2018年行为识别文献
文章目录
- Appearance-and-Relation Networks for Video Classification(2018)
- Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recognition(2018)
- A Closer Look at Spatiotemporal Convolutions for Action Recognition(2018)
- End-to-end Video-level Representation Learning for Action Recognition(2018)
- Non-local Neural Networks(2018)
- Compressed Video Action Recognition(2018)
- A(2018)
Appearance-and-Relation Networks for Video Classification(2018)
ARTNet(Appearance-and-Relation NetWork) 论文
内容
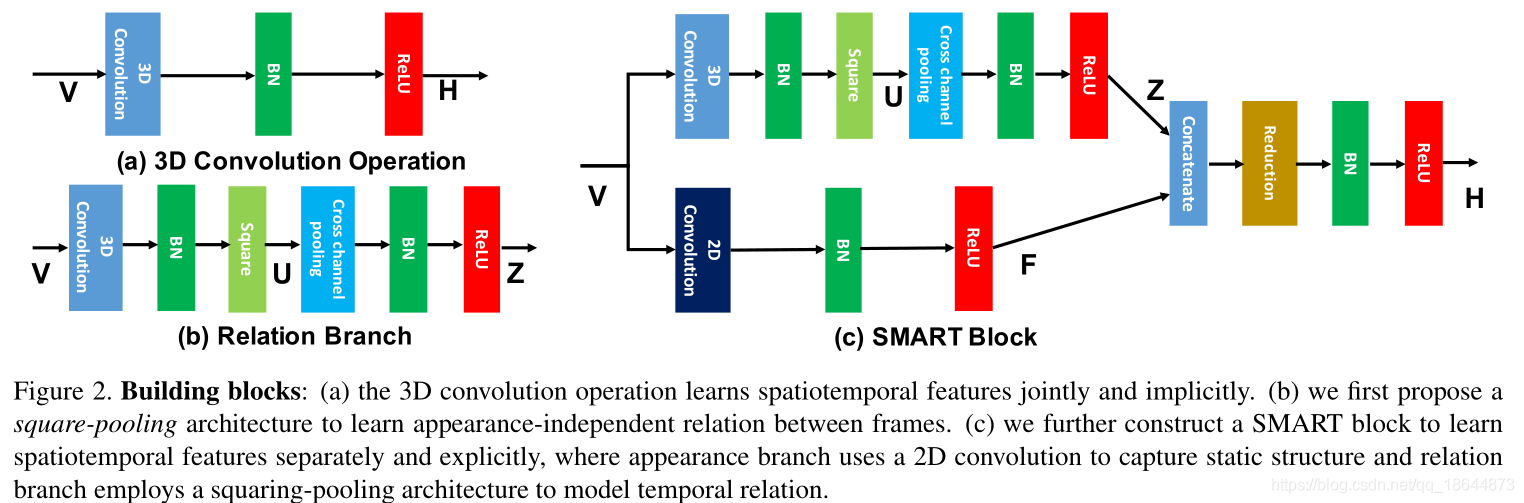
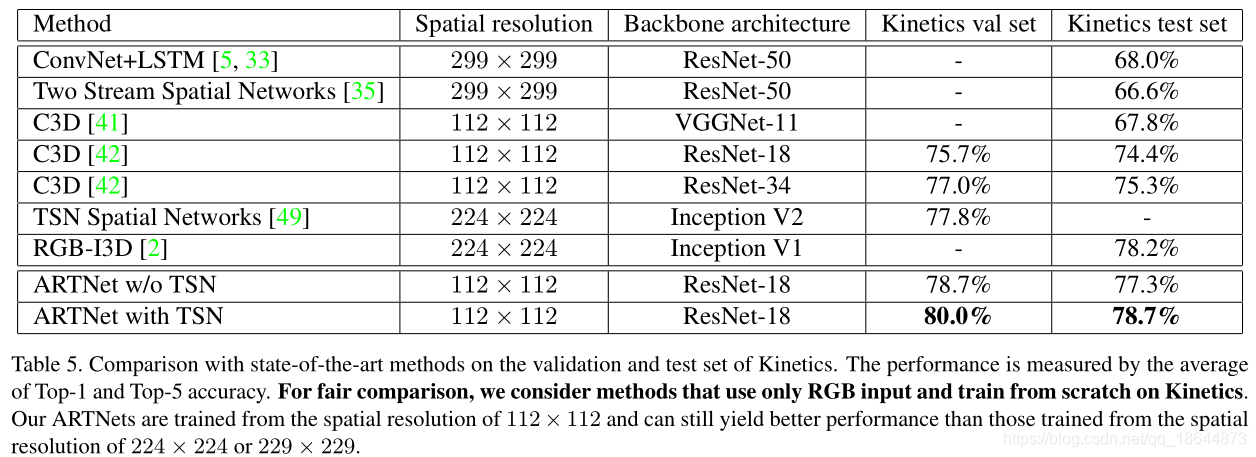
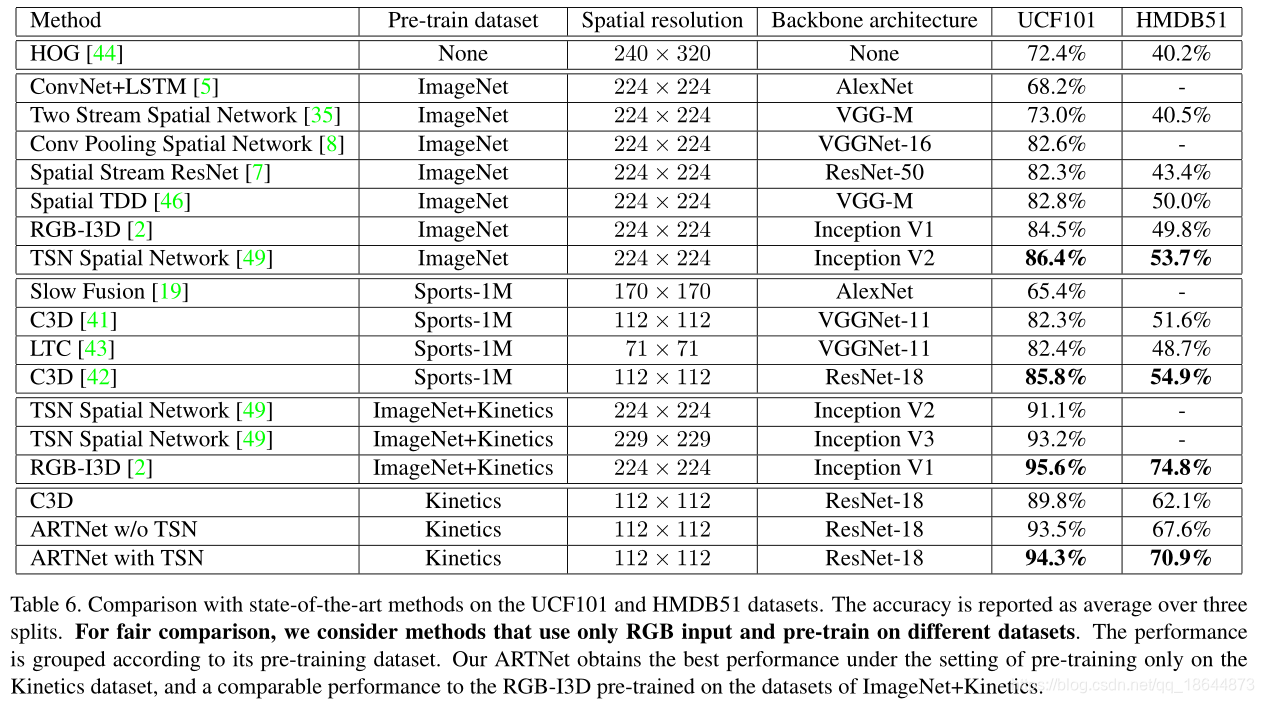
本文提出了ARTNet网络结构,它主要由SMART block通过sstacking的方式组成起来,实现了直接输入RGB视频图像的端到端的视频理解模型。ARTNet是基于C3D-ResNet18实现,训练时采用了TSN的稀疏采样策略。
代码
源码(caffe)
模型
实验
备注
和C3D相比已经有了显著的提升,但是相比于two-stream仍然有差距,为了缩小这种差距,未来尝试更深的网络和更大的分辨率。
Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recognition(2018)
论文
内容
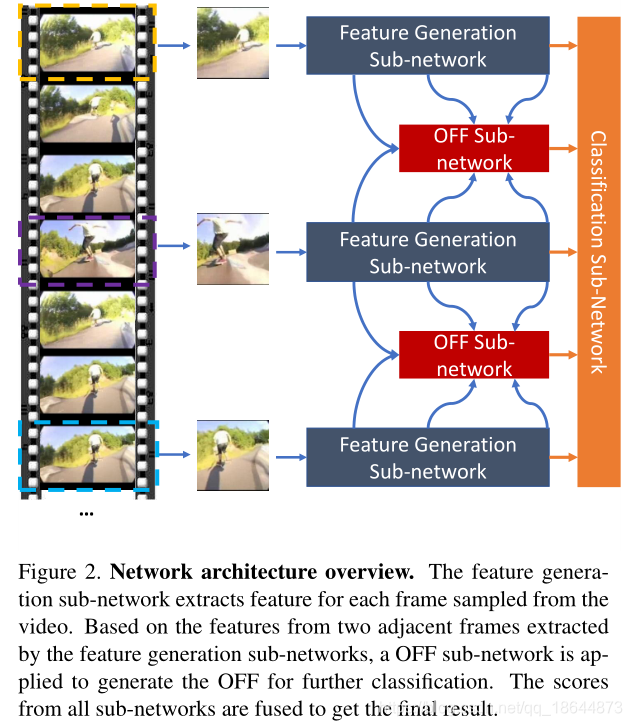
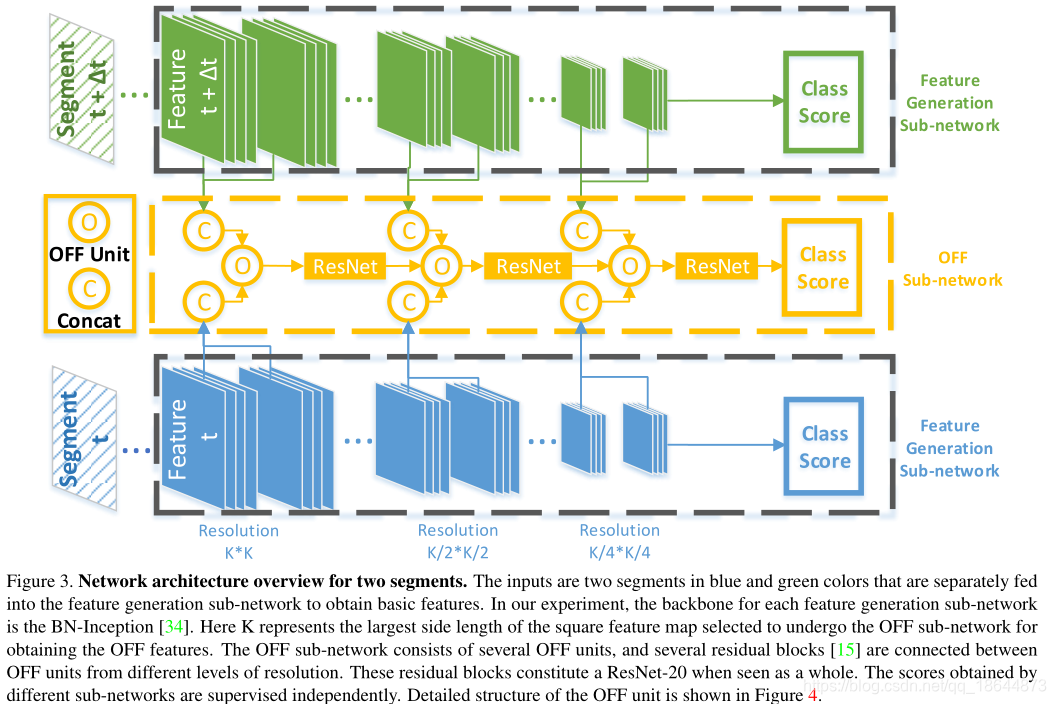
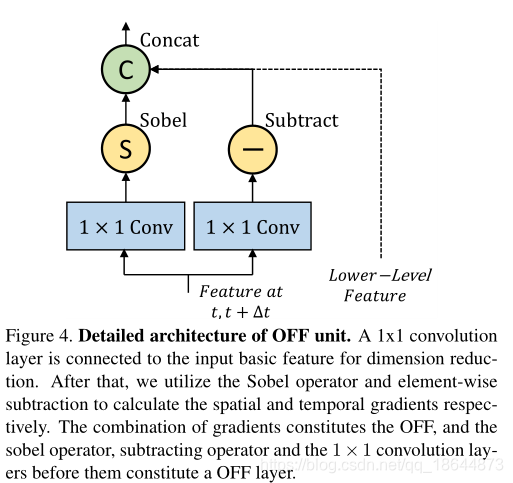
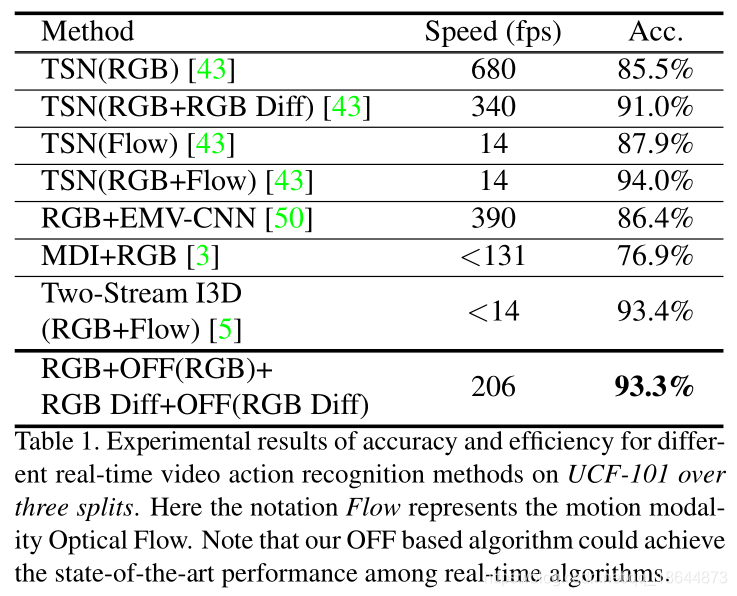
本文提出了一种新的简洁的运动表示,叫做Optical Flow guided Feature (OFF)。OFF通过直接计算,feature map上pixel-wise的时空梯度,使得CNN可以直接从帧计算到temporal information。在UCF101上仅以RGB输入到OFF网络得到的acc达到93.3%,和two stream(RGB+optial flow)的acc相当,并且快15倍。实验也显示OFF还可以和其他motion modalities如传统光流等配合使用,如将OFF插入到two-stream网络中能达到96.0%的acc。
OFF由光流的定义导出,并与光流正交。该特征由水平和垂直方向上的特征图的空间梯度以及从不同帧的特征图之间的差异获得的时间梯度组成,OFF操作是CNN特征上的像素级运算,而且所有操作都是可导的,因此整个过程是可以端到端训练的,而且可以应用到仅有RGB输入的网络中去同时有效提取空间和时间特征。
本文贡献主要在两个方面:
- OFF是一个快速鲁棒的motion representation。当输入只有RGB时,OFF能够达到200fps,且性能和state-of-the-art的光流算法相当。
- OFF可以end-to-end地训练,也就是说在一个网络里面可以同时学到spatial和temporal的特征表达了,不用再像two-stream那么分两个分支来进行了。
代码
源码(caffe)
模型
实验
在这里插入图片描述
备注
1、当仅使用RGB temporal gradient(不使用spatial gradient)时,UCF-101 split1上精度为89.8%,否则为90.5%。时间梯度在提高性能方面起着关键作用。虽然空间部分不那么重要,但它仍然可以为性能提供0.7%的增益。因为CNN本身已经具备从RGB图像中提取梯度信息的能力,空间网络可以从原始RGB帧中明确地捕获这些信息,从而将远离分支的空间分支移除。实验表面,删除时间描述模态的空间分支不会导致性能明显下降,但速度可能会快得多。
{kind=link}
A Closer Look at Spatiotemporal Convolutions for Action Recognition(2018)
R(2+1)D网络 论文
内容
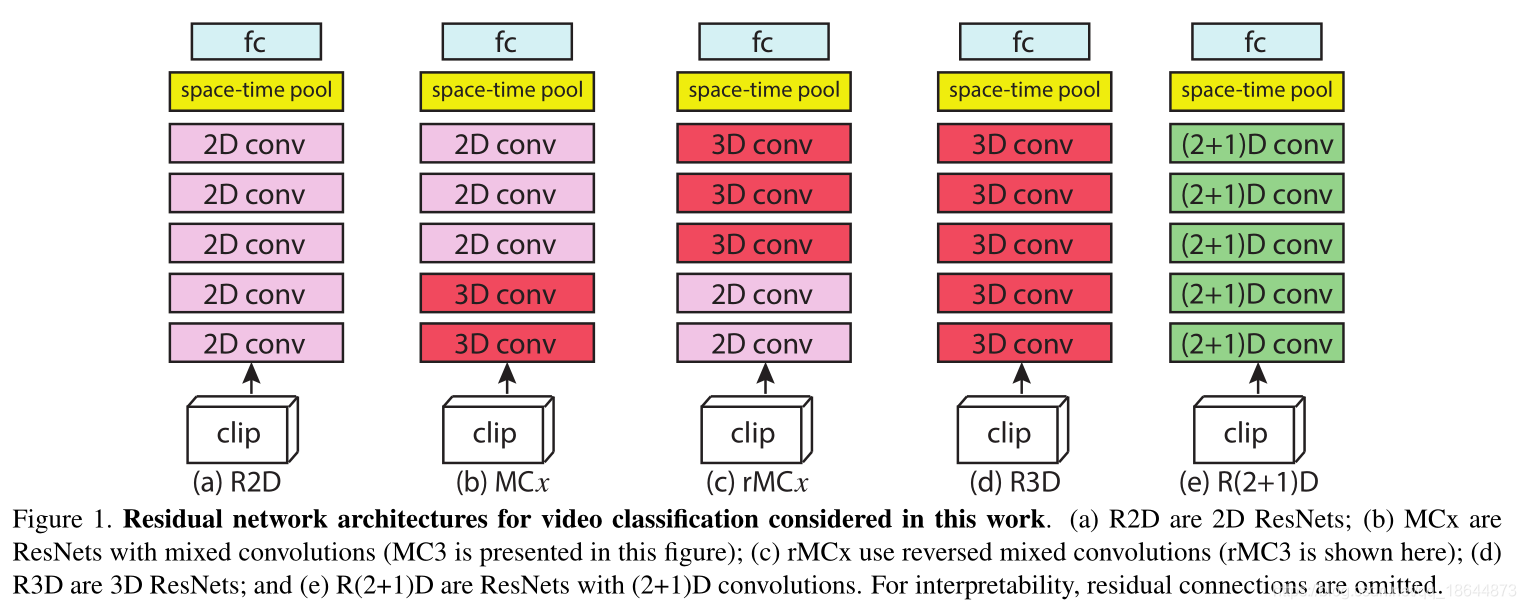
本文利用2D和3D卷积层设计了不同的组合结构来进行视频中时间推理的研究。设计并对比了R2D、MCx、rMCx、R3D和R(2+1)D卷积残差块,其中R(2+1)D网络性能最好。
代码
源码(caffe)
模型
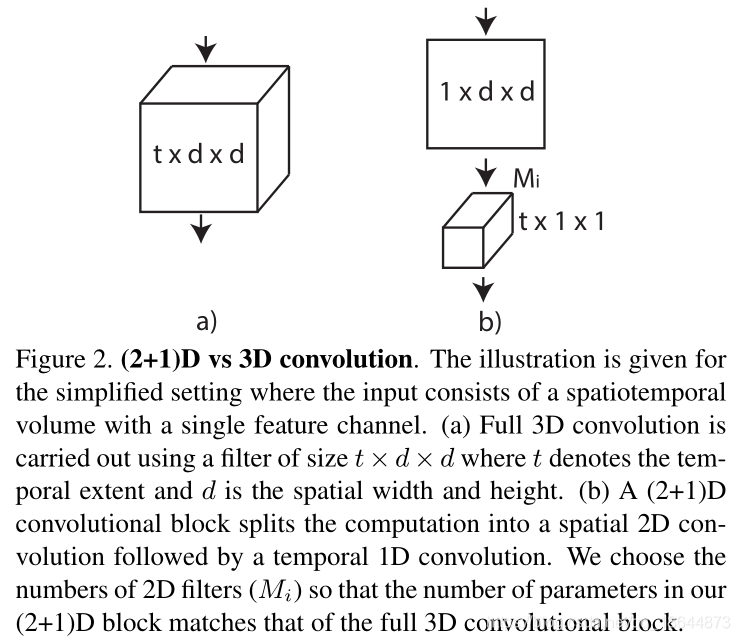
实验
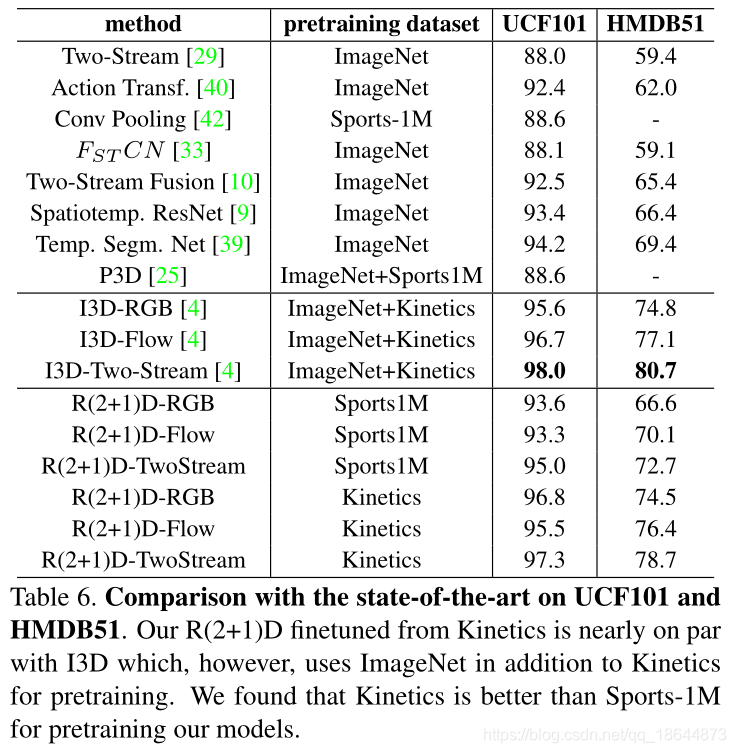
备注
1、R(2+1)D:a)从3D到(2+1)D的拆分增加非线性层数,增加模型的复杂度;b)分解的时空卷积效果要比3维卷积和混合卷积好,更比2维卷积模型效果好;c)随着网络深度增加,R(2+1)D比R3D更容易训练。
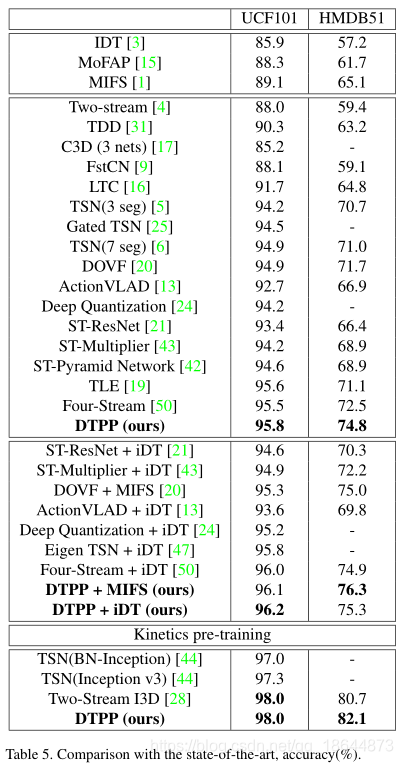
End-to-end Video-level Representation Learning for Action Recognition(2018)
DTPP(Deep networks with Temporal Pyramid Pooling,时间金字塔池深度网络) 论文
内容
基于双流法提出了一种基于时间金字塔池(DTPP)的深层网络,将BN-Inception网络作为DTPP的主干,实现一种端到端视频级别表示学习方法。RGB图像和光流堆栈在整个视频中进行稀疏采样,具体将每个视频分成T段,每段时间相等,然后从每段中抽取一个帧。这些帧被输入到一个ConvNet, ConvNet独立计算每个帧的特征。得到的特征向量是 ,d为帧特征维数。为了将多个帧级特性聚合到视频级表示中,在它们之上放置一个时间金字塔池(TPP)层。然后利用时间金字塔池层来聚集由空间和时间线索组成的帧级特征。最后,该模型具有紧凑的视频级表示,具有多个时间尺度,具有全局和序列感知。通过ImageNet和Kinetics预训练,在UCF-101和HMDB51上达到了state-of-the-art。
代码
源码(caffe)
模型
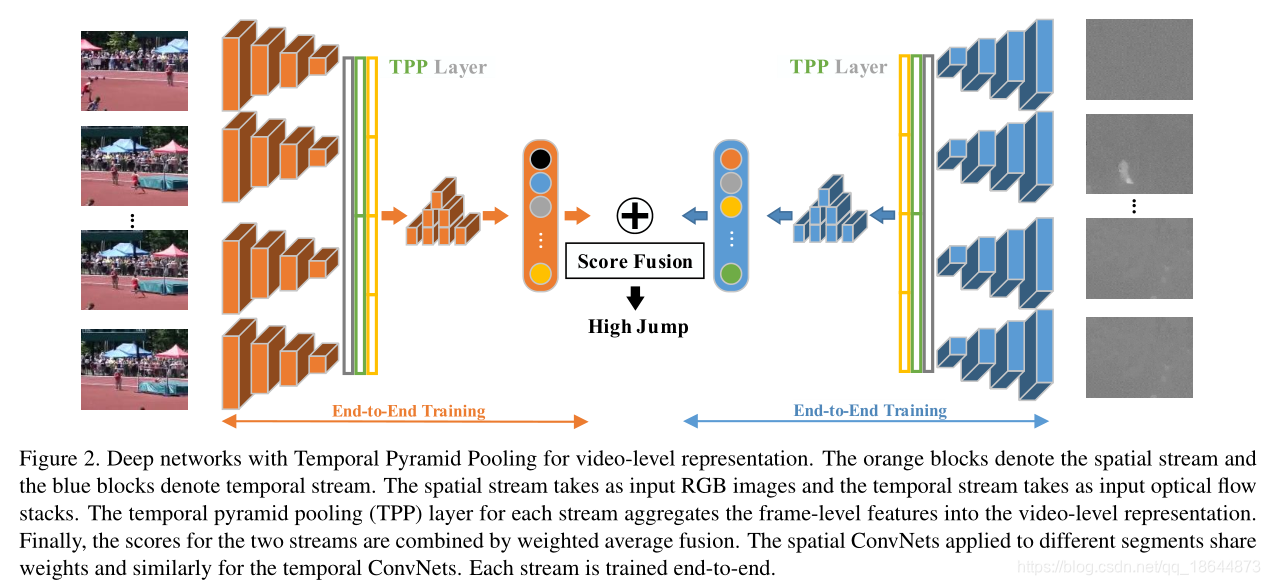
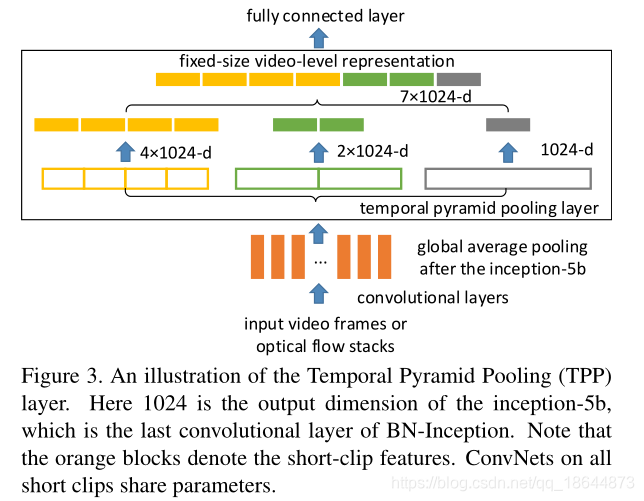
实验
备注1、稀疏采样:视频帧的冗余和内存限制,并不是所有的视频都用来表示视频。
Non-local Neural Networks(2018)
NL block(Non-local,非局部模块) 论文
内容
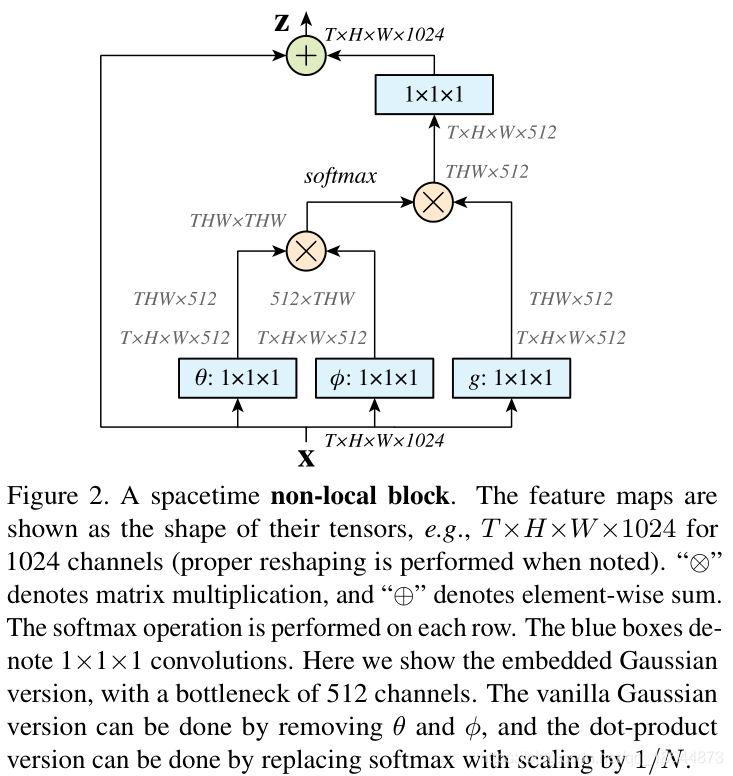
受计算机视觉中的经典非局部均值方法的启发而来,本文提出了一种非局部(non-local block)网络,作为获取长时记忆的、一个简单高效的通用模块,非局部运算将一处位置的响应计算为所有位置的特征的加权和。这个组件可以插入到嵌入现有视觉模型中,实验证明能够帮助深度网络更好地融合非局部的信息,提高图像及视频分类精度,帮助深度网络更好地融合非局部的信息。
NL block : 非局部运算将某一处位置的响应作为输入特征映射中所有位置的特征的加权和来进行计算。这些位置可以是空间位置,也可以是时间位置,还可以是时空位置,这意味着适用于图像、序列和视频问题。 ,有如下总结:
- NL block中f(.)不同的定义方式各有千秋,但是为了更好化可视化使用embedded Gaussian+dot product,即上文提到的公式所示的方法。
- NL block的放入网络主干的位置:放在浅层好,高层提升作用下降。
- NL block变深的作用:对于主干网络较浅的网络,加深NL block能够提升性能。对于较大较深的网络无论是增加NL block还是继续加深主干网络的深度都很难再提升性能。
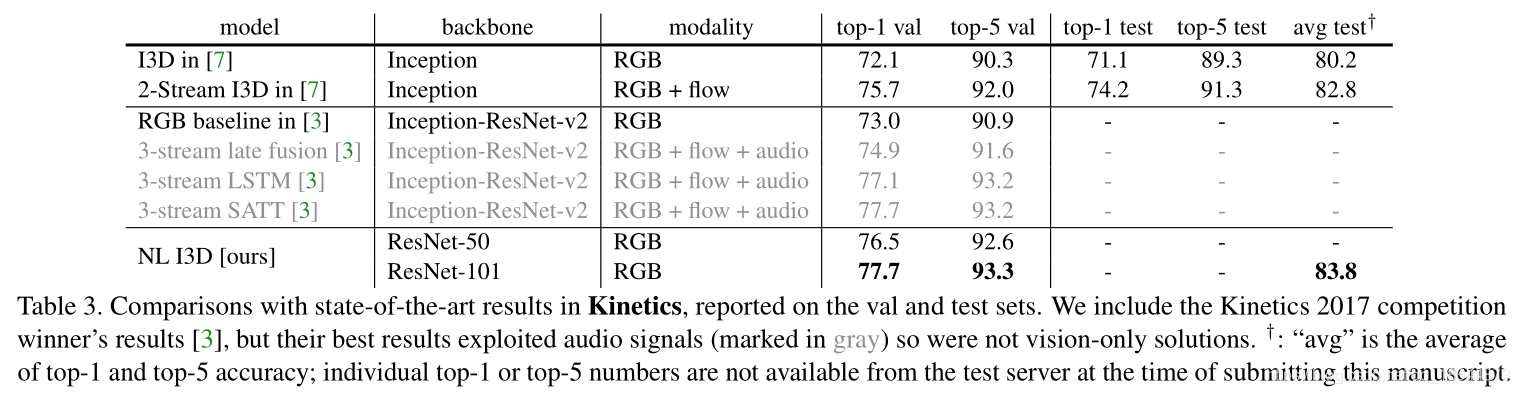
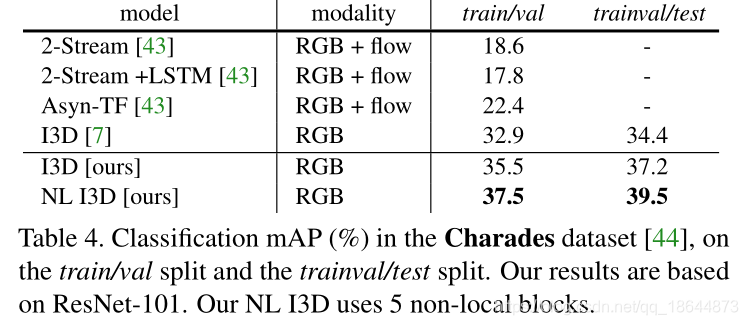
- (对视频任务)NL block同时作用于时空比单独作用于时间域或空间域要好。比二维和三维卷积网络在视频分类中取得更准确的结果,在计算上也比三位网络更经济,在 Kinetics 和 Charades 数据集上做了全面的对比研究。本文仅使用 RGB 数据,不使用任何高级处理(例如光流、多尺度测试),就取得了与这两个数据集上竞赛冠军方法相当乃至更好的结果。
优点:
- 与递归和卷积运算的渐进的操作相比,非本局部运算直接通过计算任意两个位置之间的交互来获取长时记忆,可以不用管其间的距离;
- 非局部运算效率很高,即使只有几层(比如实验中的5层)也能达到最好的效果;
- 非局部运算能够维持可变输入的大小,并且能很方便地与其他运算相组合。
代码
源码(caffe2)
模型
实验
备注
Compressed Video Action Recognition(2018)
压缩视频训练 论文
内容
原始视频视频数据具有巨大的数据量和高时间冗余,真正有用的信号经常被淹没在太多不相关的数据中。由于视频压缩(H.264、HEVC等),多余的信息可以减少多达两个数量级,因此本文提出直接在压缩视频上训练深层网络。这种表示具有更高的信息密度,实验证明训练更容易。另外,压缩视频中的信号提供直接的但包含很大噪声的运动信息。本文提出新的技术来有效的利用它们。提出的方法比 Res3D 快 4.6 倍,比 ResNet-152 快 2.7 倍。 在动作识别的任务上,本文的方法优于 UCF-101、HMDB-51 和 Charades 数据集上对应的其它方法。
大多数现代编解码器将视频分成I帧(内编码帧),P帧(预测帧)和零个或多个B帧(双向帧)。I帧是常规图像并且被压缩。P帧引用前面的帧并仅编码相对前一帧所需要的‘变化’。B帧可以被视为特殊的P帧,其中运动向量是双向计算的,并且只要在参考中没有循环就可以引用未来帧。
代码
未公开
模型
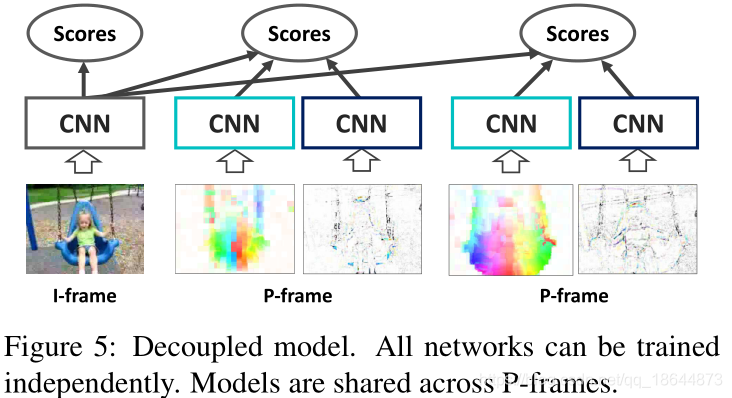
实验
备注
A(2018)
论文
内容
代码
模型
实验
备注