本文主要介绍sklearn preprocessing四个数据预处理的函数,大概分两类,一是标准化,二是将将数据特征缩放至某一范围。
这四个函数都在sklearn preprocessing模块中,无论哪个方法,都是对列进行的操作。
一、标准化
标准化适用的情况:如果有些特征的方差过大,则会主导目标函数从而使参数估计器无法正确地去学习其他特征,这个时候需要数据标准化,分两步,一是去均值的中心化(均值变为0),二是方差的规模化(方差变为1)。通过这一步,可将特征值等级化,进而实现数据中心化。
原理:
z-score标准化(zero-mean normalization)
原理:均值为0,标准差为1(符合标准正态分布) –> mean=0, std=1
转换函数:
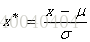
示例数据如下:
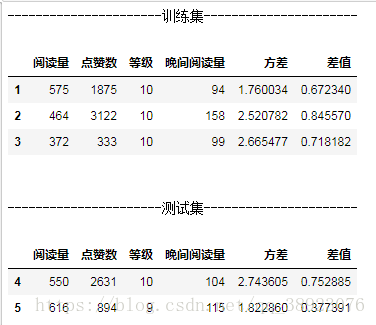
- scale()方法,适用不区分训练集与测试集前一次性变换
#scale方法的使用
#方法一
from sklearn import preprocessing
scale_data = preprocessing.scale(X)
#方法二
from sklearn.preprocessing import scale
scale_data = scale(X)
scale_data
#显示每列的均值和方差
scale_data.mean(axis=0)
scale_data.std(axis=0)
- StandardScaler()方法,计算训练集的平均值和标准差,以便测试数据集使用相同的变换
#StandardScaler()方法
from sklearn import preprocessing
stand_means = preprocessing.StandardScaler()
X_trans = stand_means.fit_transform(X)
Y_trans = stand_means.transform(Y)
print("X_trans如下:")
X_trans
print('-'*60)
print("Y_trans如下:")
Y_trans
二、将数据特征缩放至某一范围
缩放适用的情况:数据集的标准差非常非常小,有时数据中有很多很多零(稀疏数据)需要保存住0元素,这样处理可对方差非常小的属性增强其稳定性,也可维持稀疏矩阵中为0的条目,一般情况下是缩放到在[0,1]之间,或者是特征中绝对值最大的那个数为1,其他数以此维标准分布在[[-1,1]之间。
以上两者分别可以通过MinMaxScaler 或者 MaxAbsScaler方法来实现,实现方法同StandardScaler()方法一样
MinMaxScaler()原理:
转换函数:
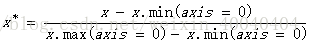
MaxAbsScaler()
原理与上面的很像,只是数据会被规模化到[-1,1]之间。也就是特征中,所有数据都会除以最大值。这个方法对那些已经中心化均值维0或者稀疏的数据有意义。