【论文阅读】Rethinking Spatiotemporal Feature Learning For Video Understanding
这是一篇google的论文,它和之前介绍的一篇facebook的论文的研究内容非常相似链接地址,两篇论文放到ArXiv上只相差了一个月,但是个人感觉还是google的这篇写得好一些。(这篇博客解读的是早期版本的论文,后来新的版本的论文又在Something-something数据集上做了实验,所以一些图表和本文有些出入,旧版的论文10页,新版的论文17页。。)
论文地址:下载地址
S3D-G代码(pytorch):下载地址
正文
3D卷积网络与2D卷积网络相比,始终存在着网络参数量太大而且计算效率不高的问题,但是3D卷积网络的准确率又明显好于2D卷积网络,所以为了解决这个问题,我们需要思考以下几个点:
- 3D卷积网络中是否需要全部都是3D卷积核?是否可以设计一个网络同时包含 2D卷积核和3D卷积核 来达到准确率与计算效率的 trade-off 呢?
- 是否可以通过分解3D卷积核为 2D+1D 卷积核的形式 来解决这个问题呢(虽然之前的P3D已经提出了(2D+1D)的方法,但是没有在kinetics数据集上做实验,不够完整)
- 我们如何使用上面思考的这些点来提升目前网络的性能?
对于第一个思考点,本文基于I3D来构建网络,在I3D网络中混合2D和3D卷积核,一种是Bottom-heavy-I3D-K,即前K个底层的卷积核为3D卷积核,其余为2D核,但是这种 bottom-heavy的结构可能计算效率也不是很高。另一种是 Top-heavy-I3D-K,即I3D网络的前K个顶层为3D核,其余为2D核。
对于第二个思考点,使用(2D+1D)卷积核来代替3D卷积核,这样的网络称为S3D网络,S3D网络参数少而且计算效率高,实验结果表明S3D网络的结果也要好于I3D网络。
各种网络结构
基本的I3D网络
本文的基础网络为I3D网络,之前也详细地介绍过链接地址,其基本的结构如下图所示:
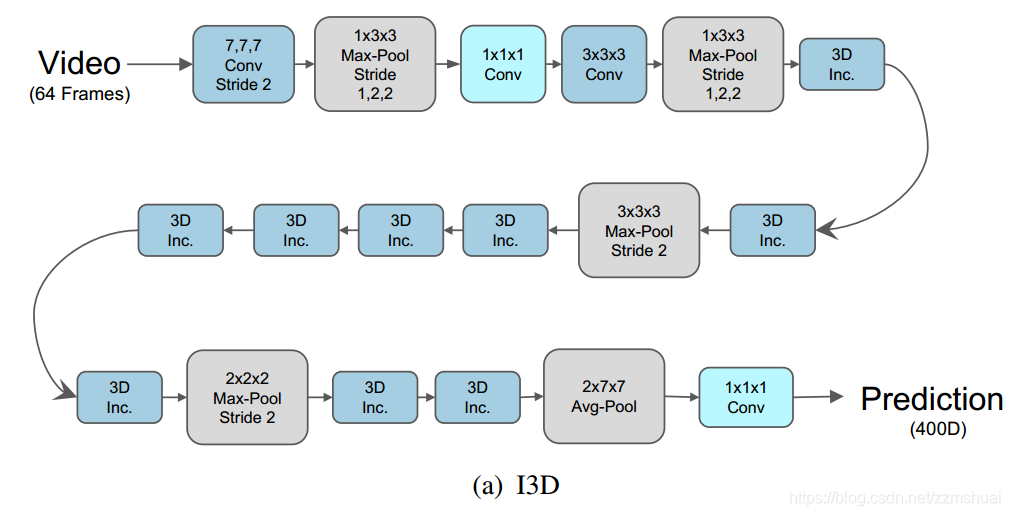
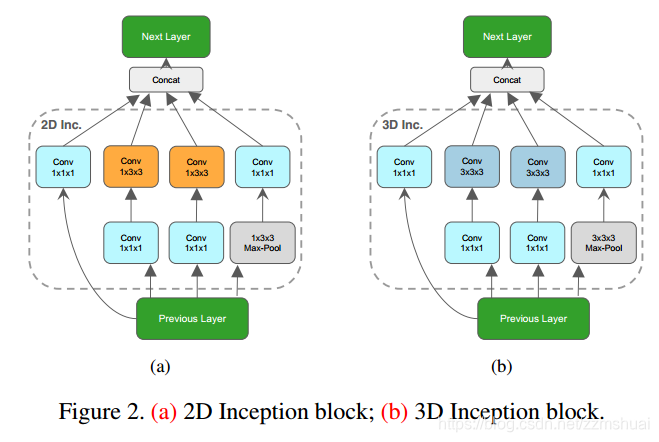
I3D是基于3D Inception block的,3D Inception block 与 2D Inception block 的对比如下图所示:
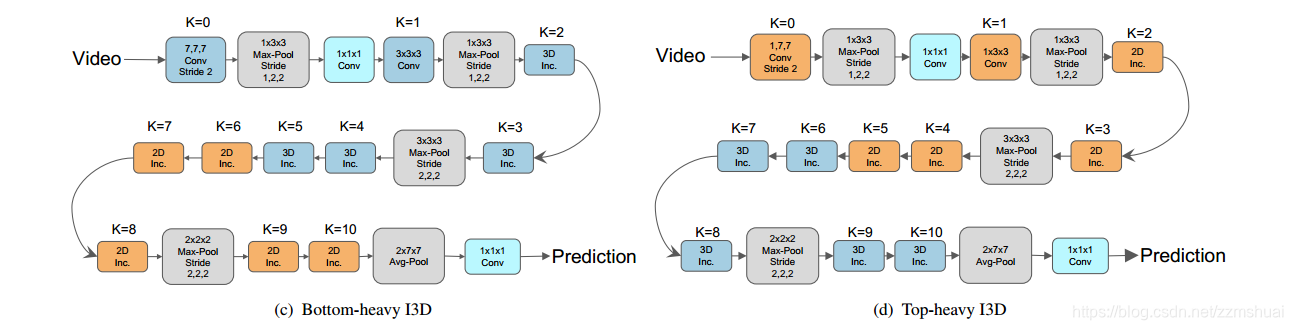
Bottom-heavy-I3D-K网络和Top-heavy-I3D-K 网络
和之前介绍facebook那篇论文一样,对于同时包含3D卷积核与2D卷积核的网络,可以分为Bottom-heavy-I3D-K网络和Top-heavy-I3D-K 网络,其中Bottom-heavy-I3D-K表示把I3D网络中的前K个底层的3D卷积核保持,而其余的卷积核为2D卷积核。Top-heavy-I3D-K网络表示保持I3D网络中前K个顶层的3D卷积核不变,其余的卷积核为2D卷积核。其中Bottom-heavy网络与Top-heavy网络的结构如下图所示:
S3D网络
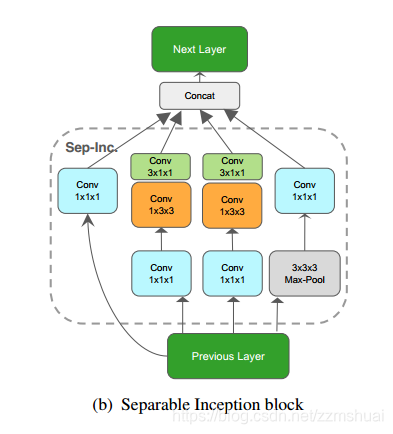
文章将因式分解3D卷积核为 2D+1D 卷积核的I3D网络称为S3D网络,其中分解的Inception block如下图所示:
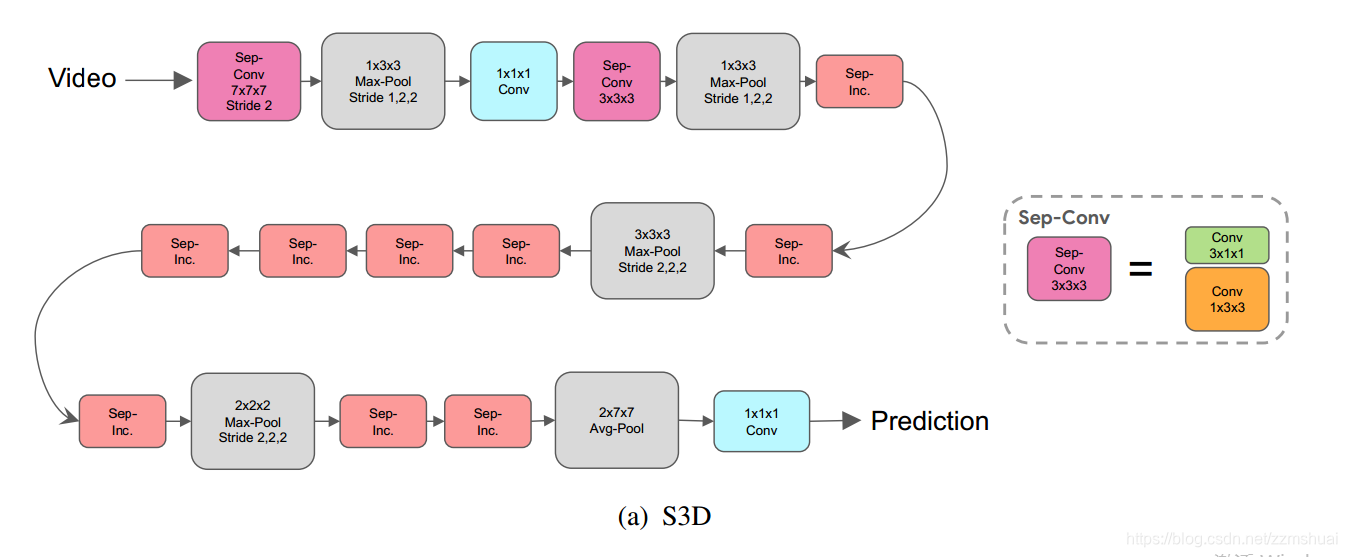
使用分解的Inception block组成的I3D网络称为S3D网络,其结构如下图所示:
S3D-G网络
最后文章参考了17年ImageNet冠军提出的S-E block方案,提出了S3D-G block,并以此搭建了S3D-G网络,文章中说得gating其实相当于一种attention map,或者说是一种加权的方式,我们使用squeeze-excitation的方式来讲解gating的过程更容易理解。如下图所示:
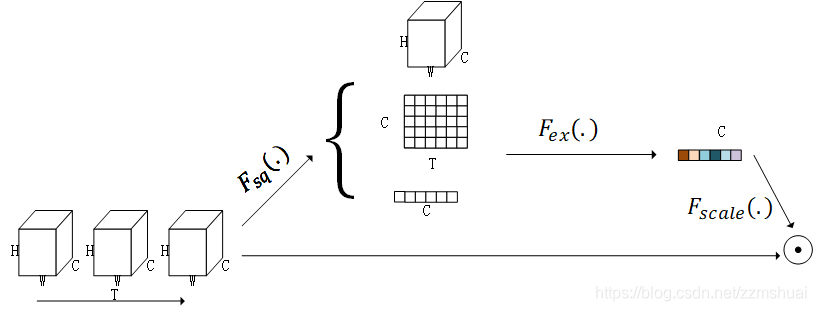
根据上图就很容易理解论文中的gating操作了,首先对于尺寸为 CxTxHxW 的 feature map 进行 squeeze操作,也就是文章中的pooling操作,文章分别使用了 空间-时间池化、空间池化、时间池化、不做池化等方法,然后对squeeze的结果进行excitation操作,使用一个变换矩阵将上一步池化的结果变换为尺寸为 C 的加权向量或者说是注意力向量。变换矩阵的尺寸和池化的结果尺寸有关。最后使用该加权向量对原特征图中的channel维度进行加权。得到最终的 S3D-G模块。
各种网络的实验结果
3D卷积网络与2D网络的比较
首先我们看一下3D卷积核到底带来了多少价值,将I3D中的3D卷积核全部替换为2D卷积核,称该网络为I2D,理论上I2D不会捕获视频的时间动态,所以其应该对视频的顺序不敏感,于是作者在正常的顺序中分别训练I3D和I2D,然后测试的时候分别测试输入为正常顺序、随机打乱的顺序和倒序的情况,实验对比结果如下:
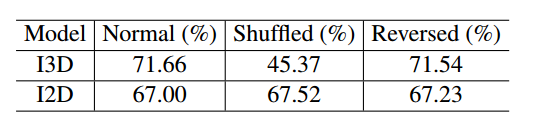
可以看到I2D完全不会捕获时间动态序列,打乱视频的帧顺序准确率也不会降低,有意思的是3DCNN 正向顺序数据训练后,测试反向顺序视频,其准确率差不多。文章认为是因为kinetics数据集并不需要因果推理。
Bottom-heavy-I3D-K网络和Top-heavy-I3D-K 网络的结果
文章实验了Bottom-heavy-I3D-K网络与Top-heavy-I3D-K的网络实验结果,如下图所示:
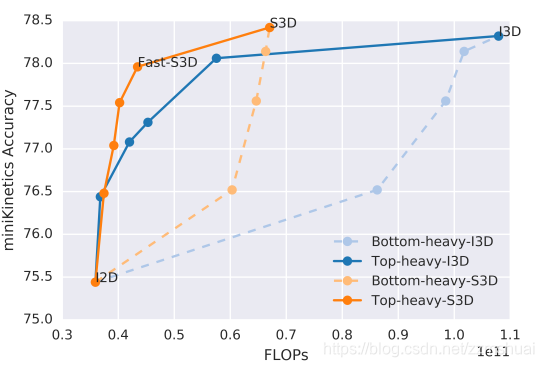
上图中蓝色的实线和蓝色的虚线分别表示Top-heavy与Bottom-heavy网络,可以看到很明显Top-heavy的性能要远远地好于Bottom-heavy,说明在视频的语义抽象层捕获视频的时间动态信息要好于在视频的像素级捕获视频的时间动态信息(与之前的facebook的论文的结论刚好相反,不知道是不是因为那一篇是Res3D,而这一篇是I3D,但是这篇论文的观点很让人信服)。为了进一步了解3D卷积网络不同层对于时间动态信息的学习,文章对从底层到顶层的卷积核进行了可视化,如下图所示:

在训练之前,同一个3D卷积核的不同时间的权值都是按照同一套方法初始化的(如图每一个小方格中的彩色块,可以看到不同时间的宽度值一样),然后训练之后的的权值使用两端封闭的线表示,可以看到在底层的卷积核中,卷积核中间时刻的权值很突出,所以其对时间不敏感,顶层的卷积核中,不同时刻的卷积核值的分布相似,所以学习到了时间动态特征。
所以在目前的3D卷积网络中,网络顶层的3D卷积核更容易学习到视频中的时间动态,我在想会不会是因为目前的视频包含大量的相机抖动,所以卷积核底层像素级的时间动态很混乱。
S3D的实验结果
文章同样实验了S3D网络的结果,如下表所示:

可以看到S3D网络无论是准确率、模型容量、还是计算效率都比原始的I3D要好。同时也可以根据之前介绍的2D+3D网络来构建Bottom-heavy-S3D-K网络和Top-heavy-S3D-K 网络,其结果如下图中的橙色线段,可以看到以S3D为基础的网络整体上优于以I3D为基础的网络,其中标记的 Fast-S3D网络是准确率与计算效率 trade-off最优的结果。
gating中最优的池化方法
之前介绍gating时讲到本文不同gating之间的区别就是池化方法的不同,文章当然也做了不同的池化方法的对比实验,实验结果如下表所示:
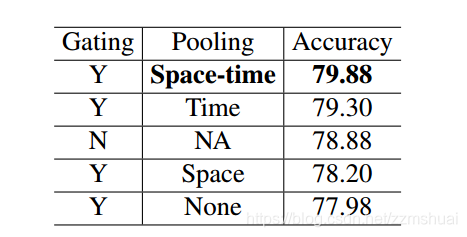
可以看到最优的池化方法还是空间和时间同时池化。
S3D-G的最终结果
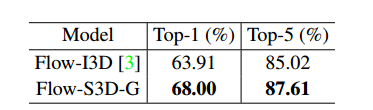
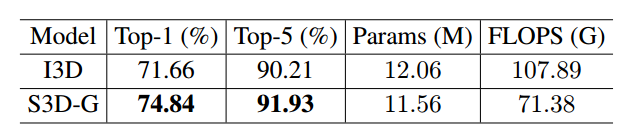
最后的S3D-G 在kinetics上与之前的I3D相比,计算效率更高,准确率更高。
RGB输入的结果如下表所示:
光流输入的结果如下表所示: