版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/STILLxjy/article/details/86496740
原始数据: 在Data.csv文件中我们有如下数据:

统计了10个人的基本信息:国籍,年龄,工资 以及他们对于某件商品是否购买的情况。
代码实现细节分析:
(1)导入基本python包
import numpy as np
import pandas as pd
(2)导入数据,读取.csv文件中的数据
dataset = pd.read_csv('Data.csv') #读取指定.csv文件,返回DataFrame
X = dataset.iloc[ : , : -1].values #获取指定索引的行列数据 iloc = “index location”
Y = dataset.iloc[ : , 3].values
结果显示: 表格中为空的数据,在X中使用nan表示

(3)处理丢失数据,将1,2列中 nan 的数据使用该列中所有已知数的平均值代替
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = "NaN", strategy = "mean", axis = 0)
imputer = imputer.fit(X[:,1:3])
X[:,1:3] = imputer.transform(X[:,1:3])
结果显示:

(4)解析分类数据:将非数值型数据转换为对应的数值型数据或者使用onehot类型的数据表示。
在X的第一列为国籍信息,数据类型为字符串,将其转换为对应的数字编号,按照字典序排列。
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder()
X[:,0] = labelencoder_X.fit_transform(X[:,0])
结果显示:

再将X的第一列数值编号转换为对应的onehot类型,即 0 转化为 [1,0,0] , 1 转化为 [0,1,0] , 2转化为 [0,0,1]。因此X从3列转换为了5列。
categorical_features = [0]: 将索引为0的属性转化为 onehot类型
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()
结果显示:

将Y的NO ,YES 转化为 0 , 1
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)
结果显示:

(5)将数据按8:2的比例分为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 0)
结果显示:


(6)将数据进行标准化或归一化:
标准化数据通过减去均值然后除以方差(或标准差),这种数据标准化方法经过处理后数据符合标准正态分布,即均值为0,标准差为1,转化函数为:
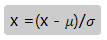
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
结果显示:

数据预处理流程:
