keras基础实例
电影评价预测
导入数据集
import keras
from keras import layers
import matplotlib.pyplot as plt
%matplotlib inline
data = keras.datasets.imdb
max_word = 10000
# 加载前10000个单词 最大不超过10000
(x_train, y_train), (x_test, y_test) = data.load_data(num_words=max_word)
查看数据
x_train.shape, y_train.shape
OUT:
((25000,), (25000,))
x_train[0]
y_train[0]
OUT:
输出的是
词汇的index
输出的是
array([1, 0, 0, ..., 0, 1, 0], dtype=int64)
1 代表 正面评价 0 代表负面怕评价
加载index和词汇的对应关系
#加载词汇
word_index = data.get_word_index()
#将index和value 互换
index_word = dict((value, key) for key,value in word_index.items())
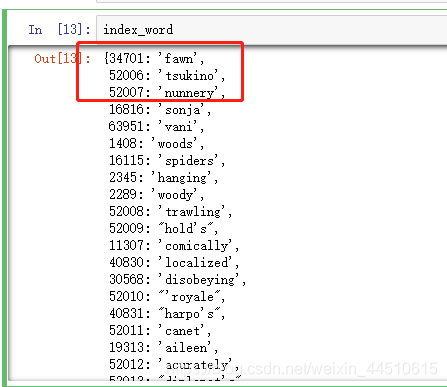
打印第一个评论
# 在index_word中前三个不是需要的单词 ,去除
[index_word.get(index-3, '?') for index in x_train[0]]
OUT:
['?','this','film','was','just','brilliant','casting','location','scenery','story','direction',"everyone's", 'really', ……]
查看数据的长度
[len(seq) for seq in x_train]
max([max(seq) for seq in x_train])
OUT:
[218,189,141,550,147,……] #每条评论的单词量为这么多
9999
果然最长的不超过10000
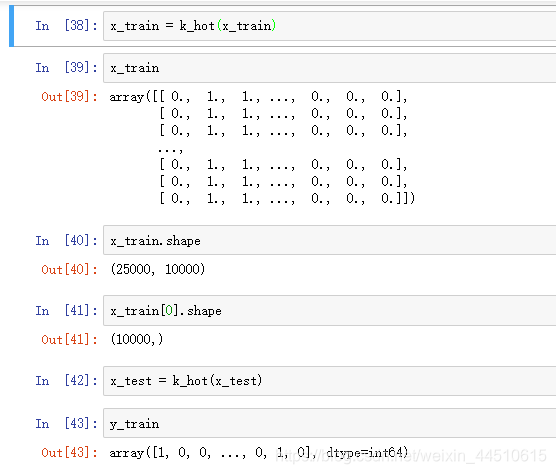
文本的向量化
# 将x_train 中的25000条评论 25000*10000的矩阵
# 该词出现为1 ,不出现为0
def k_hot(seqs, dim=10000):
result = np.zeros((len(seqs), dim))
for i, seq in enumerate(seqs):
result[i, seq] = 1
return result
x_train = k_hot(x_train)
可以看下x_train 和y_train 数据
模型的训练
model = keras.Sequential()
model.add(layers.Dense(32, input_dim=10000, activation='relu'))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['acc']
)
history = model.fit(x_train, y_train, epochs=15, batch_size=256, validation_data=(x_test, y_test))
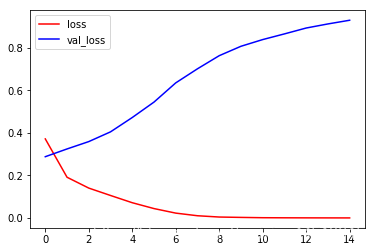
plt.plot(history.epoch, history.history.get('loss'), c='r', label='loss')
plt.plot(history.epoch, history.history.get('val_loss'), c='b', label='val_loss')
plt.legend()
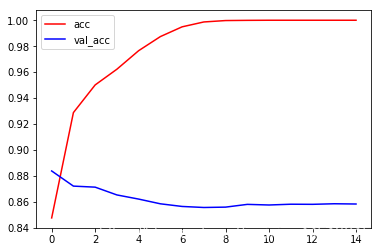
plt.plot(history.epoch, history.history.get('acc'), c='r', label='acc')
plt.plot(history.epoch, history.history.get('val_acc'), c='b', label='val_acc')
plt.legend()
强烈推荐