一、简介
本文是总结Oracle查询优化方法与改写技巧的第四篇文章,接着第三篇文章,继续。。。
二、优化技巧
【1】将结果集反向转置为一列
案例:将以下结果集反向转置为一列进行展示,并且每个员工信息之后空一行。
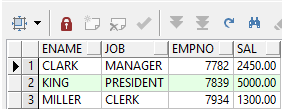
思路:利用之前说的unpivot( for in( ))语句实现即可,至于空一行,我们可以使用空值null作为占位占一行,空出来。
--将结果集反向转置为一列
--select e.ename, e.job, e.empno, e.sal from emp e where e.deptno = 10;
select decode(col, 'NULLCOL', '', col) as col, val
from (select e.ename,
e.job,
to_char(e.empno) empno,
to_char(e.sal) sal,
'' as nullcol
from emp e
where e.deptno = 10) unpivot include nulls(val for col in(ename, --生成的结果多一列val: 值就是对应ename/job/empno/sal的值
job, --生成的结果会多一列col:值即为ename/job/empno/sal/nullcol
empno,
sal,
nullcol));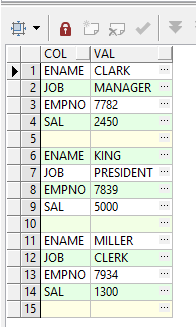
- 注意点1: unpivot的时候每列的数据类型必须一致,否则会报错,这也是下面使用to_char(xxx)转换数据类型的原因
--将结果集反向转置为一列
--注意点1: unpivot的时候每列的数据类型必须一致,否则会报错,这也是下面使用to_char(xxx)转换数据类型的原因
select decode(col, 'NULLCOL', '', col) as col, val
from (select e.ename,
e.job,
e.empno, --to_char(e.empno)
to_char(e.sal) sal,
'' as nullcol
from emp e
where e.deptno = 10) unpivot include nulls(val for col in(ename,
job,
empno,
sal,
nullcol));
- 注意点2: unpivot要使用include nullsm,空行才能显示
--将结果集反向转置为一列
--注意点2: unpivot要使用include nullsm,空行才能显示
select decode(col, 'NULLCOL', '', col) as col, val
from (select e.ename,
e.job,
to_char(e.empno) as empno,
to_char(e.sal) sal,
'' as nullcol --使用空值进行占位
from emp e
where e.deptno = 10) unpivot(val for col in(ename, --unpivot要使用include nullsm,空行才能显示
job,
empno,
sal,
nullcol));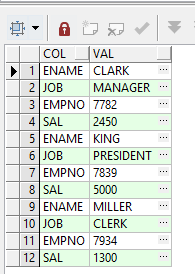
【2】抑制结果集中的重复值
实际项目中,有时候可能会将相同的重复值只显示一个,比如职位信息,每个职位可能有多个员工,只需要显示一个职位信息即可。
--抑制结果集中的重复值
select case
when t.job = t.prev_job then
null
else
t.job
end as job,
t.ename
from (select job, ename, lag(job) over(order by job) as prev_job --获取上一条记录的job
from emp
where deptno = 20
order by emp.job) t; --注意order by优先使用别名排序,所以需要使用表名.job进行排序
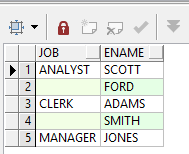
【3】利用 “行转列” 进行统计计算数据
案例:统计部门10 与部门20 员工总工资以及两个部门的工资差额
这种需求在实际项目中做统计列表的时候用的非常多,利用“行转列”的两种方法都可以实现。
(a)第一种方法:使用case when then else end 子句实现
--利用 “行转列” 进行统计计算数据
--案例:统计部门10 与部门20 员工总工资以及两个部门的工资差额
--行转列思想
select t.dept_10_totalsal,
t.dept_20_totalsal,
(t.dept_20_totalsal - t.dept_10_totalsal) as 差额
from (select sum(case --10号部门工资
when e.deptno = 10 then
e.sal
else
null
end) as dept_10_totalsal,
sum(case
when e.deptno = 20 then --20号部门工资
e.sal
else
null
end) as dept_20_totalsal
from emp e) t;
(b)第二种方法:使用pivot行转列查询两个部门的工资信息,再进行合计计算总工资,再求差额
--利用 “行转列” 进行统计计算数据
--案例:统计部门10 与部门20 员工总工资以及两个部门的工资差额
--第二种方法:使用pivot行转列查询两个部门的工资信息,再进行合计计算总工资,再求差额
select t.dept_10_totalsal,
t.dept_20_totalsal,
(t.dept_20_totalsal - t.dept_10_totalsal) as 差额
from (select sum(sal10) as dept_10_totalsal,
sum(sal20) as dept_20_totalsal
from emp e
pivot(sum(sal)
for deptno in(10 as sal10, 20 sal20))) t;
【4】对数据分组
案例:将职位为‘CLERK’和‘MANAGER’的数据分为四组
思想:利用ntail(n) over()分析函数即可实现。
select e.ename, e.empno, ntile(4) over(order by e.empno) as gp
from emp e
where e.job in ('CLERK', 'MANAGER');
- 注意点:当ntile分组的数量大于总记录数时,那么分为(大小为总记录数)组
--当ntile分组的数量大于总记录数时,那么分为(大小为总记录数)组
select e.ename, e.empno, ntile(10) over(order by e.empno) as gp
from emp e
where e.job in ('CLERK', 'MANAGER');
【5】计算简单的小计
案例: 统计各个部门的总工资以及整个公司的总工资
思路:要完成总计小计功能,需要用到group by rollup()增强的分组功能,能为每组返回一个小计,为所有分组返回一个总结功能。
--计算简单的小计
--案例: 统计各个部门的总工资以及整个公司的总工资
--group by rollup是分组统计的加强,能为每组返回一个小计,为所有分组返回一个总结功能
select case
when grouping(e.deptno) = 1 then
'工资合计'
else
to_char(e.deptno)
end as deptno,
sum(e.sal) as totalsal
from emp e
group by rollup(e.deptno);
观察下面两条sql:
--group by rollup是分组统计的加强,能为每组返回一个小计,为所有分组返回一个总结功能
select e.deptno, e.job, e.mgr, sum(e.sal) as totalsal
from emp e
group by rollup(e.deptno, e.job, e.mgr);
--group by rollup(a,b,c) 等价于 从右往左依次group by union all
select deptno, job, mgr, sum(sal) as totalsal
from emp
group by emp.deptno, emp.job, emp.mgr
union all
select deptno, job, null as mgr, sum(sal) as totalsal
from emp
group by emp.deptno, emp.job
union all
select deptno, null as job, null as mgr, sum(sal) as totalsal
from emp
group by emp.deptno
union all
select null as deptno, null as job, null as mgr, sum(sal) as totalsal
from emp e;group by rollup(a,b,c) 等价于 从右往左依次group by a,b,c union all group by a,b union all group by a union all ..
如果需要将deptno与job被当做一个整体进行统计合计功能的话,可以在rollup((deptno,job))实现。
select deptno, job, sum(sal) as totalsal
from emp
group by rollup((deptno, job));
【6】辨别是否为小计列
案例:很多时候,分组统计后需要展示‘合计’,如下图
思路:利用grouping(xxx) 参数只能是列名,并且只能是group by后分组的列名,当该列数据被汇总的时候,grouping(xx)返回1,当该列显示明细而不是汇总信息时,grouping(xx)返回0。
--辨别是否为小计列
--grouping(xxx) 参数只能是列名,并且只能是group by后分组的列名
--当该列数据被汇总的时候,grouping(xx)返回1,当该列显示明细而不是汇总信息时,grouping(xx)返回0
select case
when t.nm = 1 then
'工资合计'
else
to_char(t.deptno)
end as deptno,
t.totalsal
from (select e.deptno, grouping(e.deptno) as nm, sum(e.sal) as totalsal
from emp e
group by rollup(e.deptno)) t;
- 注意:尽量不要使用nvl(deptno,'工资合计')这种方式来判别是否为小计列,如果列值一定不为空,也可以使用,推荐使用grouping(xxx)这种方式。
- 原因: 因为当deptno本身就是null时,数据展示就不正确了。
select nvl(to_char(e.deptno), '工资合计') as deptno, sum(e.sal) as totalsal
from emp e
group by rollup(e.deptno);【7】计算所有表达式组合的小计
案例:要求按deptno、job任意组合汇总,并计算小计功能。
--计算所有表达式组合的小计
--案例:要求按deptno、job任意组合汇总,并计算小计功能。
select case t.a
when '00' then
'按部门、职位分组'
when '01' then
'按部门分组'
when '10' then
'按职位分组'
when '11' then
'总合计'
end as 分组依据,
t.deptno,
t.job,
t.sal,
t.a,
t.b
from (select deptno,
job,
sum(sal) as sal,
grouping(deptno) || grouping(job) as a,
grouping_id(deptno, job) as b --grouping_id(a,b)的值等于grouping(a) || grouping(b)拼接起来的数值当做二进制数,再转换为十进制数。
from emp
group by cube(deptno, job)
order by grouping(job), grouping(deptno)) t;
以下是对比cube(deptno,job)与rollup(deptno,job)的区别:
----------cube(deptno,job)----------
select deptno, job, sum(sal) as sal from emp group by cube(deptno, job);
--等同于
select deptno, job, sum(sal) as sal
from emp
group by deptno, job
union all
select deptno, null as job, sum(sal) as sal
from emp
group by deptno
union all
select null as deptno, job, sum(sal) as sal
from emp
group by job
union all
select null as deptno, null as job, sum(sal) as sal
from emp
group by null;
----------rollup(deptno,job)----------
select deptno, job, sum(sal) sal from emp group by rollup(deptno, job);
--等同于
select deptno, job, sum(sal) sal
from emp
group by deptno, job
union all
select deptno, null as job, sum(sal) sal
from emp
group by deptno
union all
select null as deptno, null as job, sum(sal) sal
from emp
group by null;
【8】员工在工作间的分布图
(1)第一种方法:使用case when then 子句实现行转列
--案例:员工在工作间的分布图
--第一种方法:使用行转列case when then end 子句进行转换
select t.ename,
decode(to_char(t.clerk), '1', '是', null) as clerk,
decode(to_char(t.manager), '1', '是', null) as manager,
decode(to_char(t.analyst), '1', '是', null) as analyst,
decode(to_char(t.president), '1', '是', null) as president,
decode(to_char(t.salesman), '1', '是', null) as salesman
from (select e.ename,
sum(case
when e.job = 'CLERK' then
1
else
null
end) as CLERK,
sum(case
when e.job = 'SALESMAN' then
1
else
null
end) as SALESMAN,
sum(case
when e.job = 'MANAGER' then
1
else
null
end) as MANAGER,
sum(case
when e.job = 'ANALYST' then
1
else
null
end) as ANALYST,
sum(case
when e.job = 'PRESIDENT' then
1
else
null
end) as PRESIDENT
from emp e
group by e.ename, e.job) t
order by t.ename;

(2)第二种方法:使用pivot实现行转列
--案例:员工在工作间的分布图
--第二种方法:使用行转列pivot函数进行转换
select ename,
decode(to_char(clerk_val), '1', '是', null) as clerk,
decode(to_char(salesman_val), '1', '是', null) as salesman,
decode(to_char(manager_val), '1', '是', null) as manager,
decode(to_char(president_val), '1', '是', null) as president,
decode(to_char(analyst_val), '1', '是', null) as analyst
from (select ename, job from emp)
pivot(sum(1) as val
for job in('CLERK' as CLERK,
'SALESMAN' as SALESMAN,
'MANAGER' as MANAGER,
'PRESIDENT' as PRESIDENT,
'ANALYST' as ANALYST))
order by ename;
【9】对不同分区、不同分组同时实现聚合
案例: 同时统计各个部门的总人数、各个职位的总人数、总人数
思路:我们首先想到的就是通过自连接查询出各个职位的总人数以及各个部门的总人数,然后再关联员工信息表,查出对应员工的部门总人数和职务总人数;当然如果熟悉分析函数的话,也可以直接使用分析函数,而且效率更高,减少了扫描表的次数。
(a)第一种方法:使用自关联的方法实现
--对不同分区、不同分组同时实现聚合
--案例:同时统计各个部门的总人数、各个职位的总人数、总人数
select e.deptno,
e.empno,
e.ename,
e.job,
(select count(*) from emp e where e.deptno in (10, 20)) as zrs,
a.bmzrs,
b.zwzrs
from emp e
inner join (select e.deptno, count(*) as bmzrs from emp e group by e.deptno) a --1.部门分组统计各个部门的总人数
on a.deptno = e.deptno
inner join (select e.job, count(*) as zwzrs from emp e group by e.job) b --2.按职位分组统计各个职位的总人数
on b.job = e.job --3.再根据部门、职位关联取出对应的总人数即可
where e.deptno in (10, 20);
(b)第二种方法:使用分析函数实现
--对不同分区、不同分组同时实现聚合
--案例: 同时统计各个部门的总人数、各个职位的总人数、总人数
select e.deptno,
e.sal,
e.ename,
e.job,
count(*) over() as zrs,
count(*) over(partition by e.deptno) as bmzrs, --按部门分区统计部门总人数
count(*) over(partition by e.job) as zwzrs --按职位分区统计职位总人数
from emp e
where e.deptno in (10, 20);
【10】常见开窗函数总结
常见的开窗函数有range开窗、rows开窗:
- range开窗:根据范围统计
- rows开窗:根据行数统计
(a)案例一:统计第一行到当前行为止的最低工资
--常见开窗函数
--案例:第一行到当前行为止的最低工资
--range开窗 row开窗
select e.ename,
e.sal,
min(e.sal) over(order by e.sal) as minsal,
min(e.sal) over(order by e.sal range between unbounded preceding and current row) as range_minsal,
min(e.sal) over(order by e.sal rows between unbounded preceding and current row) as rows_minsal,
/*所有行最低工资*/
min(e.sal) over() as minsal2,
min(e.sal) over(order by e.sal range between unbounded preceding and unbounded following) as range_minsal2,
min(e.sal) over(order by e.sal rows between unbounded preceding and unbounded following) as rows_minsal2
from emp e
where e.deptno = 30
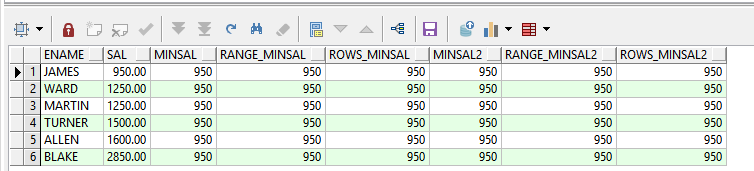
(b)案例二:统计第一行到当前行为止的最高工资
--常见开窗函数
--案例:第一行到当前行为止的最高工资
--range开窗 row开窗
select e.ename,
e.sal,
max(e.sal) over(order by e.sal) as maxsal,
max(e.sal) over(order by e.sal range between unbounded preceding and current row) as range_maxsal,
max(e.sal) over(order by e.sal rows between unbounded preceding and current row) as rows_maxsal,
max(e.sal) over() as maxsal2, --所有行最高工资
max(e.sal) over(order by e.sal range between unbounded preceding and unbounded following) as range_maxsal2,
max(e.sal) over(order by e.sal rows between unbounded preceding and unbounded following) as rows_maxsal2
from emp e
where e.deptno = 30
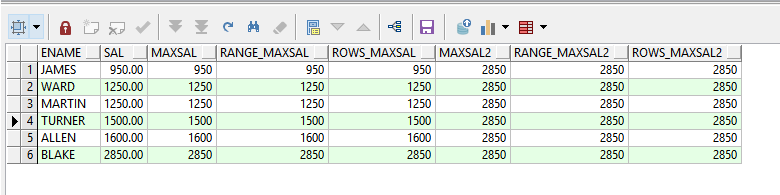
(c)案例三:统计第一行到当前行为止的工资累加和(特别注意工资相同情况下的区别)
--常见开窗函数
--案例:第一行到当前行为止的工资累加和(特别注意工资相同情况下的区别)
--range开窗 row开窗
select e.ename,
e.sal,
sum(e.sal) over(order by e.sal) as sumsal,
sum(e.sal) over(order by e.sal range between unbounded preceding and current row) as range_sumsal,
sum(e.sal) over(order by e.sal rows between unbounded preceding and current row) as rows_sumsal,
sum(e.sal) over() as sumsal2, --所有行工资总和
sum(e.sal) over(order by e.sal range between unbounded preceding and unbounded following) as range_sumsal2,
sum(e.sal) over(order by e.sal rows between unbounded preceding and unbounded following) as rows_sumsal2
from emp e
where e.deptno = 30
【11】简单树查找
案例: 查找上下级关系
- oracle树查询需要使用到start with ... connect by prior...子句
--简单树查找
--案例: 查找上下级关系
--采用oracle树查询实现
select empno, ename, mgr, (prior ename) as mgrname --上级名称
from emp
start with empno = 7566 --以7566为起点向下递归查找
connect by (prior empno) = mgr --上一级的员工编码等于本级的上级领导编码

【12】根节点、叶子节点、分支节点
案例:判别是否为根节点、叶子节点、分支节点
- 根节点:整个树的最上层(即level = 1)
- 叶子节点:在树中没有子级(即connect_by_isleaf = 1)
- 分支节点:排除根节点以及不是叶子节点的都是分支节点(即connect_by_isleaf = 0 and level > 1)
--根节点、叶子节点、分支节点
--根节点:整个树的最上层(即level = 1)
--叶子节点:在树中没有子级(即connect_by_isleaf = 1)
--分支节点:排除根节点以及不是叶子节点的都是分支节点(即connect_by_isleaf = 0 and level > 1)
select e.empno,
e.ename,
e.mgr,
(prior ename) as mgrname,
level as 层级,
case
when level = 1 then
'根节点'
else
null
end as 是否根节点,
case
when connect_by_isleaf = 1 then
'叶子节点(该员工不属于其他员工的上级)'
else
null
end as 是否叶子节点,
case
when connect_by_isleaf = 0 and level > 1 then --需要排除根节点(level = 1)
'分支节点'
else
null
end as 是否分支节点
from emp e
start with e.empno = 7566
connect by (prior empno) = e.mgr

【13】查看根节点到当前节点的路径
oracle提供了sys_connect_by_path(e.ename, ',')用来查看根节点到当前节点的路径。
--sys_connect_by_path
--案例:查看根节点到当前节点的路径
select t.empno, t.ename, t.mgr, t.mgrname, substr(t.enames, 2) as enames
from (select e.empno,
e.ename,
e.mgr,
(prior ename) as mgrname,
sys_connect_by_path(e.ename, ',') as enames
from emp e
start with e.empno = 7566
connect by (prior empno) = e.mgr) t
【14】树查询中的排序问题
- 树查询中的排序不能直接使用order by,而应该使用order siblings by, 对于树形数据,我们只需要针对同一条路径下的分支进行排序,这样就不会影响到整棵树的数据
--树查询中的排序问题
--树查询中的排序不能直接使用order by,而应该使用order siblings by, 对于树形数据,我们只需要针对同一条路径下的分支进行排序,这样就不会影响到整棵树的数据
--直接加order by
select lpad('-', (level - 1) * 2, '-') || e.empno as empno,
e.empno,
e.ename,
e.mgr,
(prior ename) as mgrname
from emp e
start with e.empno = 7566
connect by (prior empno) = e.mgr
order by e.empno desc;
--使用order siblings by
select lpad('-', (level - 1) * 2, '-') || e.empno as empno,
e.empno,
e.ename,
e.mgr,
(prior ename) as mgrname
from emp e
start with e.empno = 7566
connect by (prior empno) = e.mgr
order siblings by e.empno desc
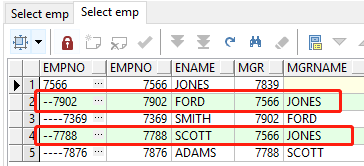
【15】树查找中的where子句
- 在树形查询中,where子句过滤的对象是树查询的结果,所以如果要先过滤再进行树查询,那么需要嵌套一个子查询.
select e.empno, e.ename, e.mgr from emp e where e.deptno = 20;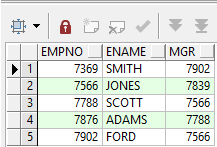
如上图,20号部门没有mgr is null的数据。
--先查询树数据,再进行过滤
select e.empno, e.ename, e.mgr, e.deptno, (prior ename) as mgrname
from emp e
where e.deptno = 20
start with e.mgr is null
connect by (prior empno) = e.mgr;
--等价于
select *
from (select e.empno, e.ename, e.mgr, e.deptno, (prior ename) as mgrname
from emp e
start with e.mgr is null
connect by (prior empno) = e.mgr) t
where t.deptno = 20;如果使用以上sql直接加where的话,数据过滤就不正确了,下面那个sql就是等价的,它是先进行树查询,然后再过滤整个树查询结果,因为20号部门没有mgr is null的数据,而看下面的查询结果却返回了数据,所以数据查询不正确。

正确的做法如下:
--先过滤数据,再进行树查询
select e.empno, e.ename, e.mgr, e.deptno, (prior ename) as mgrname
from (select * from emp where deptno = 20) e
where e.deptno = 20
start with e.mgr is null
connect by (prior empno) = e.mgr;
【16】查询树形的一个分支
- 查询树形的分支不能使用where,只需要通过start with xx指定开始遍历的节点即可
案例:查询员工编码为7698(BLAKE)及其下属员工
--查询树形的一个分支
--查询树形的分支不能使用where,只需要通过start with xx指定开始遍历的节点即可
--案例:查询员工编码为7698(BLAKE)及其下属员工
select e.empno,
e.ename,
e.mgr,
(prior ename) as 所属上级,
level as 层次,
decode(connect_by_isleaf, 1, '是', '否') as 是否叶子节点
from emp e
start with e.empno = 7698
connect by (prior empno) = e.mgr

【17】去除树形的一个分支
- 同查询树形的分支不能使用where,如果要去除树形的一个分支, 因为树查询的过滤条件通过connect by (xx = yy)指定,所以可以直接在connect by 后面加条件过滤即可
案例:去除员工编码为7698(BLAKE)及其下属员工在树查询结果中分支
--去除树形的一个分支
--同查询树形的分支不能使用where,如果要去除树形的一个分支, 因为树查询的过滤条件通过connect by (xx = yy)指定,所以可以直接在connect by 后面加条件过滤即可
--案例:去除员工编码为7698(BLAKE)及其下属员工在树查询结果中分支
select e.empno,
e.ename,
e.mgr,
(prior ename) as 所属上级,
level as 层次,
decode(connect_by_isleaf, 1, '是', '否') as 是否叶子节点
from emp e
start with e.mgr is null
connect by (prior empno) = e.mgr
and e.empno != 7698 --去除某个分支
【18】尽量少用标量子查询
select e.empno,
e.ename,
(select d.dname from dept d where d.deptno = e.deptno) as dname
from emp e
order by e.empno;上面的标量子查询为查询员工对应的部门名称。一般这样的需求都能通过左连接left join来改写:
--插入一条deptno为空的测试数据
insert into emp (empno, deptno) values (9999, null);
commit;
--使用left join代替标量子查询
select e.empno, e.ename, d.dname
from emp e
left join dept d
on d.deptno = e.deptno
order by e.empno;
对比一下两者方式的执行计划:


【19】使用left join优化标量子查询
- 未经过效率测试,尽量少使用标量子查询
首先,构造测试数据:
with temp1 as
(select 1 as id, 'a' as val, 1 as sid
from dual
union all
select 2 as id, 'b' as val, 2 as sid
from dual
union all
select 3 as id, 'c' as val, 3 as sid
from dual
union all
select 4 as id, 'd' as val, 2 as sid
from dual
union all
select 5 as id, 'e' as val, 1 as sid
from dual),
temp2 as
(select 1 as sid, 'aaaaa' as sname, 'bbbbb' as sdesc, 'ccccc' as sremark
from dual
union all
select 2 as sid, 'ddddd' as sname, 'eeeee' as sdesc, 'fffff' as sremark
from dual
union all
select 3 as sid, 'ggggg' as sname, 'hhhhh' as sdesc, 'iiiii' as sremark
from dual)查看下面的标量子查询:
--使用left join优化标量子查询
--未经过效率测试,尽量少使用标量子查询
with temp1 as
(select 1 as id, 'a' as val, 1 as sid
from dual
union all
select 2 as id, 'b' as val, 2 as sid
from dual
union all
select 3 as id, 'c' as val, 3 as sid
from dual
union all
select 4 as id, 'd' as val, 2 as sid
from dual
union all
select 5 as id, 'e' as val, 1 as sid
from dual),
temp2 as
(select 1 as sid, 'aaaaa' as sname, 'bbbbb' as sdesc, 'ccccc' as sremark
from dual
union all
select 2 as sid, 'ddddd' as sname, 'eeeee' as sdesc, 'fffff' as sremark
from dual
union all
select 3 as sid, 'ggggg' as sname, 'hhhhh' as sdesc, 'iiiii' as sremark
from dual)
--select * from temp1;
--select * from temp2;
--标量子查询
select t1.id,
t1.val,
/*以下三条标量子查询语句对temp2表扫描了三次,并且连接条件还是一样,这完全可以用left join进行优化*/
(select t2.sname from temp2 t2 where t1.sid = t2.sid) as sname,
(select t2.sdesc from temp2 t2 where t1.sid = t2.sid) as sdesc,
(select t2.sremark from temp2 t2 where t1.sid = t2.sid) as sremark
from temp1 t1;
可以看到,三条标量子查询语句对temp2表扫描了三次,并且连接条件还是一样,这完全可以用left join进行优化:
--使用left join优化标量子查询
--未经过效率测试,尽量少使用标量子查询
with temp1 as
(select 1 as id, 'a' as val, 1 as sid
from dual
union all
select 2 as id, 'b' as val, 2 as sid
from dual
union all
select 3 as id, 'c' as val, 3 as sid
from dual
union all
select 4 as id, 'd' as val, 2 as sid
from dual
union all
select 5 as id, 'e' as val, 1 as sid
from dual),
temp2 as
(select 1 as sid, 'aaaaa' as sname, 'bbbbb' as sdesc, 'ccccc' as sremark
from dual
union all
select 2 as sid, 'ddddd' as sname, 'eeeee' as sdesc, 'fffff' as sremark
from dual
union all
select 3 as sid, 'ggggg' as sname, 'hhhhh' as sdesc, 'iiiii' as sremark
from dual)
--使用left join优化标量子查询
select t1.id, t1.val, t2.sname, t2.sdesc, t2.sremark
from temp1 t1
left join temp2 t2
on t1.sid = t2.sid
使用left join改写之后,对temp2表只扫描了一次,对于数据量大时效率明显可以提高。下面对比两条sql的执行计划:


【20】left join改写标量子查询之聚合改写
案例:统计每个员工以及对应部门的总工资
要实现这个查询,可以有两个方法:
(1)第一种方法:使用标量子查询
--标量子查询方法
select e.empno,
e.ename,
e.sal,
e.deptno,
(select sum(e2.sal) from emp e2 where e2.deptno = e.deptno) as dept_total_sal --各个部门总工资
from emp e
order by e.deptno desc;(2)第二种方法:使用left join
--left join方法
select e.empno,
e.ename,
e.sal,
e.deptno,
t.dept_total_sal as dept_total_sal --各个部门总工资
from emp e
left join (select sum(e2.sal) as dept_total_sal, e2.deptno --先按部门编号分组统计各个部门的总工资
from emp e2
group by e2.deptno) t
on t.deptno = e.deptno; --然后根据部门编号建立连接条件对于改写有分组汇总统计的标量子查询时,需要先group by之后再进行left join关联。
【21】优化标量子查询的时候注意改写前后结果是否一致
首先构造一些测试数据:
--构造测试数据
create table dept2 as select * from dept;
insert into dept2 select * from dept where deptno = 10;
select * from dept2;
如上图,有两条重复的部门信息。
--优化标量子查询的时候注意改写前后结果是否一致
select e.job,
e.deptno,
(select distinct d.dname from dept2 d where d.deptno = e.deptno) as dname
from emp e
order by 1, 2, 3;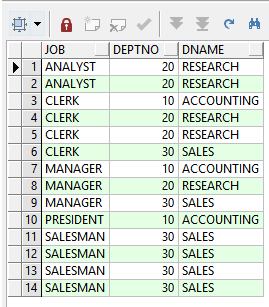
如上面sql查询的结果,有些部门信息重复的。下面我们展示错误的改写方法:将过滤重复部门信息的distinct关键字放在主查询,导致整个查询结果重复数据被过滤了。
--错误的改写方法
select distinct e.job, d.deptno, d.dname --如果将distinct加到主查询中,那么重复的结果就被过滤了,导致查询结果不正确
from emp e
left join dept2 d
on d.deptno = e.deptno
order by 1, 2, 3;
下面的改写方法才是正确的,先把重复的部门信息过滤了,再进行左连接操作。
select e.job, d.deptno, d.dname
from emp e
left join (select d.dname, d.deptno
from dept2 d
group by d.dname, d.deptno) d --正确的改写方法:先按部门名称、部门编号分组去掉重复的部门信息,然后再进行左连接
on d.deptno = e.deptno
order by 1, 2, 3;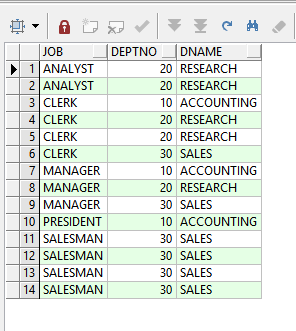
【22】用with子句抽取公共的sql(优化重复查询)
with子句其实就是把重复查询的数据(大数据量)的结果存在一张临时表,达到一次编译,多次执行的目的,可以提高效率。
select t1.xsid,
nvl(t1.blzt, '0') blzt,
xsjbxx.XSLBM,
case
when (select XZQHM
from (select xxxx.XZQHM
from VC_ZHXG_XTGL_JCSJ_XXXX xxxx
left join VC_ZHXG_XTGL_CSSZ cssz
on cssz.CSZ = xxxx.XXDM
and cssz.CSBZ = 'XTGL_DQXX')) =
substr(xsjbxx.SYDM, 1, 2) then
'Y'
when (select XZQHM
from (select xxxx.XZQHM
from VC_ZHXG_XTGL_JCSJ_XXXX xxxx
left join VC_ZHXG_XTGL_CSSZ cssz
on cssz.CSZ = xxxx.XXDM
and cssz.CSBZ = 'XTGL_DQXX')) !=
substr(xsjbxx.SYDM, 1, 2) then
'N'
else
'other'
end isInProvince,
xslb.MC
from zhxg_yx_jcsj_xsgl xsgl
left join zhxg_xsxx_xsjbxx xsjbxx
on xsgl.xsid = xsjbxx.PKID
left join zhxg_xtgl_dmk_cl xslb
on xslb.dmbz = 'XTGL_XSLBM'
and xsjbxx.XSLBM = xslb.dm
通过查看上面的sql, 我们发现:

这两部分的查询语句是一模一样的,如果表的数据量超级大,那查询肯定会慢很多,遇到这种场景,我们可以使用with as子句改写,将重复访问数据表的语句抽取出来,改写后的sql如下:
with res as
(select xxxx.XZQHM
from VC_ZHXG_XTGL_JCSJ_XXXX xxxx
left join VC_ZHXG_XTGL_CSSZ cssz
on cssz.CSZ = xxxx.XXDM
and cssz.CSBZ = 'XTGL_DQXX')
select t1.xsid,
nvl(t1.blzt, '0') blzt,
xsjbxx.XSLBM,
case
when (select XZQHM from res) = substr(xsjbxx.SYDM, 1, 2) then
'Y'
when (select XZQHM from res) != substr(xsjbxx.SYDM, 1, 2) then
'N'
else
'other'
end isInProvince,
xslb.MC
from zhxg_yx_jcsj_xsgl xsgl
left join zhxg_xsxx_xsjbxx xsjbxx
on xsgl.xsid = xsjbxx.PKID
left join zhxg_xtgl_dmk_cl xslb
on xslb.dmbz = 'XTGL_XSLBM'
and xsjbxx.XSLBM = xslb.dm
【23】错误的分析函数用法
- 注意:分析函数只能分析主查询返回的结果
案例:统计入职日期在‘1981-01-01’到‘1982-01-01’范围内的员工信息以及对应部门的最高工资和最低工资。
要实现这个查询,有两种方法,一种就是通过自连接方法查询,另外一种就是通过分析函数实现。
--案例:统计入职日期在‘1981-01-01’到‘1982-01-01’范围内的员工信息以及对应部门的最高工资和最低工资
--自连接方式
select e.empno, e.ename, e.sal, e.deptno, t.minsal, t.maxsal
from emp e
inner join (select e2.deptno, min(e2.sal) as minsal, max(e2.sal) as maxsal --按部门分组统计各个部门的最高、最低工资
from emp e2
group by e2.deptno) t
on t.deptno = e.deptno
where e.hiredate >= to_date('1981-01-01', 'yyyy-mm-dd')
and e.hiredate < to_date('1982-01-01', 'yyyy-mm-dd')
and e.deptno in (10, 20)
order by e.deptno, e.sal;
下面是使用分析函数实现,如果稍不注意,就可以踩坑导致查询结果不正确了。
--案例:统计入职日期在‘1981-01-01’到‘1982-01-01’范围内的员工信息以及对应部门的最高工资和最低工资
--使用分析函数改写
select e.empno,
e.ename,
e.sal,
e.deptno,
min(e.sal) over(partition by e.deptno) as minsal, --实际上分析函数只会分析主查询返回的结果,所以统计的是加了e.hiredate时间范围过滤的最高工资、最低工资
max(e.sal) over(partition by e.deptno) as maxsal
from emp e
where e.hiredate >= to_date('1981-01-01', 'yyyy-mm-dd')
and e.hiredate < to_date('1982-01-01', 'yyyy-mm-dd')
and e.deptno in (10, 20)
order by e.deptno, e.sal;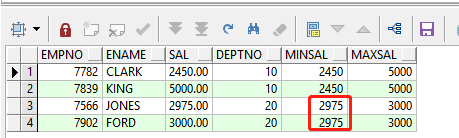
仔细观察查询结果,发现最低工资并不正确,这是因为分析函数对主查询返回的结果进行分析,因为主查询返回的结果只查询了入职日期在1981范围内的,所以取出的最低工资不正确。实际上上面的sql等价于下面的sql:先过滤数据,然后再进行分析统计最低、最高工资:
select e.empno,
e.ename,
e.sal,
e.deptno,
min(e.sal) over(partition by e.deptno) as minsal,
max(e.sal) over(partition by e.deptno) as maxsal
from (select e.empno, e.ename, e.sal, e.deptno
from emp e
where e.hiredate >= to_date('1981-01-01', 'yyyy-mm-dd')
and e.hiredate < to_date('1982-01-01', 'yyyy-mm-dd')
and e.deptno in (10, 20)) e;正确的改写方式:应该是先将最高、最低工资通过分析函数查询出来,然后再进行过滤条件,见下面sql:
--案例:统计入职日期在‘1981-01-01’到‘1982-01-01’范围内的员工信息以及对应部门的最高工资和最低工资
/*正确的改写方法: 先用分析函数统计出整个表最高、最低工资,再在外面嵌套一层子查询,再将e.hiredate时间范围过滤条件加上去*/
select t.empno, t.ename, t.sal, t.deptno, t.minsal, t.maxsal
from (select e.empno,
e.hiredate,
e.ename,
e.sal,
e.deptno,
min(e.sal) over(partition by e.deptno) as minsal,
max(e.sal) over(partition by e.deptno) as maxsal
from emp e) t --嵌套一层子查询
where t.hiredate >= to_date('1981-01-01', 'yyyy-mm-dd')
and t.hiredate < to_date('1982-01-01', 'yyyy-mm-dd')
and t.deptno in (10, 20)
order by t.deptno, t.sal;

【24】巧用left join优化not in (xxx,xxx...)
大家都知道,在大数据量情况下,in和not in 的效率并不是特别好,这时候我们可以考虑将in/not in改造成使用 (left join左连接 + 右表.id is null),这样效率相对可能会高点。看下面的示例:
首先构造测试数据:
with temp as
(select 1 as id, '1' as val
from dual
union all
select 2 as id, '2' as val
from dual
union all
select 3 as id, '3' as val
from dual
union all
select 4 as id, null as val
from dual),
temp2 as
(select 1 as id, '1' as val
from dual
union all
select 2 as id, '2' as val
from dual
union all
select 4 as id, '4' as val
from dual)
--查询temp2表中值不在temp表中的记录
select * from temp2 t2 where t2.val not in (select t1.val from temp t1);
可以看到,返回结果为空,这明显不正确,对比一下数据发现应该要返回一条数据id=‘4’,val='4'才对。
--巧用left join优化not in (xxx,xxx...)
--假设temp,temp2表里面都没有重复的id
with temp as
(select 1 as id, '1' as val
from dual
union all
select 2 as id, '2' as val
from dual
union all
select 3 as id, '3' as val
from dual
union all
select 4 as id, null as val
from dual),
temp2 as
(select 1 as id, '1' as val
from dual
union all
select 2 as id, '2' as val
from dual
union all
select 4 as id, '4' as val
from dual)
--查询temp2表中值不在temp表中的记录
select *
from temp2 t2
where t2.val not in (select t1.val from temp t1 where t1.val is not null);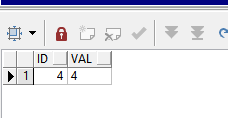
上面使用not in查询出了正确结果,下面我们使用left jon 改造它:
--巧用left join优化not in (xxx,xxx...)
--假设temp,temp2表里面都没有重复的id
with temp as
(select 1 as id, '1' as val
from dual
union all
select 2 as id, '2' as val
from dual
union all
select 3 as id, '3' as val
from dual
union all
select 4 as id, null as val
from dual),
temp2 as
(select 1 as id, '1' as val
from dual
union all
select 2 as id, '2' as val
from dual
union all
select 4 as id, '4' as val
from dual)
--查询temp2表中值不在temp表中的记录
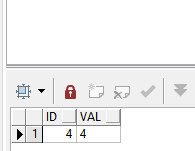
select t2.id, t2.val
from temp2 t2
left join temp t1
on t1.val = t2.val
where t1.val is null;
【25】巧用分析函数解决问题
案例:求每个月的平均交易额、上个月平均交易额。
拿到这个需求,可能首先想到的解决方法就是写子查询,也相对简单点:
with temp as
(select to_date('2019-01-31', 'yyyy-mm-dd') as comdate, --每月最后一天
to_date('2019-01-09', 'yyyy-mm-dd') as translatedate, --交易日期
1 as account --交易额
from dual
union all
select to_date('2019-01-31', 'yyyy-mm-dd') as comdate,
to_date('2019-01-09', 'yyyy-mm-dd') as translatedate,
2 as account
from dual
union all
select to_date('2019-02-28', 'yyyy-mm-dd') as comdate,
to_date('2019-02-09', 'yyyy-mm-dd') as translatedate,
11 as account
from dual
union all
select to_date('2019-02-28', 'yyyy-mm-dd') as comdate,
to_date('2019-01-10', 'yyyy-mm-dd') as translatedate,
12 as account
from dual)
--案例:求每个月的平均交易额、上个月平均交易额
--使用子查询实现
select t.comdate,
t.translatedate,
t.account,
(select avg(t2.account) from temp t2 where t2.comdate = t.comdate) as avg_account,
(select avg(t2.account)
from temp t2
where t2.comdate = add_months(t.comdate, -1)) as prev_month_avg_account
from temp t;

观察如上sql,对temp表扫描了三次,其实我们用分析函数很容易求出本月的平均交易额,但是如何获取上个月的,这也是技巧所在,这里利用row_number()生成了每条记录在当月对应的序号,然后再利用lead()取前面n条记录来获取上个月平均交易额,具体sql如下:
with temp as
(select to_date('2019-01-31', 'yyyy-mm-dd') as comdate, --每月最后一天
to_date('2019-01-09', 'yyyy-mm-dd') as translatedate, --交易日期
1 as account --交易额
from dual
union all
select to_date('2019-01-31', 'yyyy-mm-dd') as comdate,
to_date('2019-01-09', 'yyyy-mm-dd') as translatedate,
2 as account
from dual
union all
select to_date('2019-02-28', 'yyyy-mm-dd') as comdate,
to_date('2019-02-09', 'yyyy-mm-dd') as translatedate,
11 as account
from dual
union all
select to_date('2019-02-28', 'yyyy-mm-dd') as comdate,
to_date('2019-01-10', 'yyyy-mm-dd') as translatedate,
12 as account
from dual)
--案例:求每个月的平均交易额、上个月平均交易额
--使用分析函数实现
select t2.comdate,
t2.translatedate,
t2.account,
t2.avg_account,
t2.pxh,
/*巧妙之处 : 根据每个月分组、按交易日期排序之后得到在每个月的序号,然后利用lead()函数获取上个月的日均交易额*/
lag(t2.avg_account, t2.pxh) over(order by t2.translatedate) as prev_month_avg_account
from (select t.comdate,
t.translatedate,
t.account,
avg(t.account) over(partition by t.comdate) as avg_account,
row_number() over(partition by t.comdate order by t.translatedate) as pxh
from temp t) t2;
我们可以对比一下两者的执行计划:


【26】多列关联的半连接与索引
首先构造测试数据:
--多列关联的半连接与索引
create table emp2 as select ename,job,sal,comm from emp where job = 'CLERK';
create index idx_emp2_ename on emp2(ename);
观察下面的sql:
--多列关联的半连接与索引
--合并后半连接的效率并没有那么好,不走普通索引,全表扫描
select e.ename, e.job, e.sal
from emp e
where (e.ename || e.job || e.sal) in
(select e2.ename || e2.job || e2.sal from emp2 e2);
在不影响数据的情况下,建议不用半连接,这样的话可以走索引,提高效率。改写如下:
--多列关联的半连接与索引
--在不影响数据的情况下,可以不用半连接,这样的话可以走索引
select e.ename, e.job, e.sal
from emp e
where (e.ename, e.job, e.sal) in
(select e2.ename, e2.job, e2.sal from emp2 e2);

下面,对比一下两者的执行计划:


三、总结
这是第四部分的总结以及一些案例,通过差不多三周的时间,有空的时候看几个例子,把《Oracle查询优化改写技巧与案例》这本书前面12章大部分的例子都手敲了一遍,也学习了一些高级用法,在以后的工作总尽量用一些效率高一些的sql写法。