网站:http://datamining.comratings.com/exam
如何抓取10个ip,这题很经典
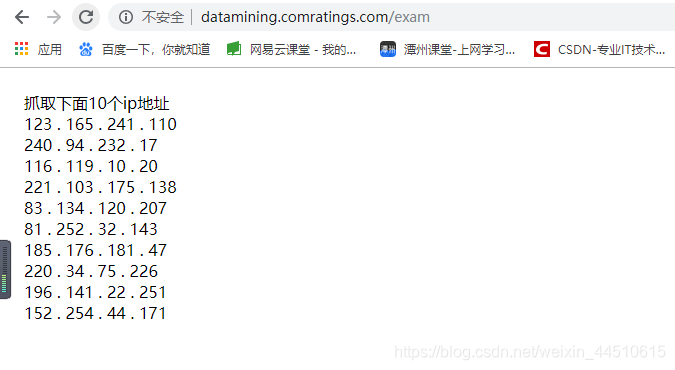
先查看网页源代码,啥也没有
<iframe src="/exam2" frameborder="no" width="750" height="500"></iframe>
看不懂就抓包
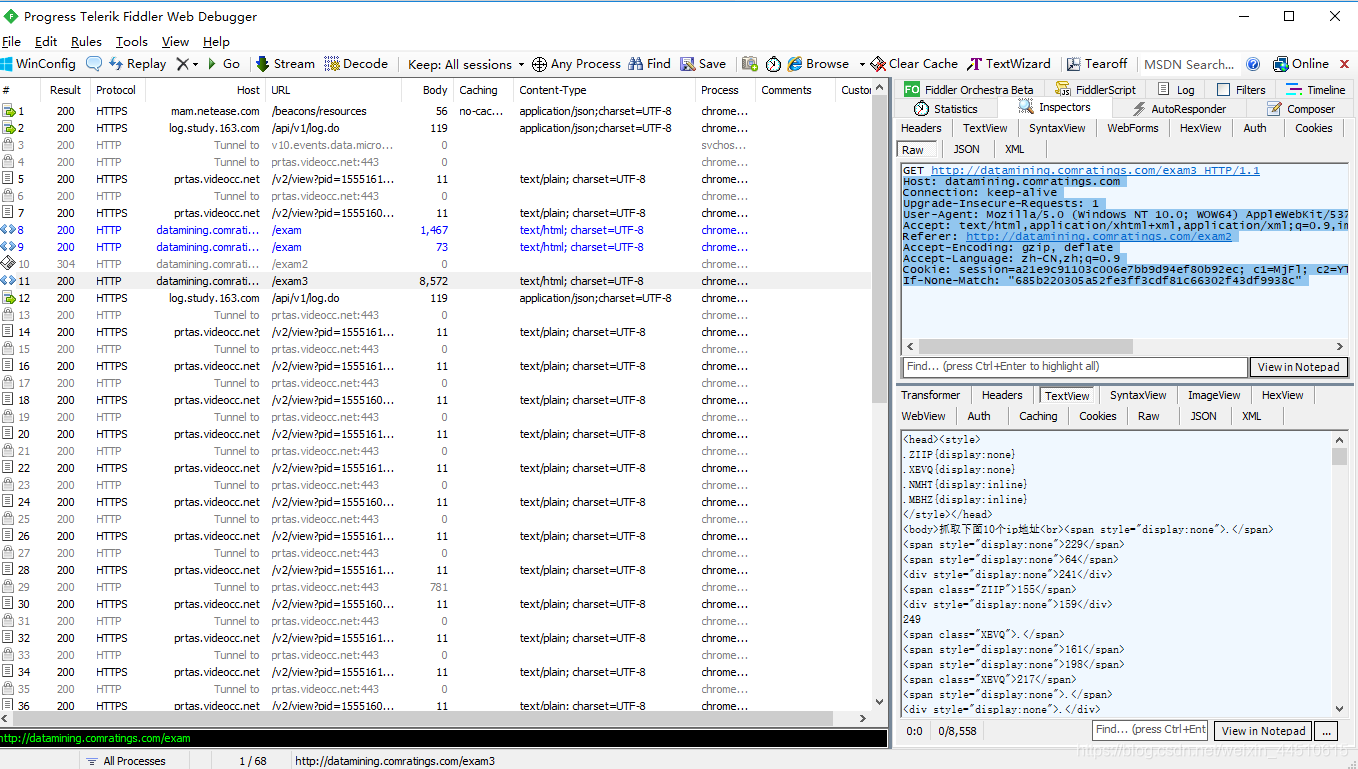
可以看到经过了3次请求,最后在http://datamining.comratings.com/exam3中得到数据,现在注意resquesr中的hearder传入的参数
那就先请求一次,第二次带上hearders

去掉hearders中的参数

有经验的人就知道cookie是重要参数

就是三个值而已,到底从哪里来的,摆明就是js生成的,那赶紧找第一次的js

复制js
http://tool.oschina.net/codeformat/js/ 这个网站js格式化挺好的

在控制台运行一下,就是放回一样的页面

之后下一次请求在抓包没有发现js,而且cookies已经生成

那就写个html 将上面js直接渲染,看看发生了啥?

果然不出我料,这个cookies生成的js终于找到了

格式化,将之前的js 替换

考验js功力到了

将这个js函数用python改写

·
将js中的变量复到python文件中,调用自己写的f1

测试,输出了c2的值

现在问题转成了这么解决cookie
这不就是考验我python能力吗
debug搞定


还要正则处理

再看下js,这个c1和c2怎么来的

不就是取前面几个切片,再调用f1函数

将参数传入,搞定

# -*- coding:utf-8 -*-
# time :2019/4/13 21:23
# author: 毛利
import re
import requests
encoderchars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
def f1(session_str):
len_str = len(session_str)
i = 0
b = ""
while i < len_str:
c = ord(session_str[i]) & 0xff
i +=1
if i == len_str:
b += encoderchars[c >> 2]
b += encoderchars[(c & 0x3) << 4]
b += "=="
break
c2 = ord(session_str[i])
i += 1
if i == len_str:
b += encoderchars[c >> 2]
b += encoderchars[((c & 0x3) << 4) | ((c2 & 0xf0) >> 4)]
b += encoderchars[(c2 & 0xf) << 2]
b += "="
break
c3 = ord(session_str[i])
i += 1
b += encoderchars[c >> 2]
b += encoderchars[((c & 0x3) << 4) | ((c2 & 0xf0) >> 4)]
b += encoderchars[((c2 & 0xf) << 2) | ((c3 & 0xc0) >> 6)]
b += encoderchars[c3 & 0x3f]
return b
if __name__ == '__main__':
session = requests.session()
r = session.get('http://datamining.comratings.com/exam')
session_str = re.findall(r'session=(.*?) for',str(r.cookies),re.S)
print(session_str)
if session_str:
c1 = f1(session_str[0][1:4])
c2 = f1(session_str[0])
print('c1:',c1,'c2:',c2)
headers = {
'Host': 'datamining.comratings.com',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Referer': 'http://datamining.comratings.com/exam',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie': 'session={}; c1={}; c2={}'.format(session_str[0],c1,c2), # session_str[0]要切片
}
print(session.get('http://datamining.comratings.com/exam3',headers=headers).text)
给下全代码,祝大家找到好爬虫工作