---
title: 不懂SQL优化?那你就OUT了(八)
MySQL如何优化--limit
date: 2018-12-22
****
categories: 数据库优化
---

这篇我们将讨论一下limit的优化。
如果我们只需要结果集中指定的行数,那么可以在查询中使用LIMIT子句,而不是获取整个结果集并丢弃额外的数据。
语法:
select 列名列表 from 表名 limit row_count. (参数一:返回记录行数目)
或则
select 列名列表 from 表名 limit offset(参数一:返回记录行的偏移量),row_count(参数二:返回记录行的数目)
### 单参数的情况

在一些情况中,当你使用LIMIT row_count而不使用having子句时,mysql将以不同方式处理查询。
* 如果使用limit只选择有限的几行,mysql在某些情况下会使用索引,而通常情况下它更喜欢执行全表扫描。
* 如果您将limit row_count 与order by 子句一起使用时,mysql会在找到排序结果的第一行到row_count(记录行的最大数目)后立即停止排序,而不是对整个结果进行排序。如果排序是通过使用索引完成的,这是非常快的。如果必须进行文件排序,那么将选择与查询匹配的所有行,并且在找到第一行到row_count之前对它们中的大部分或全部进行排序。在找到初始行之后,mysql不会对结果集的任何剩余行进行排序。
( 注意:当limit和order by 一起使用时,带限制和不带限制的查询顺序<font style='color:coral'>可能以不同的顺序返回行</font>。)
* 如果您将limit row_count与 distinct 一起使用,mysql一旦找到row_count个唯一的行,它将停止。
* 在某些情况下,group by 可以通过读取顺序索引(已排好序的索引)来解析,然后计算摘要,直到索引值发生变化时,在这种情况下,limit row_count 将不计算任何不必要的group by的值。
* mysql一旦向客户端发送了所需的行数,它就会中止查询,除非您使用SQL_CALC_FOUND_ROWS(和count(*) 使用类似)。在这种情况下,可以使用SELECT FOUND_ROWS()等到检索行数(得到不带limit的结果数(后面的博客会介绍))。
* limit 0 会快速返回一个空集合。这对于检查查询的有效性很有用.
* 如果服务器使用临时表来解析查询,它将使用LIMIT row_count子句来计算需要多少空间。
* 如果order by子句不能使用索引时,但是还使用limit子句,优化器可能会避免使用合并文件,并使用内存中的文件排序操作对内存中的行进行排序。
当使用order by进行排序时,当有多个行具有相同的值并按照列的顺序排序,服务器可以<font style='color:coral'>按任意顺序返回这些行</font>,并根据总体执行计划的不同,<font style='color:coral'>返回的顺序可能有所不同</font>。换句话说,相对于无序的列,这些行的排序顺序是不确定的。
影响执行计划的一个因素是limit,因此带限制和不带限制的order by查询可能返回不同顺序的行。
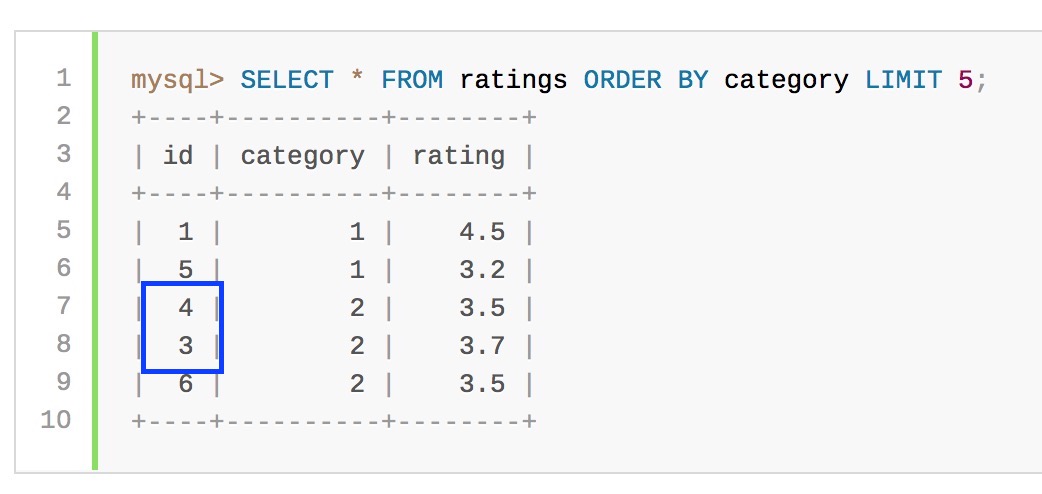
考虑这个查询,它按类别列排序,但对于id和评级列不确定:(官网的案例)

包含limit可能会影响每个类别值中的行顺序。例如,这是一个有效的查询结果:
#####如何解决单参数顺序不同的问题
在每种情况下,行都按照列的顺序排序,这就是SQL标准所要求的全部内容。
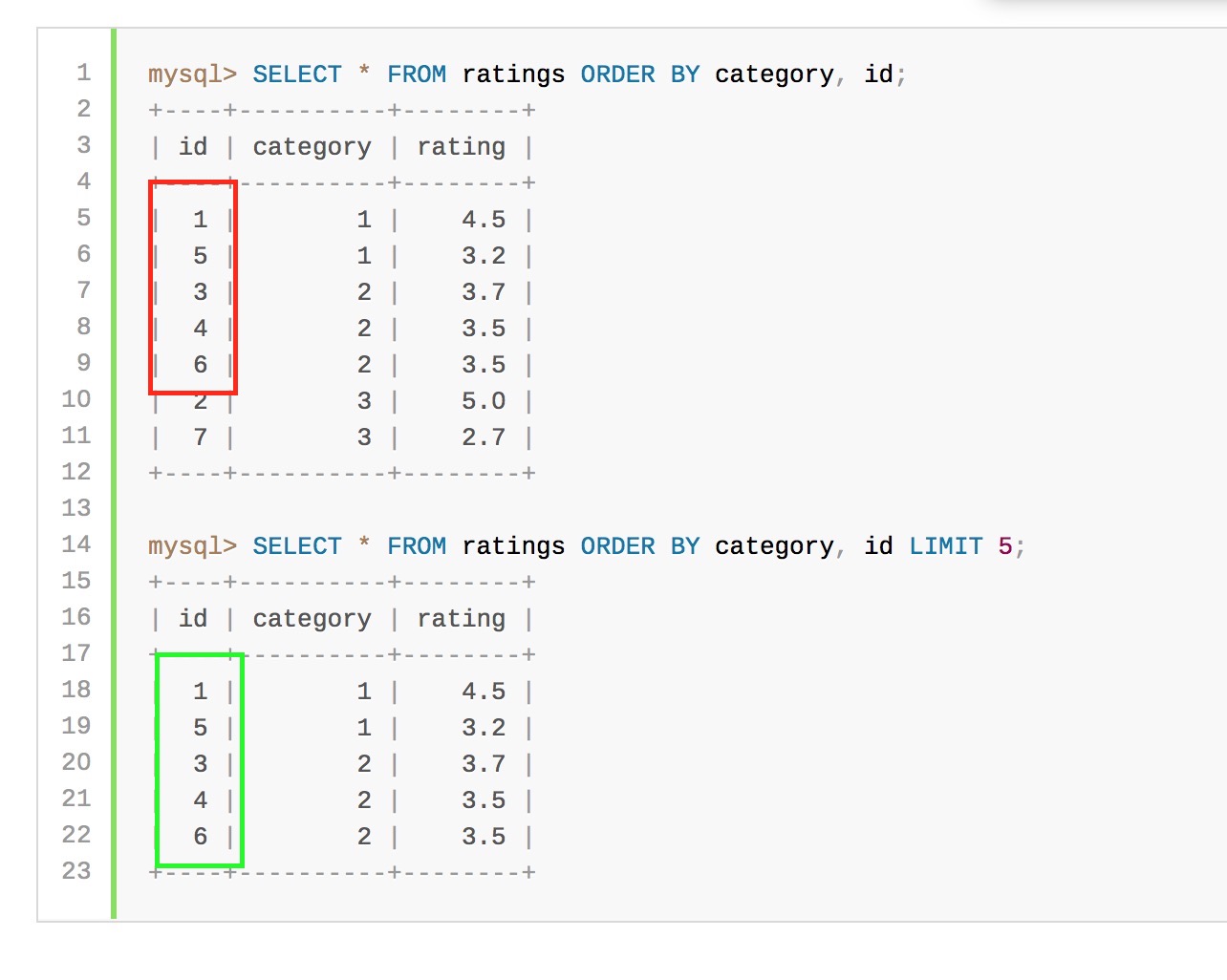
如果 确保 有和没有 限制的相同行顺序很重要,那么可以在order BY子句中包含其列,以使顺序确定。
例如,如果id值是唯一的,您可以按照id顺序排列给定类别值的行:
### 多个参数时
当使用两个参数(分页时)时存在一个弊端:虽然只需要返回rows行记录,但却必须先访问offset行(偏移值)不会用到的记录。对一张数据量很大的表进行查询时,offset(偏移值)值可能非常大,此时limit语句的效率就非常低了。
测试数据:
CREATE TABLE t_testLimit(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20) NOT NULL,
age INT NOT NULL
)
CREATE INDEX idx_name ON t_testLimit(NAME);
CREATE INDEX idx_age ON t_testLimit(age);
数据:
DELIMITER $
CREATE PROCEDURE pro_limit_datas()
BEGIN
DECLARE num INT;
DECLARE age INT;
SET num:=1;
WHILE num <= 10000000 DO
SET age:= 18+CEIL(RAND()*10);
INSERT INTO t_testLimit(NAME,age) VALUES(CONCAT('学生',num),age);
SET num:=num+1;
END WHILE;
END$
DELIMITER ;
CALL pro_limit_datas();
例如: 当查询的偏移值为 8000000 时
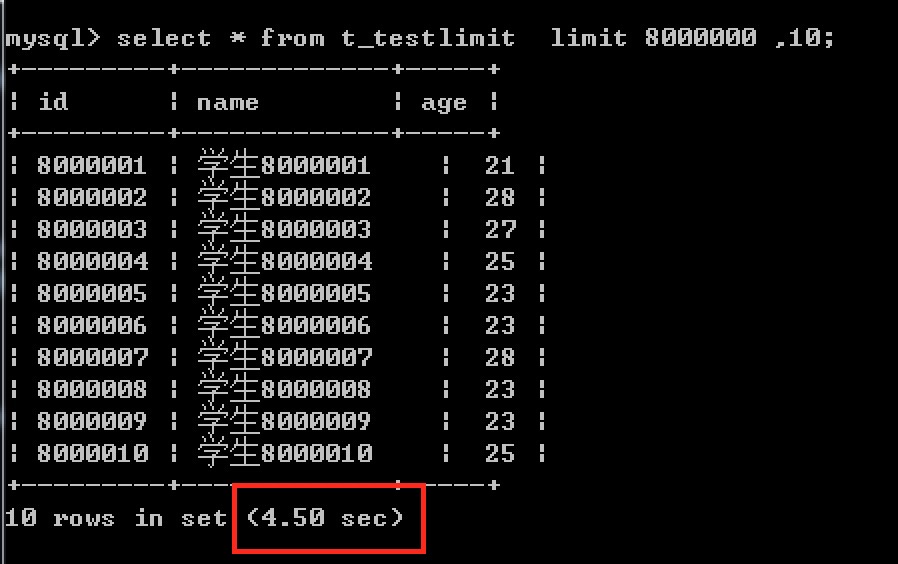
执行的时间为: 4.5 秒
优化:
可以先使用where子句把不要需要的数据过滤掉,在显示选择的行数
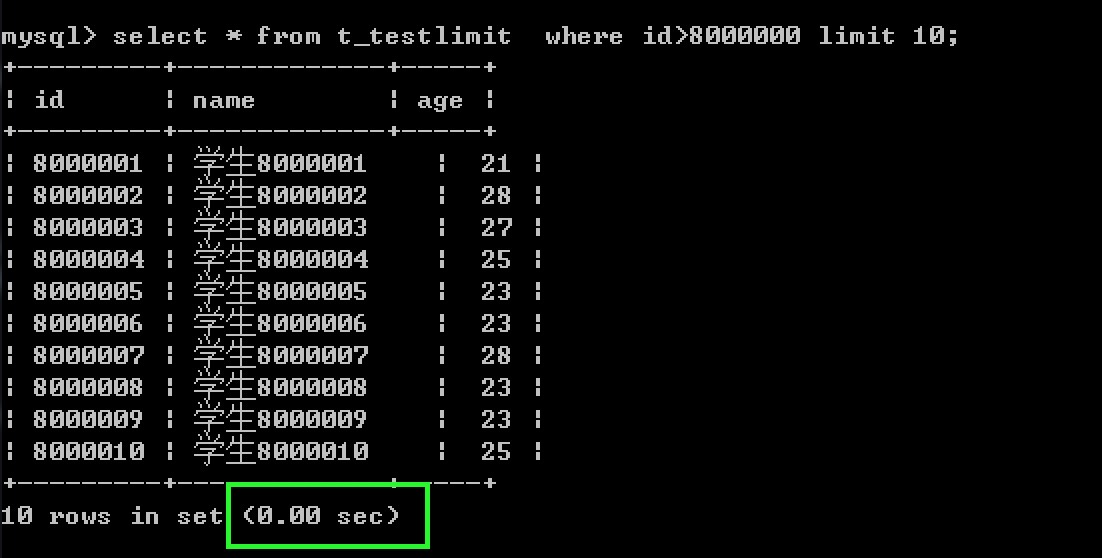
可以看到修改后的执行效率提高了很多。
执行效率高的原因为使用了主键索引。
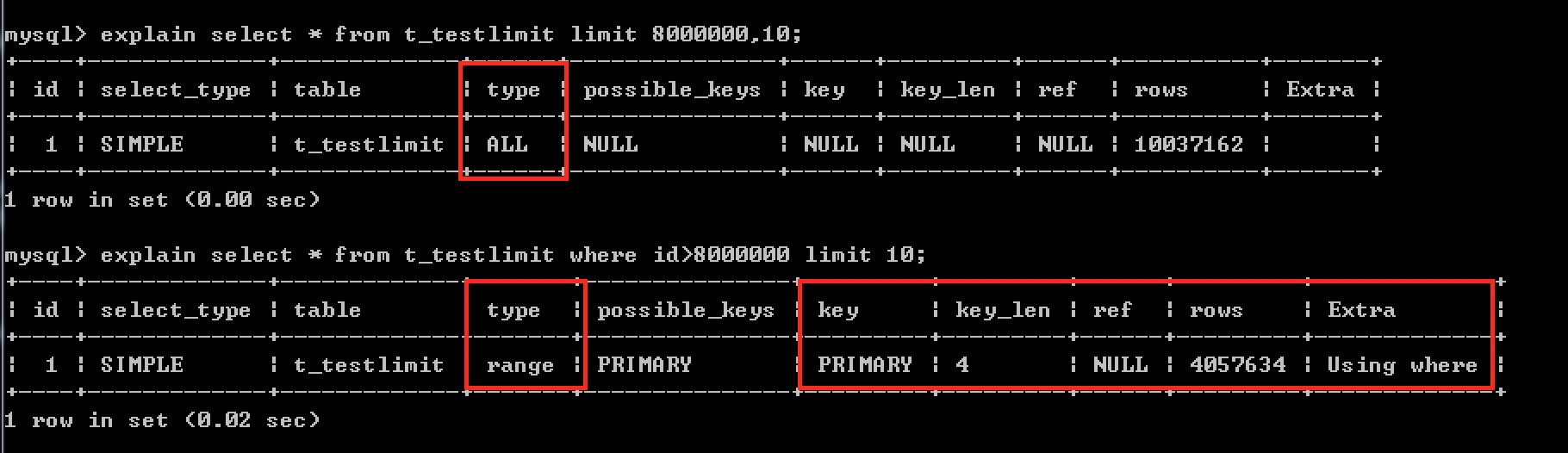
但是我们发现如果带有where条件的时候,那么id就变成了不连续的,那么这样分页数据就会不正确,这个是有缺陷的。
#####如何解决带where条件的 limit的优化:
1 可以使用子查询
例如:

可以看到使用子查询的方式大大提高了执行效率,提高了将近38倍。
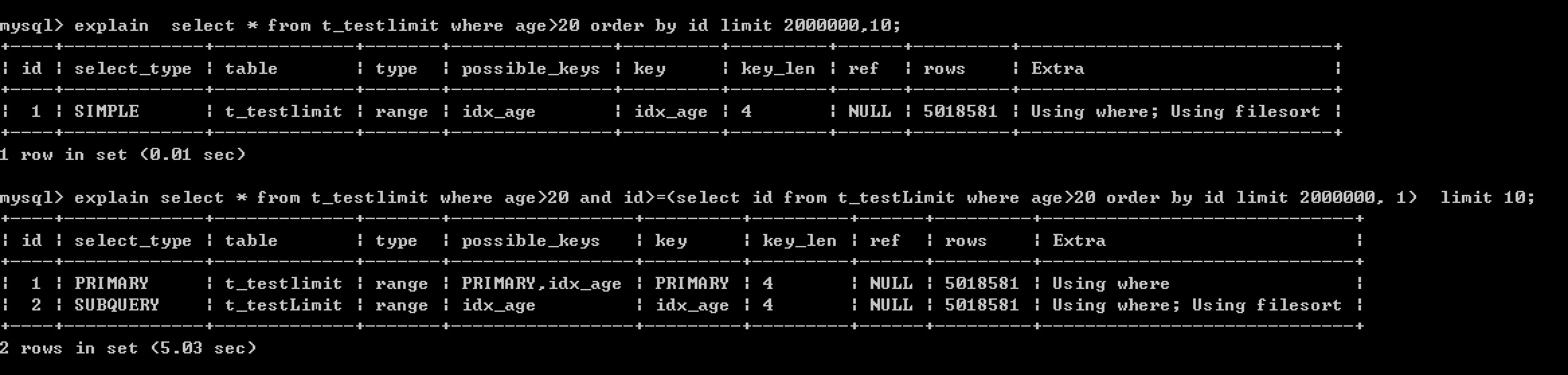
因为子查询是在索引上完成的,而普通的查询时在数据文件上完成的,通常来说,索引文件要比数据文件小得多,所以操作起来也会更有效率。
2 可以使用连表查询
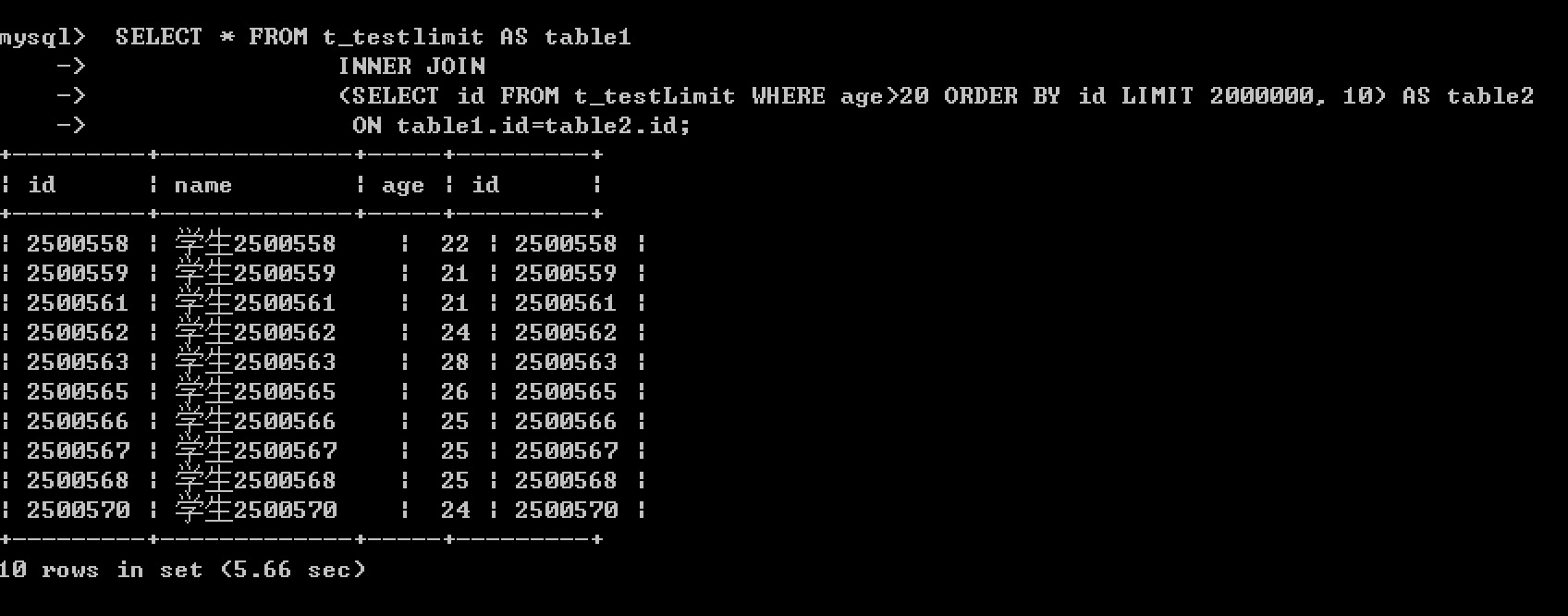
表连接和子查询分页的效率基本在一个等级上,消耗的时间也基本一致
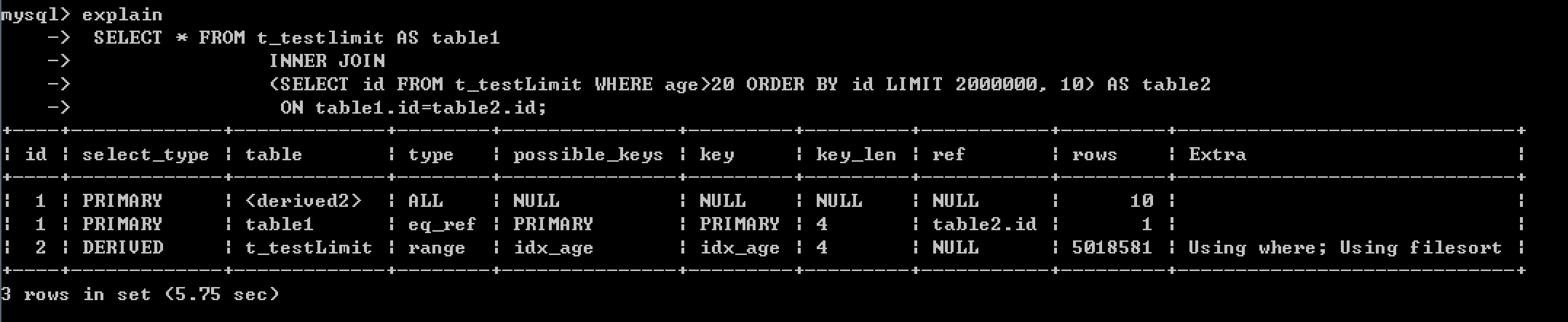
实际应用中,利用limit处理分页时,可以判断如果是一百页以内,就使用最基本的分页方式,大于一百页,则使用子查询的分页方式。
优化思想:避免数据量大时扫描过多的记录