本章书将大部分内容放在了代码上,原理介绍只是一笔带过。但我在似懂非懂地看完原理部分,再看代码时却看得一脸问号。强行记忆也可以,但我觉得没必要,于是上网找了很多介绍svm原理的文章,以下为看完后对算法原理推导的梳理。
当二维平面上有两堆数据时,我们可以画一条直线,将它分为两部分。这条直线可以平行移动,其极限位置为与第一次与数据相交时的两条直线,这两个极限位置间的距离我们称之为间隔。我们可能可以画出很多条这样的直线,但其中一或多条直线具有最大的间隔,因为这样的直线容纳新数据点的能力最强,所以我们称其为最优解。因为这条直线的划分只与与其极限直线相交的数据点相关,因此我们将这两个数据点称为支持向量。
1)决策面方程
对二维平面,直线方程可写为:y=ax + b。进行简单的变化后为ax - y + b = 0,即[a,-1][x,y] + b = 0,即wt * x + b = 0。w即为直线y的法向量。推广到n维,w = [w1,w2…wn] ,x = [x1,x2…xn]。
2)分类间隔方程
我们知道,对 y = ax +b,如果要求其点到直线的距离,有以下公式:
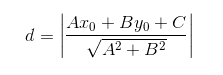
那么拓展到n维,则有:
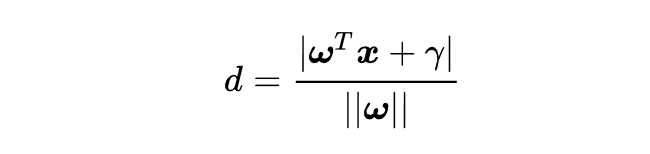
3)约束条件
对二分类问题我们定义类别标签yi,并令y1=1,y2=-1.那么对成功分类的样本点,有:
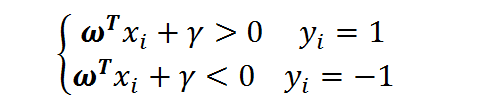
若设决策面恰好在间隔的中轴线,且支持向量到其的距离为d,则有:
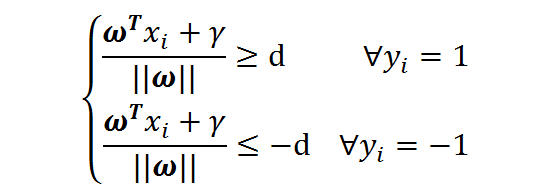
这个公式可以两边同除以d,并用新的w,x向量,可得到:
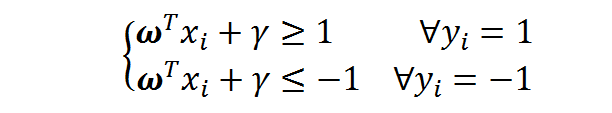
为了方便我们记为:
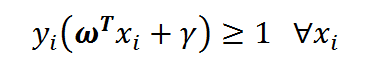
4)线性SVM优化问题基本描述
我们之前得到:

之前提到,只有支持向量对分类有用,而对于支持向量而言,

因此,问题化简为:

求d的最大值问题,就变为求W的最小值问题,这个问题又等效于
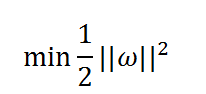
这里用平方表示是为了不影响求导,且不影响单调性。
这里有个约束条件:
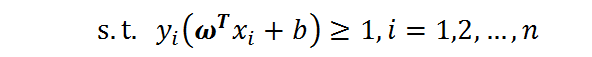
为了求最值,我们构造拉格朗日函数:
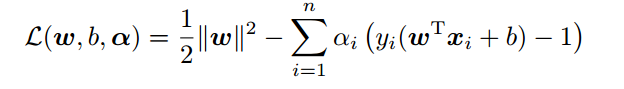
其中ai为拉格朗日乘子,其值大于等于0。
然后我们构造一个新函数:
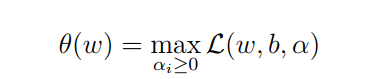
当
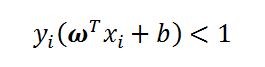
时,样本点不符合约束条件,即x在可行解区域外,该函数为正无穷。
当
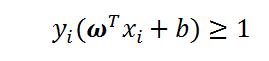
时,样本点在可行解区域内,此时该函数等同于
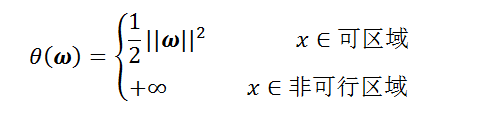
也就是说该函数与原函数是等价的。
所以求原函数的最小值,等同于求该函数的最小值:
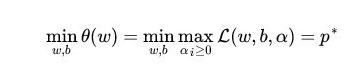
但是这一函数的最小值比较难求,为了更方便地进行计算,我们将min和max的顺序对换:
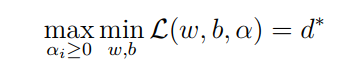
但进行这一对换需要满足两个条件:问题为凸优化问题且符合kkt条件。
5)对偶问题求解
接下来我们对原问题的对偶问题进行求解。我们先考虑内部最小值。首先令a为定值,分别对w和b求导,并令其导数为0,解得:

结果代回原式:
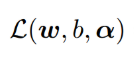
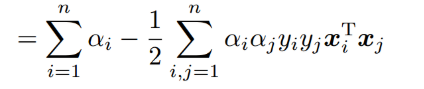
接下来我们求外侧最大值,整体问题描述为:

6)SMO算法
实际上,我们上面的推导隐含了一个假设,即数据是百分百可分的,然而在实际问题中,我们有时会遇到一些不这么完美的数据。为了处理这样的数据,我们引入松弛变量和惩罚参数C,来允许错误的分类点。
此时的约束条件和目标函数为:
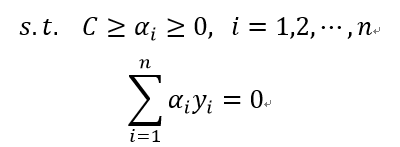
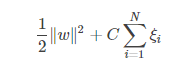
对应的拉格朗日函数变为:
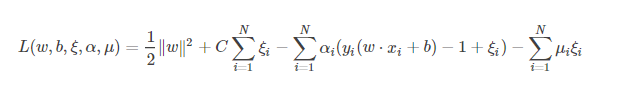
等价于:
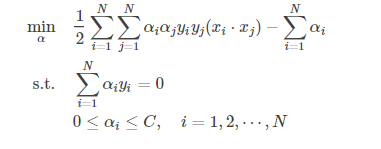
由于约束条件
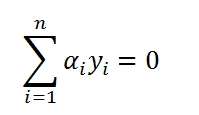
我们必须成对地改变ai,设我们改变的ai为a1和a2,则:

由于同时求两个未知数较难,所以我们可以先求其中一个,再用求出来的值表示另一个。
我们以先求a2为例:
欲求a2的值,我们需要先求出a2的取值范围,设其为L≤a2≤H。那么当y1≠y2时,有:
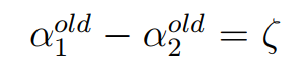
即

此时

同理当y1=y2时,有:
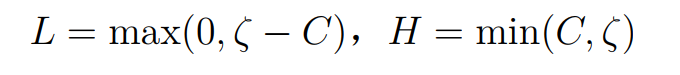
当确定了a2的边界时,我们就可以进行函数推导了:

这里将a1和a2分离开,因为其它a值在求导时都为0,所以可以视作常数。
因为
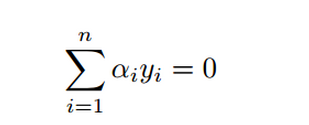
可得a1y1 + a2y2 = B
两边同乘y1得:

带入原式得:
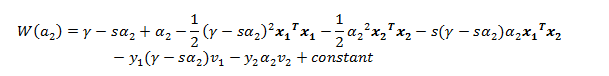
此时该函数是一个关于a2的一元函数,我们对其求导并令导数为0,推得:
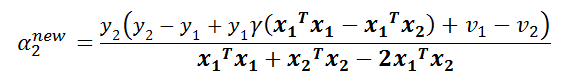
令
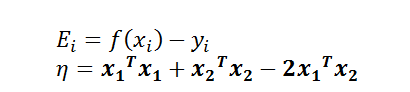
其中Ei为误差项,n为学习效率,

再由
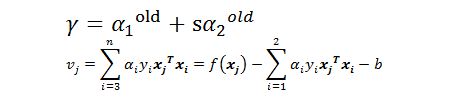
推出
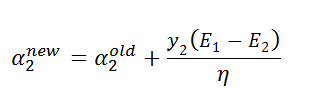
由之前推出的a2的取值范围,我们加上约束条件:
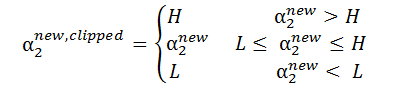
又:
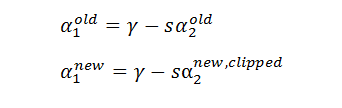
推出:
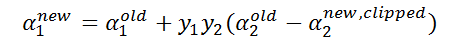
此时我们已经算出了a1和a2改变后的值,接下来需要求出b的值,因为算出b才能算出f(xi),进而求得误差Ei。当α1 new在0和C之间的时候,根据KKT条件可知,这个点是支持向量上的点。因此,满足下列公式:
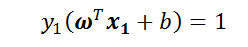
公式两边同时乘y1得:
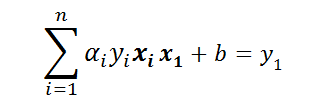
因为只有a1和a2有意义,所以提出它们,推出:
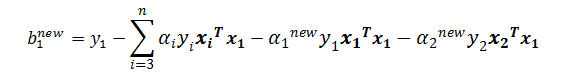
其中:
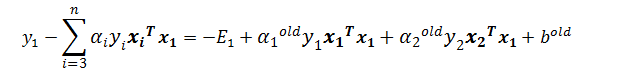
所以

同理:

当两个乘子都在边界上,则b阈值和KKT条件一致。当不满足的时候,SMO算法选择他们的中点作为新的阈值:
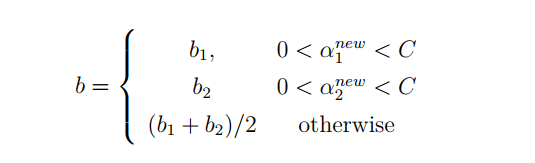
于是,我们就求得了更新后的a,b值,重复迭代一定次数后,即得结果。