的梯度。这些库有相同的问题:库必须支持的泛型操作越多,基于相同数据结构的优化(内存共享)就越少。
正如您所看到的,在大多数情况下,限制和灵活性之间的权衡是相同的。
2.4 模型检查点
能够保存模型并在稍后将其加载回来是非常重要的。有不同的方法来保存您的工作。通常,要保存一个神经网络,您需要保存两件事:神经网络结构的网络配置和神经网络的权重。
对于符号式程序,检查配置的能力是一个优点。由于符号构造阶段不执行计算,因此可以直接序列化计算图,并在稍后将其加载回去。这解决了在不引入额外层的情况下保存配置的问题。
A = Variable('A')
B = Variable('B')
C = B * A
D = C + Constant(1)
D.save('mygraph')
...
D2 = load('mygraph')
f = compile([D2])
# more operations
...
因为命令式程序在描述计算时执行,所以必须将代码本身保存为配置,或者在命令式语言之上构建另一个配置层。
2.5 参数更新
大多数符号式程序是数据流(计算)图。数据流图描述计算。但是如何使用图来描述参数更新并不明显。这是因为参数更新引入了修改,这不是一个数据流概念。大多数符号式程序都引入一个特殊的update语句来更新程序中的持久状态。
使用命令式风格编写参数更新通常更容易,尤其是在需要多个相互关联的更新时。对于符号式程序,update语句也在调用它时执行。因此,在这个意义上,大多数符号式深度学习库依赖于命令式的方法来执行更新,而使用符号方法来执行梯度计算。
2.6 没有严格的限制边界
在比较这两种编程风格时,我们的一些论点可能并不完全正确,例如,可以使命令式程序更像传统的符号程序,也可以使符号程序更像传统的命令式程序。然而,这两个原型是有用的抽象,尤其是在理解深度学习库之间的差异时。我们可以合理地得出结论,编程风格之间没有明确的界限。例如,您可以在Python中创建just-in-time (JIT)编译器来编译命令式Python程序,这提供了符号程序中保存的全局信息的一些优点。
3 小操作 VS. 大操作
在设计深度学习库时,另一个重要的编程模型决策就是支持什么操作。一般来说,大多数深度学习库支持两类操作:
- 大型操作——通常用于计算神经网络层(例如全连接和批归一化)
- 小操作——数学函数,如矩阵乘法和逐元素相加
像CXXNet和Caffe这样的库支持层粒度的操作。像Theano和Minerva这样的库支持细粒度操作。
3.1 较小的操作可以更加灵活
使用较小的操作来组成较大的操作是很自然的。例如,sigmoid函数可以简单地由除法、加法和指数法组成:
sigmoid(x) = 1.0 / (1.0 + exp(-x))
使用较小的操作作为构建块,您几乎可以表达您想要的任何内容。如果您更熟悉CXXNet或caffe样式的层,请注意这些操作与层没有区别,只是它们更小。
SigmoidLayer(x) = EWiseDivisionLayer(1.0, AddScalarLayer(ExpLayer(-x), 1.0))
这个表达式由三个层组成,每个层定义它的向前和向后(梯度)函数。使用较小的操作可以快速构建新层,因为您只需要组合组件。
3.2 大操作更加高效
直接组合sigmoid层需要三层操作,而不是一层。
SigmoidLayer(x) = EWiseDivisionLayer(1.0, AddScalarLayer(ExpLayer(-x), 1.0))
这段代码占用了过多的计算和内存开销(可以进行优化)。
像CXXNet和Caffe这样的库采取了不同的方法。为了支持粗粒度的操作,例如批归一化和Sigmoid层,在每一层中,计算内核都是手工制作的,只需要启动一个或几个CUDA内核。这使得这些实现更加有效。
3.3 编译和优化
小型操作可以优化吗?当然可以。让我们看看编译引擎的系统优化部分。在计算图上可以进行两种优化:
- 内存分配优化,以重用内存的中间计算;
- 算子融合,检测子图模式,如sigmoid,并将它们融合成一个更大的操作内核。
内存分配优化并不局限于小操作图。你也可以在更大的运算图中使用它。但是,对于像CXXNet和Caffe这样的大型操作库,优化可能不是必需的,因为您无法在它们中找到编译步骤。然而,这些库中有一个(愚蠢的)编译步骤,通过逐个运行每个操作,基本上将这些层转换成一个固定的向前、向后执行计划。
对于操作较小的计算图,这些优化对性能至关重要。因为操作很小,所以可以匹配许多子图模式。此外,由于最终生成的操作可能不可枚举,因此需要显式地重新编译内核,而不是在大型操作库中使用固定数量的预编译内核。这为支持小操作的符号库创建了编译开销。需要编译优化还会为只支持较小操作的库带来工程开销。
与符号式与命令式的情况一样,较大的操作库通过要求您(对公共层)提供限制来“欺骗”,以便实际执行子图匹配。这将编译开销转移到真正的大脑,这通常不是很糟糕。
3.4 表达式模板和静态类型语言
您总是需要编写小操作并组合它们。像Caffe这样的库使用手工制作的内核来构建这些更大的块。否则,您将不得不使用Python组合较小的操作。
还有第三种选择,效果很好。这称为表达式模板。基本上,您可以使用模板编程在编译时从表达式树生成通用内核。可以参考表达式模板。CXXNet广泛使用了表达式模板,它支持创建更短、更可读的代码,以匹配手工制作的内核的性能。
使用表达式模板和Python内核生成之间的区别在于,表达式计算是在编译时对已有类型的c++进行的,因此不存在额外的运行时开销。原则上,这对于其他支持模板的静态类型语言也是可能的,但是我们已经看到这个技巧只在c++中使用。
表达式模板库在Python操作和手工制作的大内核之间创建了一个中间平台,它允许c++用户通过组合较小的操作来创建高效的大操作。这是一个值得考虑的选择。
4 多种方法结合
现在我们已经比较了编程模型,您应该选择哪一个?在深入研究之前,我们应该强调,根据您试图解决的问题,我们的比较不一定会产生很大影响。
请记住Amdahl定律:如果您正在优化问题的非性能关键部分,那么您将不会获得很大的性能收益。
正如您所看到的,通常需要在效率、灵活性和工程复杂性之间进行权衡。更适合的编程风格取决于您要解决的问题。例如,命令式程序更适合于参数更新,符号程序更适合于梯度计算。
我们主张把这两种方法结合起来。有时我们想要灵活的部分对性能并不重要。在这些情况下,可以保留一些效率来支持更灵活的接口。在机器学习中,组合方法通常比只使用一种方法效果更好。
如果您能够正确地组合这些编程模型,那么您可以获得比使用单个编程模型更好的结果。在本节中,我们将讨论如何做到这一点。
4.1 符号式编程和命令式编程
有两种方法可以混合使用符号程序和命令程序:
- 在符号程序中使用命令式程序作为回调
- 使用符号程序作为命令式程序的一部分
我们已经注意到,命令式地编写参数更新和在符号程序中执行梯度计算通常是有帮助的。
符号库已经混合了各种程序,因为Python本身是命令式的。例如,下面的程序将符号方法与命令式的NumPy混合。
A = Variable('A')
B = Variable('B')
C = B * A
D = C + Constant(1)
# compiles the function
f = compile(D)
d = f(A=np.ones(10), B=np.ones(10)*2)
d = d + 1.0
符号图被编译成一个可以强制执行的函数。内部构件对于用户来说是一个黑盒子。这就像编写c++程序并将它们暴露给Python一样,这是我们经常做的。
因为参数内存驻留在GPU上,所以您可能不希望使用NumPy作为命令式组件。支持与gpu兼容的命令式库可能是更好的选择,该命令式库与符号编译函数交互,或者在符号程序执行的update语句中提供有限数量的更新语法。
4.2 小操作和大操作
小操作和大操作合并可能是有原因的。考虑执行诸如更改损失函数或向现有结构添加几个定制层等任务的应用程序。通常,您可以使用大型操作来组合现有组件,并使用小型操作来构建新部件。
记得Amdahl法则。通常,新组件不是计算瓶颈的原因。因为性能关键部分已经由较大的操作优化过了,所以可以放弃对其他小操作的优化,或者进行有限的内存优化,而不是操作融合并直接运行它们。
4.3 选择自己的实现方法
在本文中,我们比较了开发用于深度学习的编程环境的多种方法。我们比较了每种方法的可用性和效率含义,发现其中许多权衡(例如命令式与符号式之间的权衡不一定是非黑即白)。您可以选择您的方法,或者将这些方法组合起来创建更有趣和更智能的深度学习库。
参考
文章翻译自:https://mxnet.incubator.apache.org/architecture/program_model.html#compilation-and-optimization