使用自相似性的聚类方法——Chameleon
第三十六次写博客,本人数学基础不是太好,如果有幸能得到读者指正,感激不尽,希望能借此机会向大家学习。本文作为基于图的聚类的第四部分,主要针对“使用自相似性的Chameleon聚类算法”即进行介绍。其他基于图的聚类算法的链接可以在这篇综述《基于图的聚类算法综述(基于图的聚类算法开篇)》的结尾找到。
传统相似性度量方法的缺陷
层次聚类技术通过合并两个最相似的簇来进行聚类,其中簇的相似性定义依赖于具体的算法,例如,“单链”使用不同簇中点的最小距离来表示相似性,CURE则使用两个簇中最近的代表点间距离来表示相似性。仅仅使用单一的相似度度量方法可能导致簇被错误的合并和分割,如下图所示存在4个簇,如果使用“单链”层次聚类或CURE算法会将簇a、b错误的合并在一起,而不是将簇c、d进行合并。

另一问题是,大部分聚类技术都有一个全局(静态)簇模型,例如,K-Means假定簇是球形的,而DBSCAN基于单个密度阈值定义簇,使用这种全局模型的聚类方法不能处理诸如大小、形状和密度等簇特征在簇间变化很大的情况。以“组平均”层次聚类算法为例,如下图所示存在4个簇,假设每个顶点之间边的权值相等,且每个簇的大小相等,“组平均”会将簇c、d错误的合并,而不是将簇a、b进行合并。

Chameleon是一种凝聚层次聚类技术,他将数据的初始划分(使用一种有效的图划分算法)和一种新颖的层次聚类方案相结合,可以有效的解决上述问题。这种层次聚类使用接近性和互连性概念以及簇的局部建模,因此不依赖于全局(静态)模型,关键思想是,仅当合并后的结果簇类似于原来的两个簇时,这两个簇才应当合并。
自相似性(Self-similarity)度量
Chameleon力求合并这样一对簇,合并后产生的簇,用接近性和互联性度量,与原来一对簇最相似,因为这种方法仅依赖于簇对而不依赖于全局模型,Chameleon能够处理包含具有各种不同簇特性的簇的情况,下面分别对接近性和互联性进行介绍。
(1) 相对接近度(Relative Closeness,简称RC)
相对接近度是被簇的内部接近度规范化的两个簇的绝对接近度,更具体的说,仅当结构簇中的点之间的接近程度几乎与原来的每个簇一样时,才满足两个簇合并的条件,数学表示为:
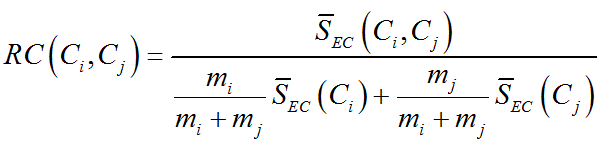
其中,
和
分别是簇
和
的大小,
绝对接近度是
-最近邻图中连接
和
的边的平均加权和,内部接近度
和
分别是将簇
和
划分为大小相等的两个集合的割边的平均加权和,如图1所示,虽然簇a、b之间的绝对接近度高于簇c、d,但是他们的相对互连度要远远小于簇c、d。
(2) 相对互连度(Relative Inter-connectivity,简称RI)
相对互连度是被簇的内部互连度规范化的两个簇的绝对互连度,仅当结果簇中的点之间的连接几乎与原来的每个簇一样强时,才满足两个簇合并的条件,数学表示为:

其中,绝对互连度
是
-最近邻图中连接
和
的边的权值之和,内部互连度
和
分别是将簇
和
划分为大小相等的两个集合的割边的最小加权和,如图2所示,虽然簇c、d之间的绝对互连度高于簇a、b,但是他们的相对互连度要远远小于簇a、b。
RI和RC可以通过不同的方式进行组合,来产生相似性(Self-similarity)的总度量,Chameleon使用的一种方法是合并最大化
的簇对,其中
是用户指定的参数,
时相对接近度更加重要,
时相对互连度更加重要。
Chameleon算法
Chameleon算法是一种基于稀疏化邻近度图的聚类算法,该算法共分为两个阶段,首先通过现有的图划分技术(例如METIS算法)对稀疏邻近度图进行划分,得到许多初始的子簇,然后使用动态框架对这些子簇进行凝聚层次聚类,这种算法的缺点显而易见,即用于进行凝聚层次聚类的子簇中的样本点必须来自于同一个自然簇,算法伪代码如下所示:

在进行稀疏邻近度图的划分时,可以采用METIS算法,该算法将当前稀疏邻近度图作为一个簇,然后二分当前最大的子图(簇),直到没有一个簇多于 个点,其中, 是由用户设置的参数,这个参数不仅要小于最小簇中的样本点个数,还要足够大以至于可以得到每个子簇的自相似性度量。需要注意的是,Chameleon并不丢弃噪声点而是将他们指派到簇中。
参考资料
【1】《数据挖掘导论》
【2】Karypis, G., E. H. Han, and V. Kumar. “Chameleon: hierarchical clustering using dynamic modeling.” Computer 32.8(2002):68-75.