常用的正则表达式可以在线生成,不需要自己写;
正则表达式在线生成器:https://www.sojson.com/regex/generate
案例:
1.匹配URL地址
生成正则表达式:^ ((https|http|ftp|rtsp|mms)?: //)[^\s]+
分析:
^:
如果没有在[ ]里面的时候, 代表以什么开头;
如果在[ ]里面的时候,代表除了…之外;
(https|http|ftp|rtsp|mms):代表一个分组
代码:
import re
url = 'http://www.baidu.com'
pattern = r'^((https|http|ftp|rtsp|mms)?:\/\/)\S+'
# 进行分组的时候, findall方法只返回分组里面的内容;
# print(re.findall(pattern, url))
resObj = re.search(pattern, url)
if resObj:
# group方法会返回匹配的所有内容;
print(resObj.group())
# groups方法返回分组里面的内容;
print(resObj.groups())
运行结果:
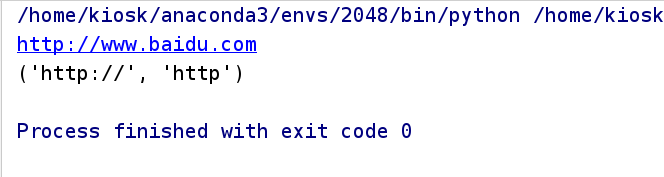
2.匹配日期
生成正则表达式:\d{4}(-|/|.)\d{1,2}\1\d{1,2}
分析:其中 \1 代表的是一定要与第一个分组的内容保持一致, 否则不匹配
即 2019-1-3 能匹配到,而 2019-1.4 匹配不到
代码:
import re
date = '2019-2-15'
pattern = r'\d{4}(\-|\/|.)\d{1,2}\1\d{1,2}'
reObj = re.search(pattern, date)
if reObj:
print(reObj.group())
print(reObj.groups())
运行结果:

3.匹配用户名
生成正则表达式:[\w-\u4e00-\u9fa5]+
分析:
字符串是否包含中文:[\u4e00-\u9fa5]
\u4e00是Unicode中汉字的开始,\u9fa5则是Unicode中汉字的结束;
[ ]表示匹配方括号的中任意字符;
代码:
import re
user = '西部开源123'
pattern = r'[\w\-\u4e00-\u9fa5]+'
print(re.findall(pattern, user))
运行结果:
