版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/github_35631540/article/details/86539014
今天介绍一款软件,可以快速获取一个网站的所有资源,图片,html,css,js......
以获取某车官网为例 我来展示一下这个软件的功能.
输入网站地址和网站要保存的文件夹
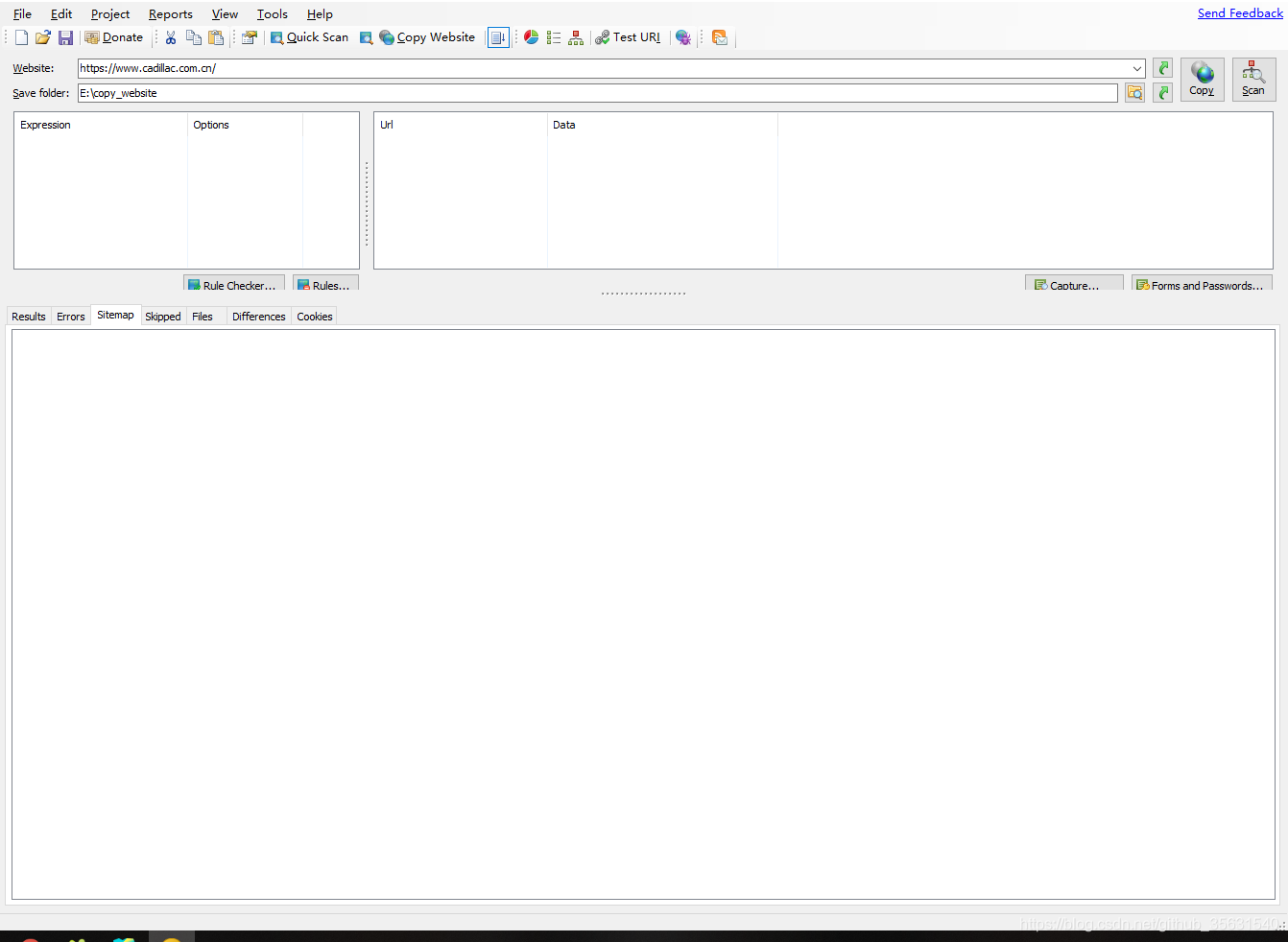
如果网站名称后我们可以扫描一下网站, 以便我们更好的筛选资源,剔除不要的链接,添加爬取得链接
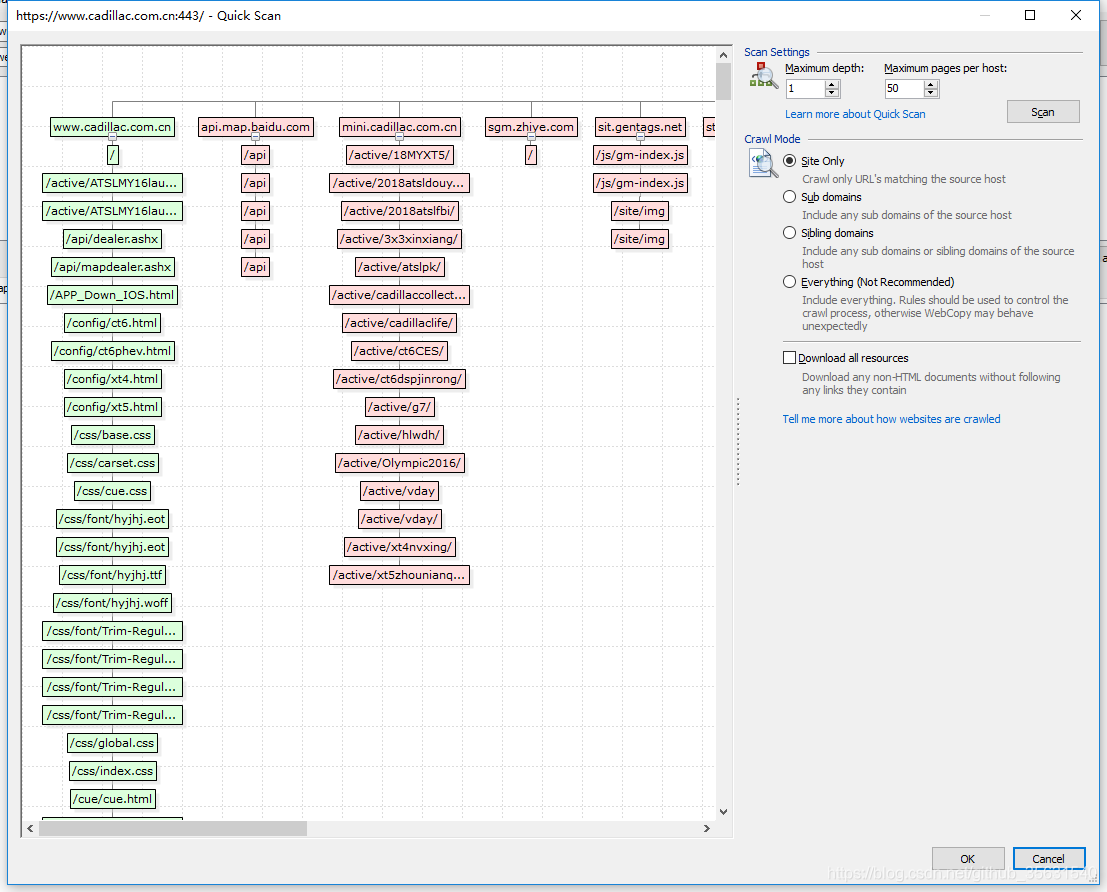
在这里也可以设置爬去的链接的深度和广度,相邻域名,
设置好了这些,就可以点击Copy按钮了

接下来就会看到完整的爬取过程,当前爬取的链接,爬取的结果
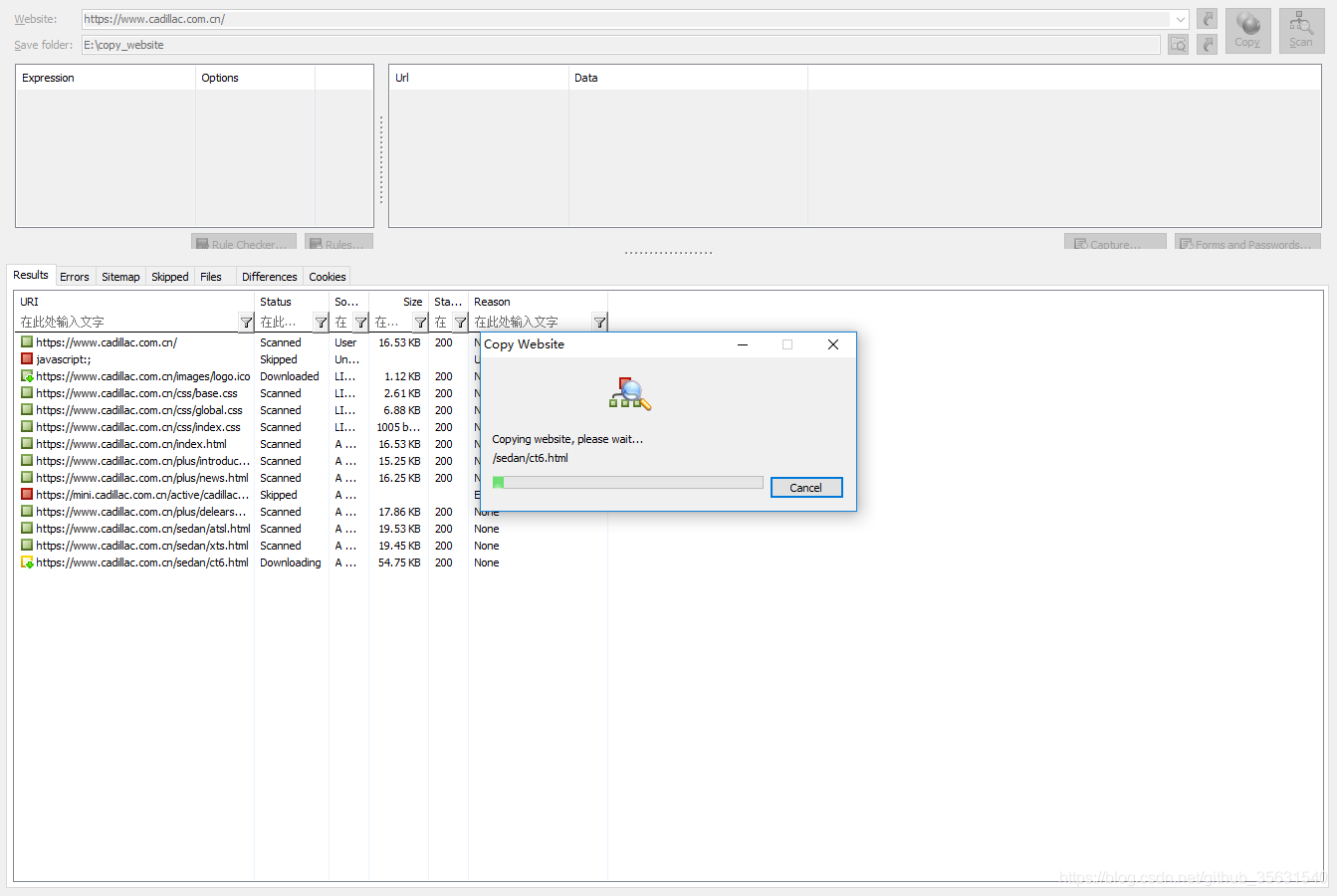
可以看到那些错误,那些跳过了,还有文件类型,页面的Title,文件大小.
再爬取的过程中 你可以再开启一个软件的窗口,进行另一个个爬取任务,
这个软件的其他菜单,这个工具还是很强大的,可以自定义正则表达式来过来url,资源,还可以把爬取任务保存起来,以便再次使用,
还可以设置代理,分析网站.



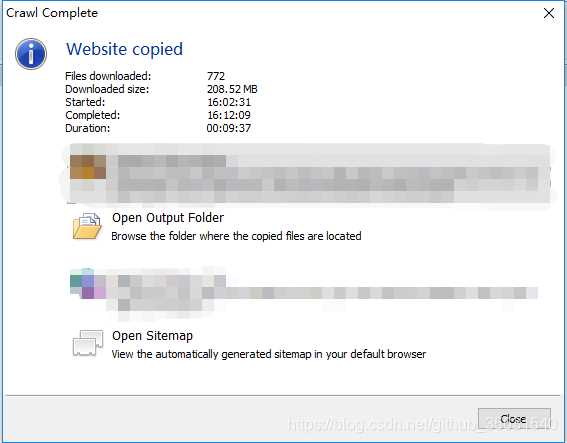
爬取完成后,会有一个爬取统计 下载了多少文件,多少MB
进入文件夹查看下载的文件
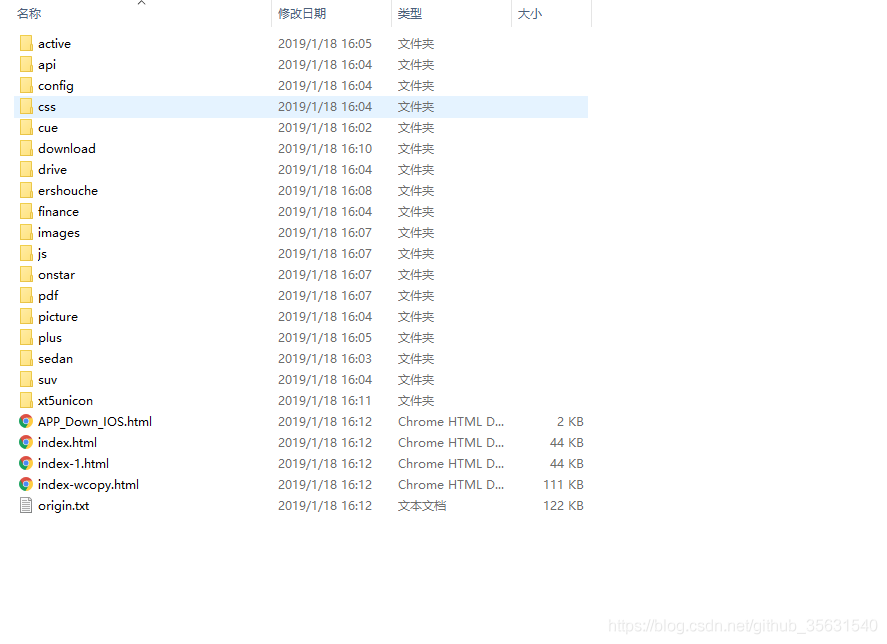
直接打开首页
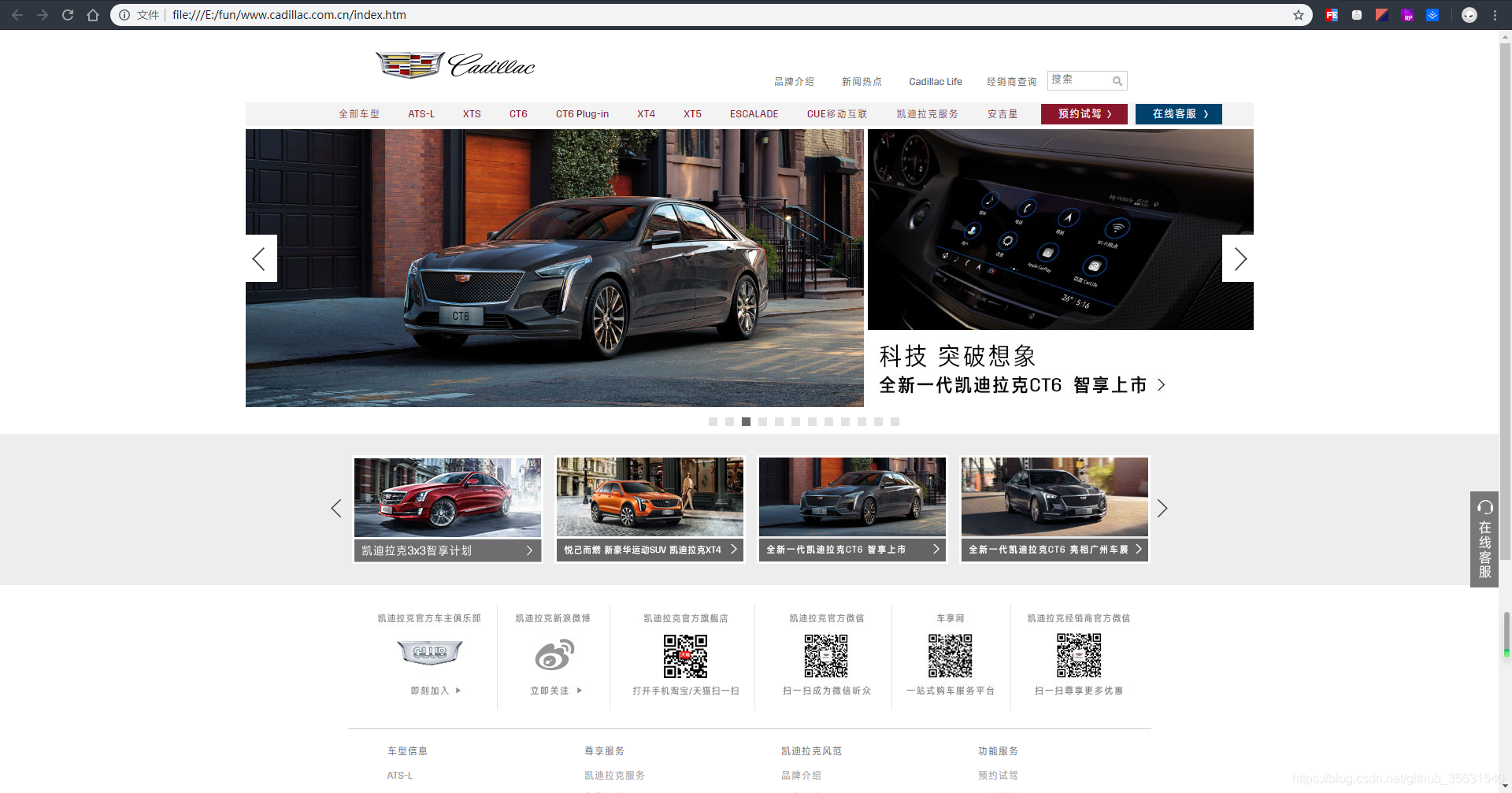
到此,爬取网站就结束了,有些网站的资源使用的是国外的js,css,速度会有些差异,但效果都是一样的.爬取下来就能使用.放到服务器就能访问了
最后给大家介绍几款爬站工具
IDM
注意:扒站需谨慎,版权纠纷.