一、reduce
Reduces the elements of this RDD using the specified commutative and associative binary operator. Currently reduces partitions locally.
a=sc.parallelize([1,2,3,4,5],2).reduce(add)
print(a)
a=sc.parallelize((2 for _ in range(10))).map(lambda x:1).cache().reduce(add)
print(a)
二、reduceByKey(func, numPartitions=None, partitionFunc=)
Merge the values for each key using an associative and commutative reduce function.
This will also perform the merging locally on each mapper before sending results to a reducer, similarly to a “combiner” in MapReduce.
Output will be partitioned with numPartitions partitions, or the default parallelism level if numPartitions is not specified. Default partitioner is hash-partition.
按照k值操作V值,返回k-v列表
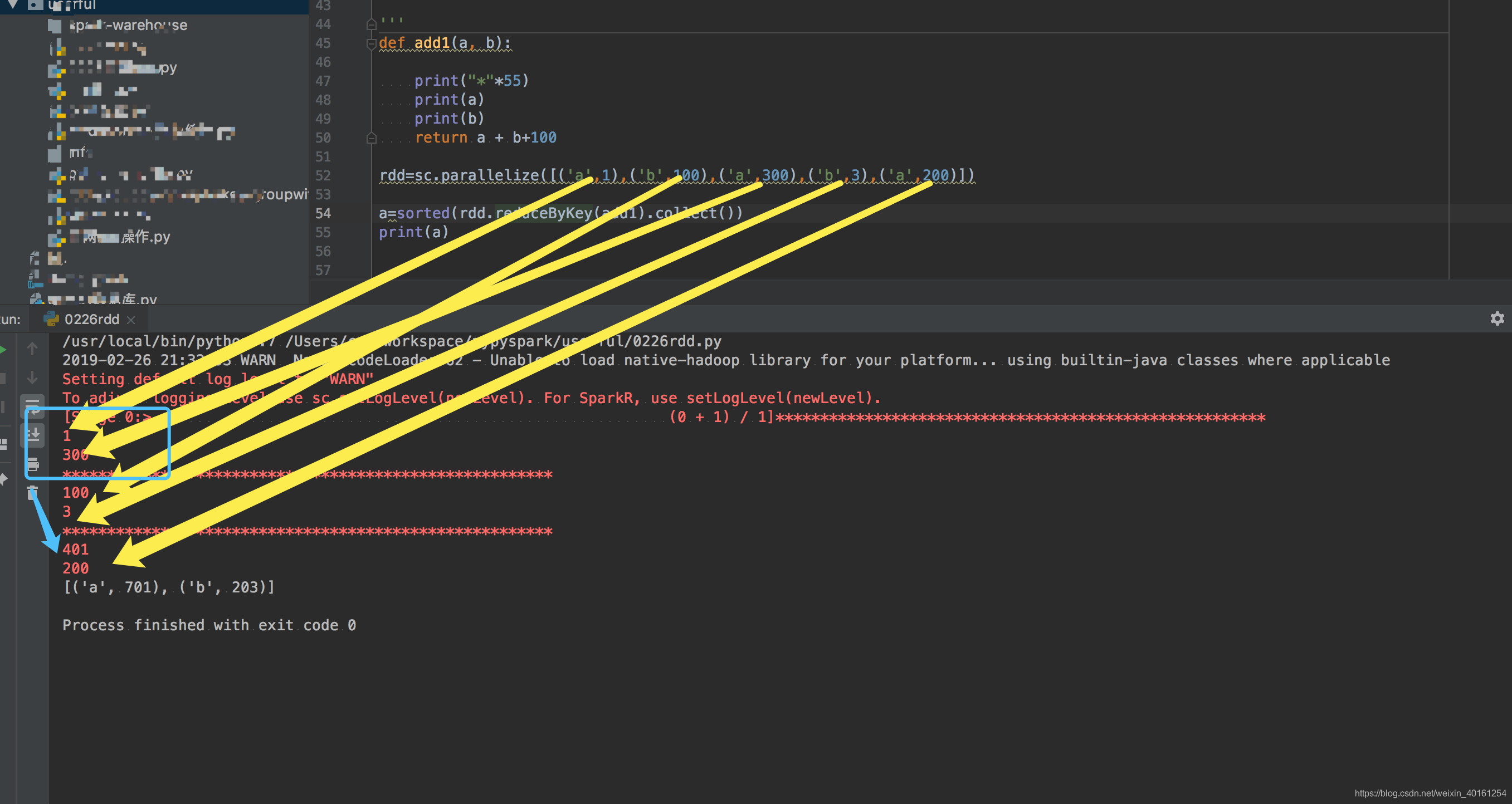
def add1(a, b):
print("*"*55)
print(a)
print(b)
return a + b+100
rdd=sc.parallelize([('a',1),('b',100),('a',300),('b',3),('a',200)])
a=sorted(rdd.reduceByKey(add1).collect())
print(a)
三、reduceByKeyLocally(func)
Merge the values for each key using an associative and commutative reduce function, but return the results immediately to the master as a dictionary.
同reduceByKey,但是返回一个字典
def add1(a, b):
print("*"*55)
print(a)
print(b)
return a + b
rdd=sc.parallelize([('a',1),('b',100),('a',300),('b',3),('a',200)])
a=rdd.reduceByKeyLocally(add1)
print("%"*33)
print(a)
print(type(a))
print(a.items())
print(sorted(a.items()))
