本篇博客记录一下ForkJoinPool相关的内容,主要涉及基本的设计思想和使用方式。
一、前言
Fork/Join
ForkJoinPool继承自AbstractExecutorService,是JDK1.7引入的并行处理框架,
作为Fork/Join型线程池的实现。
ForkJoinPool的基本思想是:
将大任务分割(Fork)成多个小任务;
多个子任务可以被多个线程并发执行;
最后将子任务聚合(Join)起来作为大任务的结果。
盗图一张,ForkJoinPool执行任务的思想类似于,实际上有点分治递归的感觉:
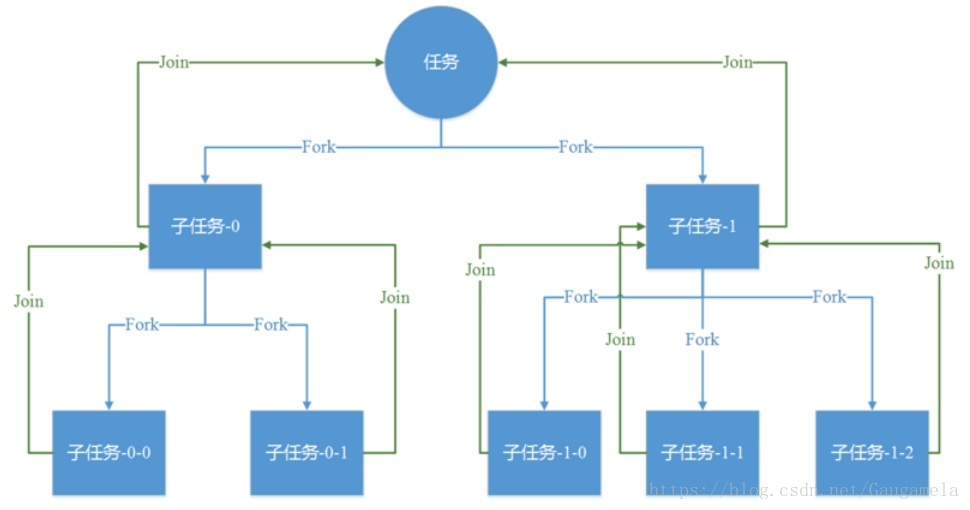
为了支持这种能力,JDK 1.7中专门定义了对应的任务类型ForkJoinTask。
不过我们一般不需要直接使用ForkJoinTask,仅需要继承它的子类RecursiveAction或RecursiveTask,
并实现对应的抽象方法compute即可。
其中,RecursiveAction是不带返回值的Fork/Join型任务,使用此类任务时并不产生结果,也就不涉及到结果的合并;
而RecursiveTask是带返回值的Fork/Join型任务,使用此类任务需要我们进行结果的合并。
Work-Stealing
相比于ThreadPoolExecutor,ForkJoinPool并发处理子任务时,引入了Work-Stealing算法。
Work-Stealing的思想是:
线程池中的每个线程,都有一个与之关联的任务队列(双端队列)。
线程每次都优先从与自己关联队列的头部取出任务来运行。
如果某个线程执行完当前任务后,发现关联的队列已空,
就会尝试从其它线程关联队列的尾部“窃取”任务来执行。
Work-Stealing算法的优点是充分利用线程进行并行计算,一定程度上减少了线程间的竞争,
适用于不同任务耗时相差比较大的场景。
与ThreadPoolExecutor对比
ForkJoinPool和ThreadPoolExecutor都是线程池,它们之间的不同点在于:
ThreadPoolExecutor只能执行Runnable和Callable任务,
而ForkJoinPool不仅可以执行Runnable和Callable 任务,
还可以执行ForkJoinTask,从而满足并行地实现分治算法的需要。
ThreadPoolExecutor中,任务的执行顺序是FIFO的,
所以后面的任务需要等待前面任务开始执行后才能被取出;
而ForkJoinPool每个线程有自己的任务队列,并在此基础上实现了Work-Stealing的功能,
使得在某些情况下,ForkJoinPool能更大程度的提高并发效率。
不过,如果ForkJoinPool需要执行的任务耗时很平均,
由于窃取任务时不同线程需要抢占锁,有可能会造成额外的时间消耗。
此外,Work-Stealing算法中,每个线程都需要维护双端队列,
这也会造成较大的内存消耗。
因此整体来讲,ForkJoinPool和ThreadPoolExecutor各有千秋,
需结合具体的业务场景来使用。
二、构造函数
接下来,我们看看ForkJoinPool的构造函数:
//无参数时,ForkJoinPool的线程数上限取决于处理器的数量
//使用的线程工厂类型为DefaultForkJoinWorkerThreadFactory
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false);
}
//可以通过参数设置线程数上限
public ForkJoinPool(int parallelism) {
this(parallelism, defaultForkJoinWorkerThreadFactory, null, false);
}
//handler为线程出现异常后的处理器
//asyncMode决定了QUEUE的类型
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode) {
this(checkParallelism(parallelism),
checkFactory(factory),
handler,
asyncMode ? FIFO_QUEUE : LIFO_QUEUE,
"ForkJoinPool-" + nextPoolId() + "-worker-");
checkPermission();
}我们跟进看看DefaultForkJoinWorkerThreadFactory的实现:
private static final class DefaultForkJoinWorkerThreadFactory
implements ForkJoinWorkerThreadFactory {
public final ForkJoinWorkerThread newThread(ForkJoinPool pool) {
return new ForkJoinWorkerThread(pool);
}
}容易看出ForkJoinPool创建线程的类型为ForkJoinWorkerThread。
ForkJoinWorkerThread对应的构造函数如下:
//ForkJoinWorkerThread继承Thread
public class ForkJoinWorkerThread extends Thread {
final ForkJoinPool pool; // the pool this thread works in
//ForkJoinWorkerThreadu确实有与其绑定的Queue
final ForkJoinPool.WorkQueue workQueue; // work-stealing mechanics
protected ForkJoinWorkerThread(ForkJoinPool pool) {
// Use a placeholder until a useful name can be set in registerWorker
super("aForkJoinWorkerThread");
this.pool = pool;
//需要调用ForkJoinPool才能得到对应的WorkQueue
this.workQueue = pool.registerWorker(this);
}
........
}我们继续看看ForkJoinPool的registerWorker函数:
final WorkQueue registerWorker(ForkJoinWorkerThread wt) {
UncaughtExceptionHandler handler;
AuxState aux;
//设置线程为daemon线程
wt.setDaemon(true); // configure thread
if ((handler = ueh) != null)
wt.setUncaughtExceptionHandler(handler);
//确实创建出定义于ForkJoinPool的WorkQueue
WorkQueue w = new WorkQueue(this, wt);
.........
wt.setName(workerNamePrefix.concat(Integer.toString(i >>> 1)));
return w;
}根据构造函数的一系列信息,我们知道了ForkJoinPool中的线程是如何与对应的WorkQueue关联起来。
三、使用方式
了解ForkJoinPool的基本信息后,我们先来看看ForkJoinPool如何使用。
此处为了直观省事,直接参考网上一个计算π的例子。
计算 π 的值有一个通过多项式方法,即:π = 4 * (1 - 1/3 + 1/5 - 1/7 + 1/9 - ……),
而且多项式的项数越多,计算出的 π 的值越精确。
当计算项很多的时候,我们就可以利用ForkJoinPool来分治了。
我们可以定义一个RecursiveTask来完成实际的计算工作:
static class PiEstimateTask extends RecursiveTask<Double> {
//计算项开始和结束的下标
private final long mBegin;
private final long mEnd;
//分割任务的临界值
private final long mThreshold;
PiEstimateTask(long begin, long end, long threshold) {
mBegin = begin;
mEnd = end;
mThreshold = threshold;
}
@Override
protected Double compute() {
Double ret;
// 临界值之下,不再分割,直接计算
if (mEnd - mBegin <= mThreshold) {
//符号,取1或者-1
//根据公式,从0开始,偶数项符号为1,奇数项符号为-1
int sign = (mBegin % 2 == 0) ? 1 : -1;
double result = 0.0;
for (long i = mBegin; i < mEnd; i++) {
result += sign / (i * 2.0 + 1);
sign = -sign;
}
ret = result * 4;
} else {
// 分割任务
long middle = (mBegin + mEnd) / 2;
PiEstimateTask leftTask = new PiEstimateTask(mBegin, middle, mThreshold);
PiEstimateTask rightTask = new PiEstimateTask(middle, mEnd, mThreshold);
// 异步执行leftTask和rightTask
leftTask.fork();
rightTask.fork();
// 阻塞,直到leftTask和rightResult执行完毕返回结果
double leftResult = leftTask.join();
double rightResult = rightTask.join();
// 合并结果
ret = leftResult + rightResult;
}
return ret;
}
}使用PiEstimateTask的代码类似于:
public static void main(String[] args) {
//定义线程的数量
ForkJoinPool pool = new ForkJoinPool(6);
//计算10亿项,分割任务的临界值为1千万
PiEstimateTask task = new PiEstimateTask(0, 1_000_000_000, 10_000_000);
// 阻塞,直到任务执行完毕返回结果
double pi = pool.invoke(task);
System.out.println("π 的值:" + pi);
pool.shutdown();
}值得注意的是,选取一个合适的分割任务的临界值,
对 ForkJoinPool 执行任务的效率有着至关重要的影响。
临界值选取过大,任务分割的不够细,则不能充分利用 CPU;
临界值选取过小,则任务分割过多,可能产生过多的子任务,
增加了线程间切换的开销,同时会加重GC的负担,从而影响了整体的效率。
四、总结
至此,我们初步理解了ForkJoinPool的设计思想和使用方式。
ForkJoinPool相关的源码还是比较复杂的,后面的博客中再单独分析。