第二节:马尔科夫决策过程(Markov Decision Process)
1.引入马尔科夫决策过程MDP
如前所述,强化学习是解决与决策相关问题的模型,这也是从我们的生活经验中总结出来的。在现实生活中,如果我们做某件事获得奖励,那么我们会更加倾向于做这件事。比如家里的宠物狗早上把鞋子给我们叼过来,我们对它说good dog, 并奖励它好吃的食物,那么宠物狗会更加倾向于叼鞋。
从强化学习的基本原理能看出它与其他机器学习算法如监督学习和非监督学习的一些基本差别。在监督学习和非监督学习中,数据是静态的、不需要与环境进行交互的,比如图像识别,只要给出足够的差异样本,将数据输入深度网络中进行训练即可。然而强化学习过程是动态的、不断交互的过程,所需要的数据也是通过与环境不断交互产生的。所以与监督学习相比,强化学习的对象更多,比如动作,环境,状态转移概率和回报函数等。强化学习更像是人的学习过程:人类通过与周围环境进行交互,学会了走路,奔跑,劳动;人类与大自然,与宇宙的交互创造了现代文明。另外,深度学习如图像识别和语音识别解决的事感知的问题,强化学习解决的是决策的问题。人工智能的终极目标是通过感知进行智能决策。无数的先贤大牛们通过不断的创新探索,总结出一套可以解决大部分强化学习问题的框架——马尔科夫决策过程,即MDP。MDP能用数学方法来描述和解决强化学习相关问题。
2.马尔科夫性
要想了解马尔科夫决策过程首先要明白的一个概念就是马尔科夫性。所谓马尔科夫性是指系统的下一个状态St+1 仅与当前的状态St有关,而与以前的状态无关。
定义:当且仅当P[st+1 | st] = P[st+1| s1, …, st], 我们称状态St是马尔科夫的,或者说状态St具有马尔科夫性。从定义中可以看出,当前状态St其实蕴含了所有相关的历史信息S1, S2, …, St, 一旦当前状态已知,历史信息将会被摒弃。
马尔科夫性描述的是每个状态的性质,但真正有用的是如何描述一个状态序列。数学中用来描述随机变量序列的学科叫随机过程。所谓随机过程就是指随机变量序列。若随机变量序列中的每个状态都是马尔科夫的,则称此随机过程为马尔科夫随机过程。
3.马尔科夫过程
马尔科夫过程的定义:马尔科夫过程是一个二元组(S, P), 且满足:S是有限状态集合,P是状态转移概率。状态转移概率矩阵为:P =
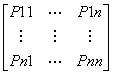 。
。

Figure 2-1 马尔科夫过程示例图
如图2-1所示为一个学生的7种状态{娱乐,课程1,课程2,课程3,考过,睡觉,论文},每种状态之间的转换概率如图2-1所示:
则该名学生从课程1开始的状态序列为:
课程1—》课程2–》睡觉
课程1–》课程2–》课程3–》考过–》睡觉
上面的状态序列称为马尔科夫链。当给定状态转移概率时,从某个状态出发存在多条马尔科夫链。然而马尔科夫过程不足以描述强化学习过程,因为在强化学习中需要智能体与环境进行交互,并从环境中获得奖励,而马尔科夫过程中不存在动作和奖励。由此又引出马尔科夫决策过程:将动作(策略)和回报考虑在内的马尔科夫过程。
4.马尔科夫决策过程
1)马尔科夫决策要求:
1.能够检测到理想的状态
2.可以多次尝试
3.系统的下个状态只与当前状态信息有关,而与更早之前的状态无关,在决策过程中还和当前采取的动作有关
2)马尔科夫决策过程由元组(S, A, P, R, )描述,其中:
S 为有限的状态集(States)
A 为有限的动作集(Actions)
P 为状态转移概率(p(s2|s1, a)), 在状态s1下执行动作a, 转移到s2的概率记为Psa
R 为回报函数,Agent采取某个动作之后的即时奖励
为折扣系数,用来计算累积回报
3)决策过程
1.智能体处于初始状态S0
2.智能体选择一个动作a0
3.按概率转移矩阵Psa转移到下一个状态S1
4.重复上述过程,直到达到最终状态
跟马尔科夫过程不同的是,马尔科夫决策过程的状态转移概率时包含动作的,即 Pas= P[St+1 = s | St = s, At = a]

Figure2 - 2马尔科夫决策过程示例图
如上图所示,学生有五个状态,状态集为S = {S1, S2,S3, S4, S5}, 动作集为A={玩, 退出,学习,发表,睡觉},回报用R表示。强化学习的目标是给定一个马尔科夫决策过程,寻找最优策略。策略是指状态到状态的映射,策略通常是用表示,它是指给定状态s时,动作集的分布,(a|s) = p[At=a | St=s]。上述算式是用条件概率给出的。
当一个策略给定时,我们就可以计算累积回报了,其定义为:
Gt = Rt+1 + Rt+2 + … =
当给定策略时,假设从状态S1出发,学生的状态序列可能为:
S1—>S2—>S3—>S4—>S5
S1—>S4—>S3
…
此时在策略下 可以计算累积回报G1, 有多个可能值。(划重点:这里的说的策略是指从初始状态到结束状态的一组策略)。由于策略是随机的,因此累积回报也是随机的。为了评价状态S1的价值(状态S1是好还是坏,多好多坏),可以用累积回报的期望定义状态值函数。
Figure2-3状态值函数示意图
4)状态值函数和状态行为值函数
价值函数用来衡量某一状态或者状态-动作对的优劣,累计奖励的期望。
当智能体采用策略时,累积回报服从一个分布,累积回报在s处的期望值定义为状态值函数:
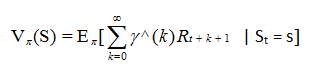
图2-3是图2-2相对应的状态值函数图。图中空心圆圈中的数值为该状态下的值函数。V(S1) = -2.3, V(S2) = -1.3, V(S3) = 2.7, V(S4) = 7.4, V(S5) = 0
相应的状态行为值函数为:
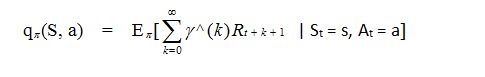
5)贝尔曼(Bellman)方程
贝尔曼方程表示当前状态的价值和下一步的价值以及当前的奖励(Reward)有关.即价值函数分解为两部分:当前即时奖励,下一步的价值。
v(S) =
举个例子,上图2-3中值为7.4的回报计算:
该状态下有两个可能的动作,睡觉和发表论文。这里默认两个动作是等可能发生的。
且选择睡觉之后没有别的可能动作了。
根据上式:
1.选择睡觉的回报 :v1 = 0.5 * (10 + 0) = 5, 0.5表示该状态下选择睡觉的概率,10表示选择睡觉的立即奖励,由于选择了睡觉之后就没有别的可能选择了(如图所示),所以未来回报为零。
2.选择发表论文的回报:v2 = 0.5 * (1 + 未来回报) = 2.4,未来回报=0.2 * (-1.3)+ 0.4 * 2.7 + 0.4 * 7.4 , 原因是选择发表论文之后还有三个可能的动作,选择这三个动作的概率分别为0.2, 0.4, 0.4。这里没有加折扣系数。
3.V(s) = v1 + v2 = 7.4
计算状态值函数的目的是为了构建学习算法从数据中得到最优策略,每个策略对应着一个状态值函数,最优策略自然对应着最优状态值函数。最优状态值函数为在所有 策略中值最大的值函数,即v*(s) = max V(s)。最优状态-行为值函数q*(s, a) 为在所有策略中最大的状态-行为值函数,即 q*(s, a) = max q(s, a)。 假如已知q*(s, a),最优策略就可以通过最大化q*(s, a) 来决定。