首先,在电脑上安装jieba库,进入命令提示符,输入pip install jieba,接下来就等系统自动安装
然后再进入IDLE建立一个脚本,用open函数打开只读模式,用jieba.lcut函数剪下词组,对每一个剪下的词组进行统计,最后输出。
import jieba txt = open("D:\清道夫.txt","r",encoding='utf-8').read() words = jieba.lcut(txt) counts = {} for word in words: if len(word) == 1: continue else: counts[word] = counts.get(word,0) + 1 items = list(counts.items()) items.sort(key=lambda x:x[1], reverse=True) for i in range(10): word, count = items[i] print ("{0:<10}{1:>5}".format(word, count))
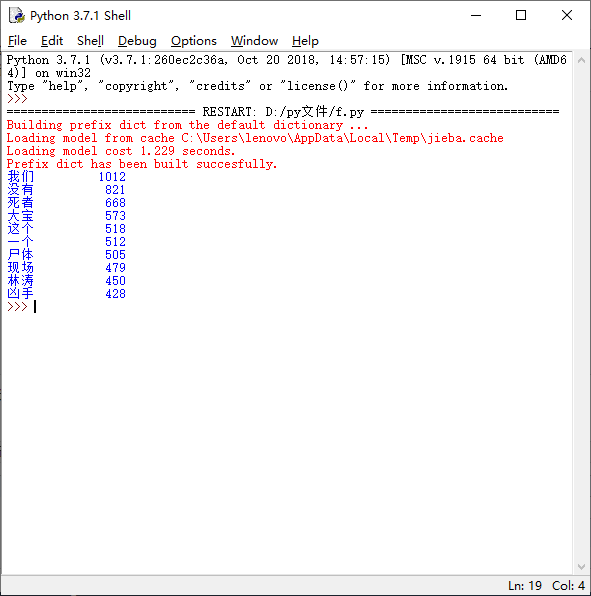
运行结果如下