一.数据库
1.创建数据库
- 创建一个数据库,默认存储路径在/user/hive/warehouse
create database if not exists db_hive
- 在该数据库下创建一张表
create table if not exists db_hive.sutdent(name string,id int);
## 2.数据库查询
- 显示数据库
show databases;
- 过滤显示查询的数据库
show databases like 'db*';
- 查看数据库详情
desc database db_hive;
- 显示数据库详细信息
desc database extended db_hive;
- 切换当前数据库
use db_hive;
## 3.修改数据库
用户可以使用 alter database 为某个数据库的 dbproperties 设置键值对属性值,来描述这个数据库的属性信息,不像表,数据库的其他元数据信息都是不可修改的,如数据库名和数据库所在目录位置,只能像这样添加属性。
alter database db_hive set dbproperties('time'='2018/12/27');
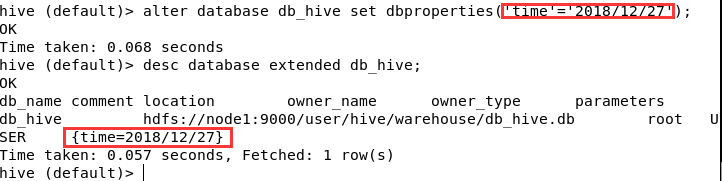
## 4.删除数据库
drop database db_hive;
但这样只能删除空数据库,我们应该再删除之前确认数据库是否为空。
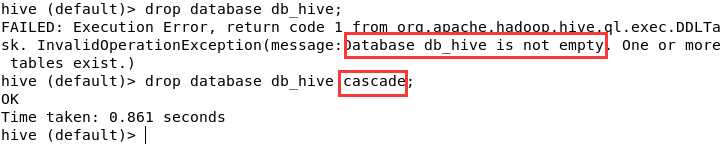
二.数据表
1.管理表
- 理论
默认创建的表都是管理表,也称为内部表,删除内部表的时候会将数据源和元数据一起删除,基于这个特性,内部表不适合用于共享 - 查询表详细信息
desc formatted hive_student;
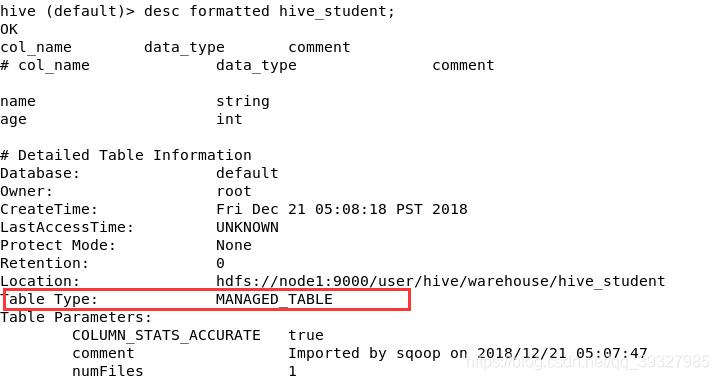
这张表是我用sqoop导入的,在上面的commet中也可以看到
2.外部表
- 理论
因为是外部表(ENTERNAL),所以Hive并不认为其完全拥有这份数据,删除该表不会删除掉这份数据,而元数据是会被删除的。 - 管理表和内部表的联合使用
将网站每天的日志数据定期流入HDFS文本文件中,在外部表(原始日志表)的基础上做大量数据分析,用到的中间表和结果表使用内部表,数据通过SELECT+INSERT进入内部表。
3.内外部表之间的互相转化
alter table hive_student set tblproperties('EXTERNAL'='TRUE');
4.分区表
分区表其实就是对应HDFS上独立的一个文件夹,该文件夹下是该分区所有数据文件。Hive中的分区就是分目录,把一个大的数据集根据需求分成许多小的数据集,查询时通过WHERE子句来选择需要的分区,这样效率会快得多。
- 创建分区表,在创建普通表的基础上加上如下即可
partitioned by(month string) ##按月区分
然而在这之后,我们并不能立马在HDFS该表目录下看到任何文件夹,直到我们往里面塞数据的时候,month文件夹才会显示出来。
- 添加数据
load data local inpath '/root/apps/hive-1.2.2/data/student.txt' into table stu_partition partition(month=20181220);
- 查询
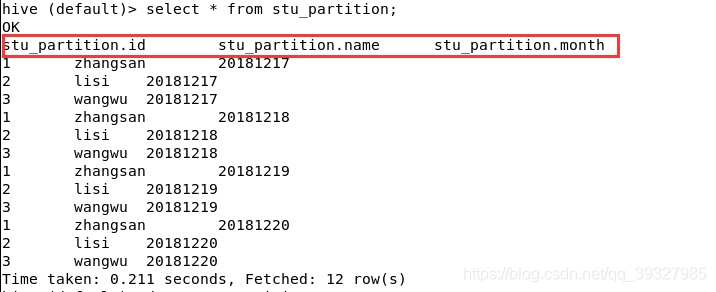
注意这里,分区规则同样作为表字段被查询出来了。
然后,我们在语句末加上条件语句WHERE将会得到我们想要的结果,再接着,使用WHERE 条件1 OR 条件2可以查的两份结果,这和SELECT * FROM TABLENAME WHERE 条件 UNION SELECT * FROM TABLENAME WHERE 条件得到的结果是一样的,区别是UNION不为我们的结果做排序,底层调用的是mapreduce,比较耗时。 - 添加分区
我们不仅可以让INSERT语句在插入数据的时候为我们创建分区,还能通过ADD添加分区,不过这个分区里暂时是没有数据的:
alter table stu_partition add partition(month=20181221) partition(month=20181222);
- 删除分区
alter table stu_partition drop partition(month=20181222);
但是让人感到费解的是,删除多个分区的语句之间居然要用逗号连接,这不是让人疲于记忆吗
注意:在添加或删除某分区下的分区时都用,并且并不属于级联删除。
5.二级分区
- 创建二级分区(这和创建一级分区表并没有多少差别)
partitioned by(month string,day int) ##按月和日区分
- 导入数据
load data local inpath '/root/apps/hive-1.2.2/data/student.txt' into table stu1 partition(month=201812,day=21);
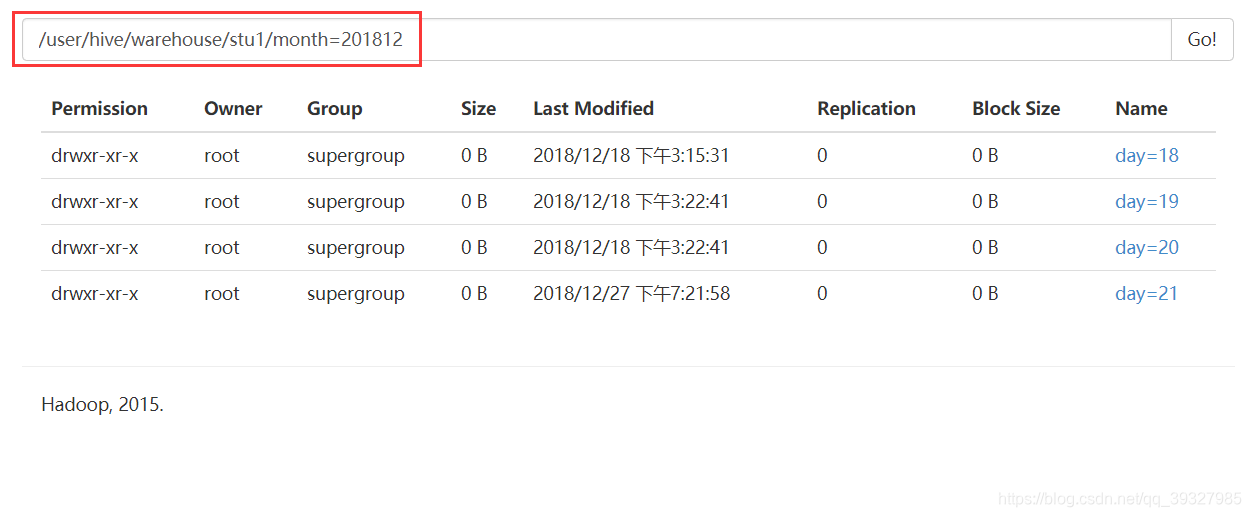
- 把数据直接上传分区目录后,让分区表和数据产生关联的三种方式
(1)上传数据后修复
dfs -mkdir -p /user/hive/warehouse/stu1/month=201812/day=22;
dfs -put /root/apps/hive-1.2.2/data/student.txt /user/hive/warehouse/stu1/month=201812/day=22;
select * from stu1 where month=201812 and day=22;
#这里是做一个比较,用于与之前创建未分区表之后再PUT数据上去做出区别

msck repair table stu1; #修复!
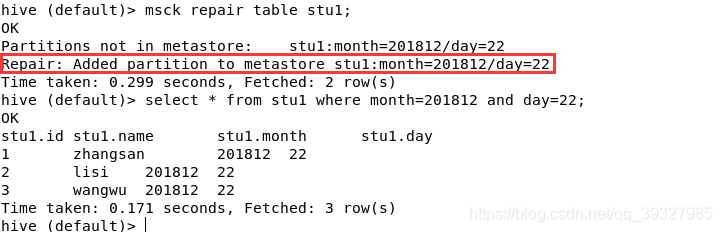
又能查到数据了呢!
注意:这种方式之所以适用于未分区表而不适用于分区表是因为它虽然会创建表的元数据信息,但是却没有创建分区的元数据信息,敲黑板,分区的元数据信息!
(2)上传数据后添加分区
dfs -mkdir -p /user/hive/warehouse/stu1/month=201812/day=23;
dfs -put /root/apps/hive-1.2.2/data/student.txt /user/hive/warehouse/stu1/month=201812/day=23;
alter table stu1 add partition(month=201812,day=23);
#手动添加分区
这样也是可行的!
(3)load这种方式会自动创建分区文件夹,不多赘述了