这一章介绍了卷积神经网络——在深度学习中非常常用的一种网络,先建立简单的网络,然后添加很多增强网络能力的方法:卷积、池化、GPU、dropout等等。这一章建立的网络很强大,正确率达到99.67%,识别错误的数字很多是人眼也无法正确识别的。还会提到RNN、LSTM单元,如何在语音识别、自然语言处理或者其他领域运用模型。
Introducing convolutional networks
之前我们用的是全连接网络,有784个输入,分别输入784个像素的灰度值。但是这个网络并没有考虑到输入图像的空间结构,网络把离得很远的像素和离的很近的像素一视同仁,这一章的卷积神经网络就利用了图像像素的空间结构的优势,使网络训练的更快更好。
卷积神经网络有三个基本概念:局部感受野(local receptive fields),共享权值(shared weights),池化(pooling)。
Local receptive fields
我们并不把所有的784个input neuron和第一层隐藏层全部连接起来,而是只连接一小部分的神经元。比如我们只选取输入神经元中55的小块区域与第一层隐藏层连接:

这一小部分55的区域称作局部感受野local receptive field。我们将这个小区域在整个input image上滑动,对于每一个局部感受野,在第一层隐藏层都有一个不同的隐藏神经元与其对应,比如开始时我们从左上角选取一个局部感受野:

然后将其向右滑动一个单位,连接第二个隐藏神经元:

然后继续向右,建立第一层隐藏神经元。注意到,如果input层是2828,而局部感受野大小为55,那么第一层隐藏层就是2424的大小。
上面是一个一个神经元移动的,也可以使用不同的步长,比如说一下移动两个神经元的位置。计算第一层隐藏层的大小的方法也很简单,记输入层边长为OriginalSize,局部感受野边长为kernelsize,步长为stride,之后可能还会在图像边缘加上padding,就是多加一些像素,总体计算方法是:
outputsize = [(OriginalSize+padding2-kernelsize)/stride] + 1
Shared weights and biases
每一个隐藏神经元有一个偏置和55的权重,对第j,k个隐藏神经元,其输出为:
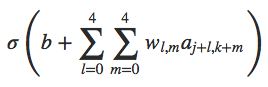
b是每一个隐藏神经元的偏重,wl,m是一个55的权重矩阵,记x, y处的输入激活值为ax,y。用同一个w表示,第一层隐藏层检测的是同样的特征,只是位置不同而已,这就是权重共享,大大减少了需要训练的权值个数。比如,有一组特定的w和b,当局部感受野中有一条竖线时,隐藏神经元可以被激活,那这条竖线的特征,在图像的其他地方也可以被发现,从而激活相应的隐藏神经元。更抽象来说,卷积神经网络有一个性质为不变性:移动图片,网络依旧可以进行识别。
由于这个原因,我们称从输入层到隐藏层的映射为feature map特征映射,将决定特征映射的权重和偏置称为shared weights共享权重、shared bias共享偏置,这两个参数定义了kernel核或者叫filter过滤器。
一般来说,我们需要不止一个feature map,一个kernel可以卷积出一张特征图,所以用不同的卷积核做卷积就可以得到不同的feature map:

这个例子有三个feature map,每一个feature map都有一个55的共享权重和一个共享偏置。这个网络可以在整个image中检测三种不同的特征。在这一章最后完成的网络中作者训练了20个feature map:

这20张图片对应20个不同的feature map(or kernels, or filters),每一个特征图都代表了一个55的图像,对应了局部感受野中55的权重。像素越白,表示权重越小,表示特征图对相对应的输入像素响应越小。这些特征有明暗边缘,表示网络训练时确实考虑了空间结构因素。
共享权值和共享偏置最大的好处就是大大减少了需要计算的参数个数。比如,对于每张特征图我们有55=25个权值和1个偏置,如果我们有20张特征图,只需要计算520个参数。而如果是一个全连接网络[784, 30, 10],有784*30个权值和30个偏置,就是23550个参数。
Pooling layers
池化层在卷积层之后,用来简化卷积层的输出。每一个池化层的单元都代表了之前的层的一个区域的结果,比如,一个22的小区域:

上面的图展示的是一种池化方式:max-pooling,输出之前22区域中最大的值。卷积层的大小是2424,池化之后只有1212。每一张特征图都有一个池化层:
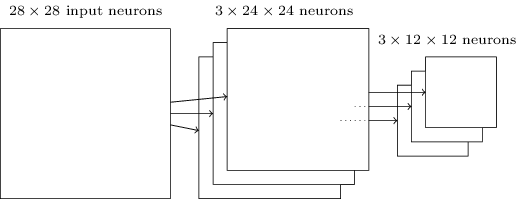
max-pooling层相当于网络在表示是否检测到了这个特征,然后丢弃了绝对位置信息。当一个特征被找到后,它的绝对位置信息就不如相对(其他特征的)位置信息重要了。还有一种池化方法是L2池化,不再是选取22中最大的值,而是选取22区域中激活值平方和再开根。
Putting it all together
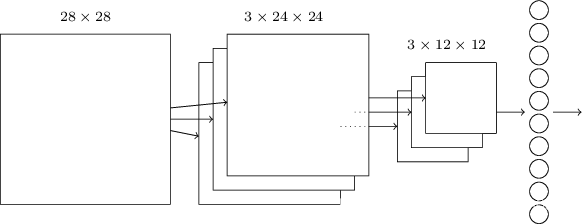
刚开始是2828的输入层,然后接一个由55的卷积核得到的卷积层(隐藏层),由三个特征图组成,再接一个max-pooling层,最后一层是十个神经元,代表了十个输出。这一层与池化层之间是全连接。我们还是使用随机梯度下降和后向传播。
Convolutional neural networks in practice
这次的网络就是network3.py啦~这边用了一个库叫Theano,这个库也可以在GPU上跑,速度快很多。给一个如何安装Theano的链接instructions
刚开始先建立一个浅层网络,一个隐藏层,60epoch,
=0.1:
import network3
from network3 import Network
from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer
training_data, validation_data, test_data = network3.load_data_shared()
mini_batch_size = 10
net = Network([FullyConnectedLayer(n_in=784, n_out=100), SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
net.SGD(training_data, 60, mini_batch_size, 0.1, validation_data, test_data)
最好的正确率是97.80%。为了提高正确率,我们在input layer之后插入卷积层,局部感受野55,stride=1,20个feature map,之后插入max-pooling层,池化窗为22:

net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5), poolsize=(2, 2)),
FullyConnectedLayer(n_in=20*12*12, n_out=100),
SoftmaxLayer(n_in=100, n_out=10)],
mini_batch_size, 0.1, validation_data, test_data)
正确率98.78%。如果我们再加一层卷积层,正确率会达到99.06%。
Rectified linear units
除了sigmoid函数,之前也说过可以用其他函数作为激活函数,比如tanh。也可以用矫正线性单元rectified linear units,f(z)=max(0, z),加上L2正则化, =0.1:
from network3 import ReLU
net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
net.SGD(training_data, 60, mini_batch_size, 0.03, validation_data, test_data, lmbda=0.1)
改用ReLU得到了99.23%的正确率。
Expanding the training data
一个很好的方法就是把图像上下左右移动一个像素,用expand_mnist.py,这里面有250000张图像:
$ python expand_mnist.py
在之前的网络前加一句
expand_training_data, _, _=network3.load_data_shared("../data/mnist_expanded.pk1.gz")
得到99.37%的正确率。
如果再加一层全连接层,并且加上dropout防止过拟合,可以得到99.60%的正确率。代码就是在全连接层的最后一个参数加上p_dropout:
FullyConnectedLayer(n_in=40*4*4, n_out=1000, activation_fn=ReLU, p_dropout=0.5)
此时可以把epoch从60减少到40,因为已经有dropout防止过拟合了,我们可以学习的更快。注意全连接层现在是1000的神经元。