版权声明:本文为神州灵云作者的原创文章,未经神州灵云允许不得转载。
本文作者:Bruce
引子
最近,笔者所在公司 - 神州灵云的专家拜访一知名政企客户时,专家详细介绍了公司酷毙的一体化性能管理解决方案(从网络和应用端同时采集监控),客户挑衅地说:“我们这边有个真实的应用性能问题,如果你们能解决,才是真正的酷!”
以往都是Presentation+Demo就可以,这次要来真格的,专家虽然有些意外,但自信满满的说:“来吧 ,还就怕你没问题 ”。
故障描述
原来客户有个Coding应用,使用者从互联网访问,不断吐槽、投诉不断(再不解决就不用了)很多交易的响应时间超过了500 毫秒,SLA承诺是300 毫秒以内,这差距也太大了吧。因为网络设备和节点繁多,排障初期并不能确定故障点,客户花费了大量时间在防火墙和Nginx 策略优化上,但是依然不见成效。
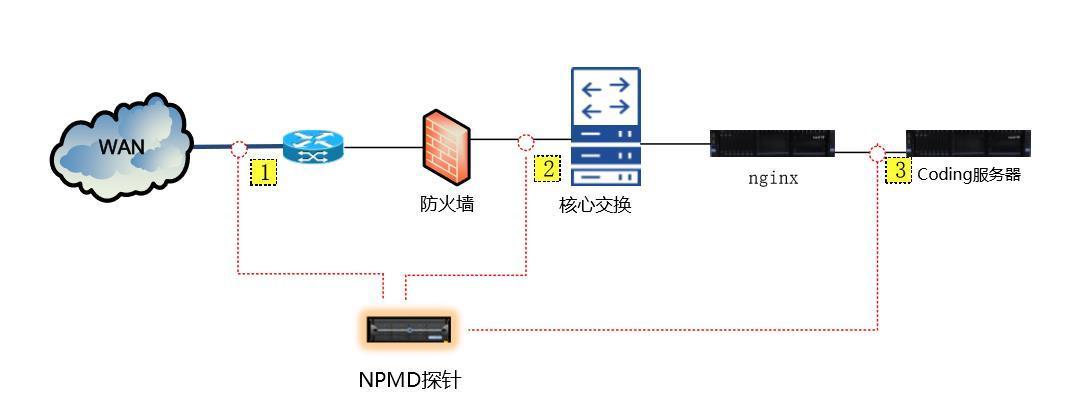
了解到这个情况,专家心里有谱了:“没事,先上我们的故障定位系统NPM”,部署架构是这样的:
图中数字1 - 代表外联区,2 - 代表 核心交换区 3 - 代表应用服务区
定位问题
-
外联区:在12 月4 日通过网络性能管理与诊断平台在外联区采集到的coding 业务交易相关的URL 来看,响应时间都在1 秒以上,远远超出了客户的预定延时。
-
核心交换区:发现同样的业务访问,响应时间也是1秒也上。
扫描二维码关注公众号,回复: 5464074 查看本文章
-
应用服务区:在硬件Nginx 和应用服务器之间进行采集数据包分析诊断,发现业务流的响应时间仍然维持在1秒左右,最终可以确定问题是出现在应用服务器。

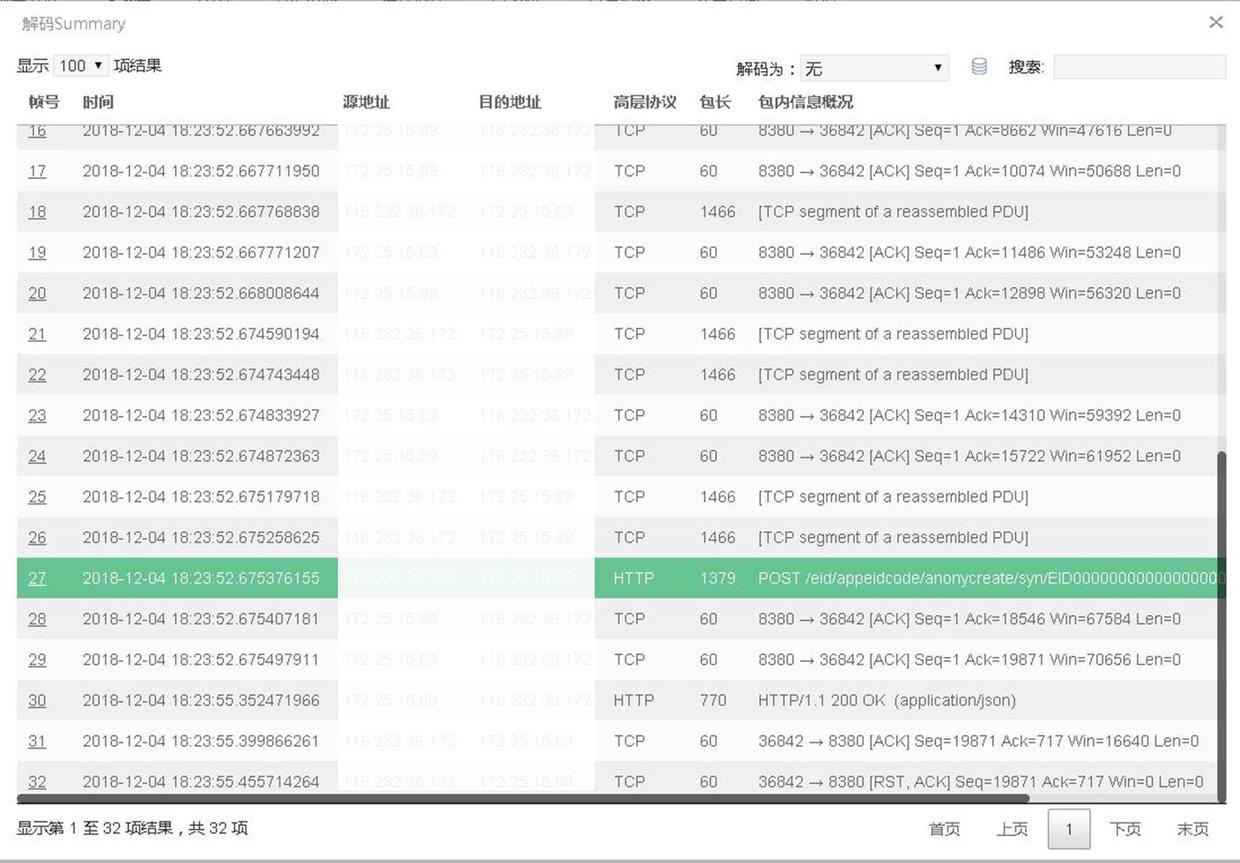
结论:应用服务器服务所消耗的时间就是很慢。
至此,神州灵云专家向客户展示了分析过程和结果,告诉客户重点解决应用服务器不能快速响应的问题。
客户:“你们只是定位了到了服务器,没有告诉我服务器的哪里有问题?以及如何解决?不算”。
“应用的排障和优化难道不是应用开发商的事情吗?”专家问道!
客户说:“你们既然是端到端一体化性能故障分析解决方案就别客气了,应用开发商也不一定靠得住”
神州灵云专家笑道:“多亏我还留了后手,该APM故障解决器登场了”。那就让神州灵云的故障解决专家系统上线吧。
故障解决专家系统APM
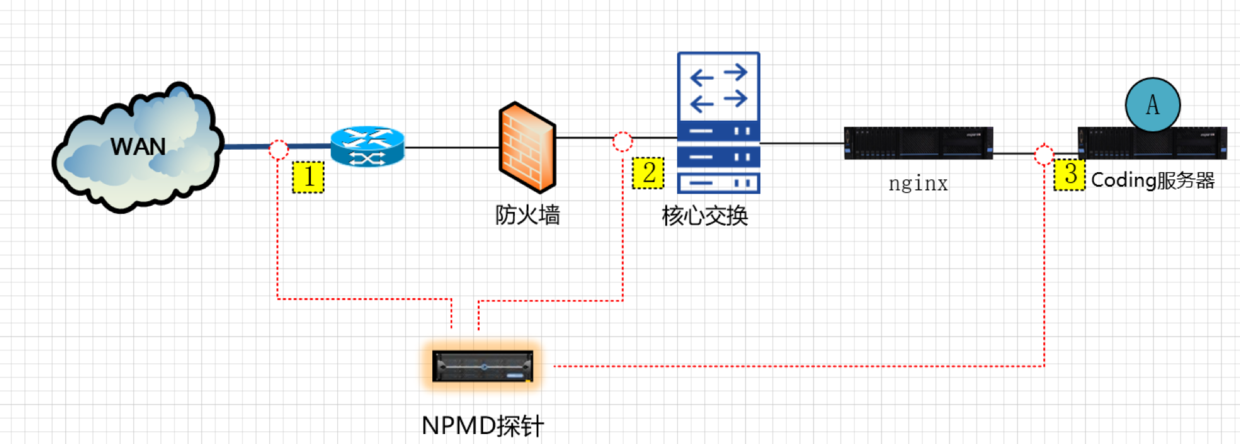
一体化故障定位解决部署架构图,A是故障解决专家系统
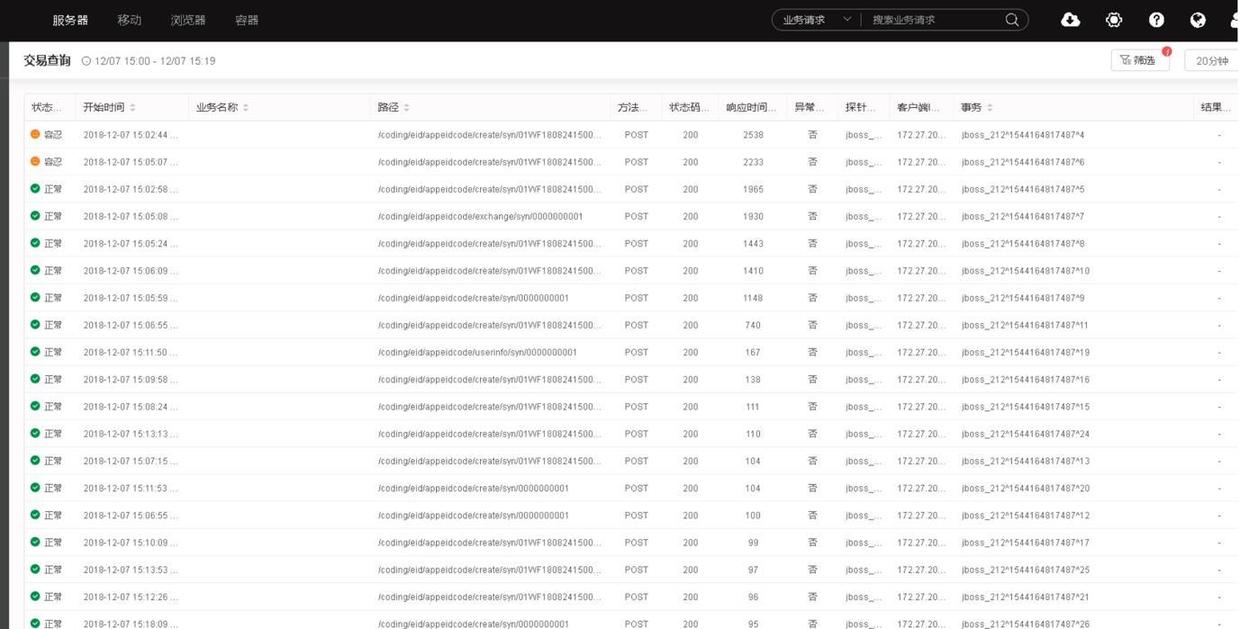
安装故障专家系统的监听器在Coding服务器上。在交易查询页面中可以看到有相当一部分交易响应时间都在1 秒甚至2 秒以上,再次证明是应用服务器的问题才导致的过大延时。
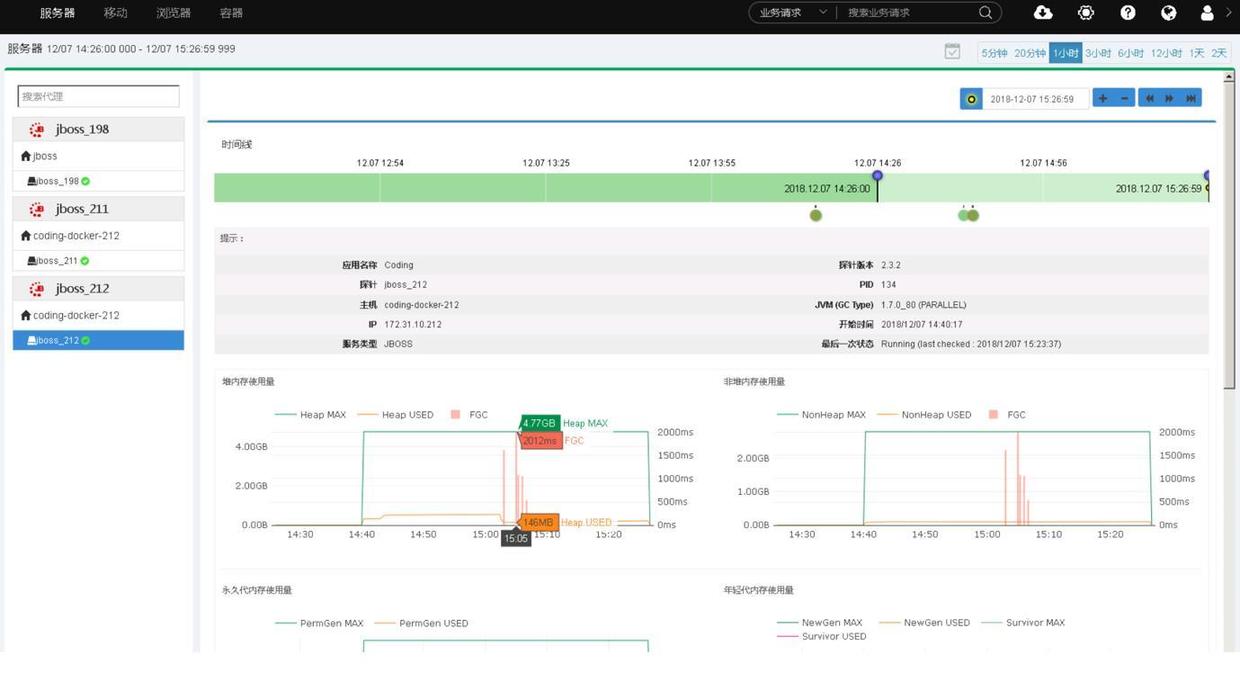
对比发现,凡是响应时间过大的交易的时间点上,均触发了Java的垃圾回收(FGC)机制,频繁地触发FGC,每次FGC消耗2秒,在这个2秒时间里面,服务器“停止”响应外部的所有请求。
定位内存配置问题
永久带内存分配不合理 一共才5G 内存,分配给了永久代2.5G,导致别的内存区严重不够用,Java进程就不断的回收内存,导致系统变慢。
解决问题
将Java启动参数的永久代内存调整为300M后,应用系统恢复正常,大部分业务请求都在300毫秒以内完成。至此大功告成
用户看了结果和分析后只挑大拇指:“神州灵云的一体化故障定位解决方案真不是吹的,经得住实战,是运维的好帮手!”
